Problem
We are required to implement a full disaster recovery solution (application and database servers) using our Azure subscription. For the SQL Server database Disaster Recovery (DR) implementation, our infrastructure team has provided us a new Windows server cluster with two nodes on Azure using Infrastructure As A Service (IAAS) technology and we already have a Windows Server Failover Cluster (WSFC) with three nodes on-premises with one Availability Group and two replicas.
So how can we use this Azure WSFC as a DR replica for our current production database environment?
Solution
After checking all available solutions, I found the optimum solution for our needs which is using a feature in SQL Server 2016 called "Distributed Availability Groups" and fortunately we just upgraded our production to SQL Server 2016 SP1. Distributed Availability Groups is a different type of Availability Group that spans two Availability Groups which is ideal for what we need to do.
Let me first show what our local production environment looks like:
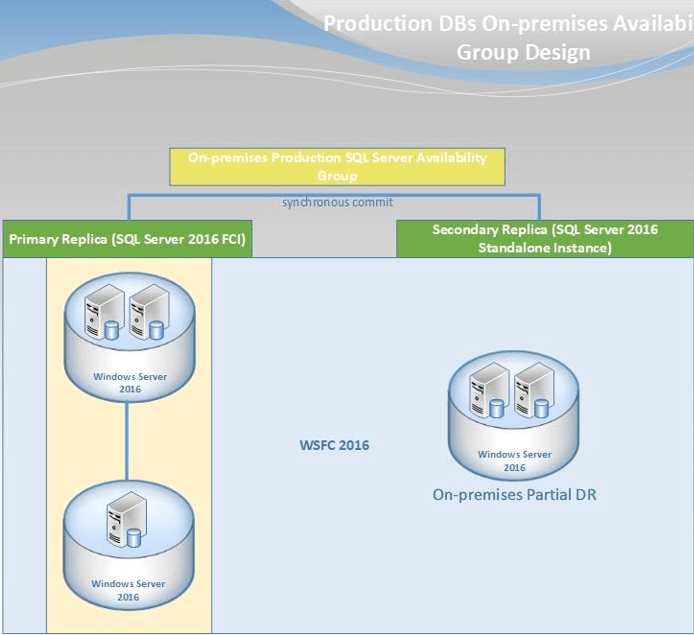
We have one Windows Server Failover Cluster containing three nodes. Two of them are used for one SQL Server failover cluster instance and this is the primary production replica. The third node acts as a partial DR instance which is the secondary replica of the production Availability Group.
I am using this design (FCIs + AGs) to ensure that the data is accessible despite any type of failure. In addition, as mentioned in the problem section above, we have a two-node Windows Server Failover Cluster in our Azure environment. One last thing to mention is that all of the infrastructure is using Windows Server 2016 Standard Edition.
Additional Benefits from Using Distributed Availability Groups
Full Disaster Recovery Site Deployment
The first solution that may come to mind is to use a multi-subnet AG listener deployment. However, as you may know, this solution has many known issues like Connection Timeouts in Multi-subnet Availability Groups. Besides, we need to implement it to another WSFC, which is not allowed for multi-subnet deployments. In addition, we have the advantage of another FCI instance at the DR site, which we could use if ever needed. The distributed AG gives us a chance to mitigate all of these obstacles.
Ready for Site Migration
Our company is planning to move to another building, so with this implementation we are now ready for that while ensuring the availability of all of our production databases by using the Azure environment during the migration process.
Running Current Application Services on Azure
We have some services that only read from databases on the production instances, so we gained the benefits of moving this read only activity to Azure, which offloads work from the production primary instance.
Considerations and Prerequisite Tasks
1 – You must be using domain accounts for SQL Server services.
2 – You may need to allow connect permission to the domain account used for the SQL Server services on all endpoints in the primary and secondary AGs. Using the below script:
--run this script on all nodes of primary and secondary AGs use [master] GO GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] TO [XXXXXXX\xxxxxxxxx_SVC] GO
3 – If you face error "An error occurred while receiving data: ‘10054 (An existing connection was forcibly closed by the remote host.)", you will need to create accounts for all servers’ names and grant them connect permission on all endpoints as shown in the above step to fix this issue. You can use the following script:
-- run this script on all nodes of primary and secondary AGs use [master] GO --to create an account for machine account CREATE LOGIN [XXXXXXX\xxxxxxxxx-SQL01$] FROM WINDOWS –-create one account for each machine involved --in both WSFC GO GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] TO [XXXXXXX\xxxxxxxxx-SQL01$] GO
4 – You must allow traffic from the firewall between all nodes on port 5022 "default endpoint port" and the port for SQL Server instances. Moreover, allow the traffic between VNNs or IPs on all SQL Server instances on port 5022 and the port of each SQL Server instance.
5 – Grant Full Permission for the SQL Service account on Folder (MachineKeys) under path (C:\Users\All Users\Microsoft\Crypto\RSA) on all Windows servers for fixing some SQL Server Kerberos issues with a manual failover.
6 – Grant create any database permission for each availability group on its replicas. You can use the following script on the primary and secondary replica of each AG:
-- grant the secondary AG the permission to create any database ALTER AVAILABILITY GROUP [AZURE_xxxxxxxxx_AG] GRANT CREATE ANY DATABASE
Implementation Steps and Notes
I will list all basic steps to create the distributed AG for our production environment.
First, let me show you the final design:

Proudly speaking, I would like to mention that this is the first implementation for distributed AG as a Hybrid cloud solution for HA & DR on production systems used in Saudi Arabia and the GULF area.
Create Azure SQL Server Availability Group with only one primary SQL Server Failover cluster instance
As mentioned, we have a WSFC on Azure with two nodes. I will install one SQL Server failover cluster instance on both nodes. Please review the below tips to help you with the installation:
- Step-by-step Installation of SQL Server 2016 on a Windows Server 2016 Failover Cluster – Part 3
- Step-by-step Installation of SQL Server 2016 on a Windows Server 2016 Failover Cluster – Part 4
Finally, the Azure FCI will have the below connection string:
xxxx-xx-xxx26\xxxxxxxDR02,1435
Then create the Availability Group with only one primary replica on the Azure FCI using the below script. In addition, you can follow this tip to create it using SSMS.
USE [master] GO CREATE AVAILABILITY GROUP [AZURE_xxxxxxxxx_AG] --change here your AG name WITH (AUTOMATED_BACKUP_PREFERENCE = SECONDARY, DB_FAILOVER = OFF, DTC_SUPPORT = NONE) FOR REPLICA ON N'xxxx-xx-xxx26\xxxxxxxDR02,1435' --put here your primary replica full connection string WITH (ENDPOINT_URL = N'TCP://xxxx-xx-xxx26.xxxxxxx.xxx.sa:5022', --put here the DNS record for your primary FCI FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, SESSION_TIMEOUT = 10, BACKUP_PRIORITY = 50, SEEDING_MODE = MANUAL, PRIMARY_ROLE(ALLOW_CONNECTIONS = ALL), SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL)); GO
Then I created an Availability group Listener using the below code:
USE [master] GO ALTER AVAILABILITY GROUP [AZURE_xxxxxxxxx_AG] --change here your AG name ADD LISTENER N' xxxx-xx-xxx27' --add here the DNS record for the AG listener (WITH IP ((N'00.00.00.00', N'255.255.255.0') --add here the IPV4 record registered for the AG listener ), PORT=1435); GO
Up to this point, we have the below definitions:
1 – Azure (Secondary AG) connection strings:
- WSFC Nodes: Az-xxxxx-xxx01 , Az-xxxxx-xxx02
- WSFC Name: xxxx-xx-xxx23
- Primary FCI replica : xxxx-xx-xxx26\xxxxxxxDR02,1435
- AG name: AZURE_xxxxxxxxx_AG
- Full AG listener connection string: xxxx-xx-xxx27\ AZURE_xxxxxxxxx_AG,1435
2 – On-premises (primary AG) connection strings:
- WSFC Nodes: xxxx-xx-xx06 , xxxx-xx-xx07 , xxxx-xx-xx08
- WSFC Name: xxxx-xx-xxx10
- Primary FCI replica: xxxx-xx-xxx11\xxxxxxx01,1431
- Secondary standalone replica: xxxx-xx-xx08\xxxxxxx01DR,1431
- AG name: xxxxxxx01_AG
- Full AG listener connection string: xxxx-xx-xxx13\xxxxxxx01_AG,1431
Therefore, we have a successfully configured two separate SQL Server AlwaysON Availability Groups.
Now let us start creating the distributed Availability Groups
Create SQL Server Distributed Availability Group
After you had both AGs up and running in a healthy state, the upcoming configurations are easy. Create the Distributed Availability Group on the primary Availability Group using the following script:
CREATE AVAILABILITY GROUP [Distributed_AG] --Create Distributed Availability Group --Run this on the primary replica of the primary Availability Group WITH (DISTRIBUTED) AVAILABILITY GROUP ON 'xxxxxxx01_AG' WITH ( LISTENER_URL = 'TCP://xxxx-xx-xxx11.xxxxxxx.xxx.sa:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = MANUAL ), 'AZURE_xxxxxxxxx_AG' WITH ( LISTENER_URL = 'TCP://xxxx-xx-xxx26.xxxxxxx.xxx.sa:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = MANUAL ); GO
Important things to note in the above script:
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT
- This setting is configured so it will not negatively affect network traffic or bandwidth between the local and Azure servers. Whenever needed (maybe while performing a manual failover), I will configure it to SYNCHRONOUS_COMMIT.
FAILOVER_MODE = MANUAL
- This is because automatic failover is not supported while using FCI instances, as mentioned by Microsoft here.
SEEDING_MODE = MANUAL
- Because the automatic seeding mode in SQL Server 2016 requires the drive letters for .mdf and .ldf files to be the same on all nodes as mentioned by Microsoft here and this is not my case.
The listener for each AG replica uses the VNN of the FCI not the VNN of the AG’s listener
- When creating a Distributed AG using AGs on FCIs, there is not a need for an AG listener. You must use the Virtual Network Name (VNN) of the primary replica of the FCI instance as outlined by Microsoft here.
Join the secondary Availability Group to the Distributed Availability Group using the following script:
--Create distributed availability group on second failover cluster with replicas and listener --Run this on the primary replica of the secondary Availability Group ALTER AVAILABILITY GROUP [Distributed_AG] JOIN AVAILABILITY GROUP ON 'xxxxxxx01_AG' WITH ( LISTENER_URL = 'TCP://xxxx-xx-xxx11.xxxxxxx.xxx.sa:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = MANUAL ), 'AZURE_xxxxxxxxx_AG' WITH ( LISTENER_URL = 'TCP://xxxx-xx-xxx26.xxxxxxx.xxx.sa:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = MANUAL ); GO
At this time, you can see the distributed AG name in SSMS while connecting to one of the instances. Expand the Availability Groups section as shown below.
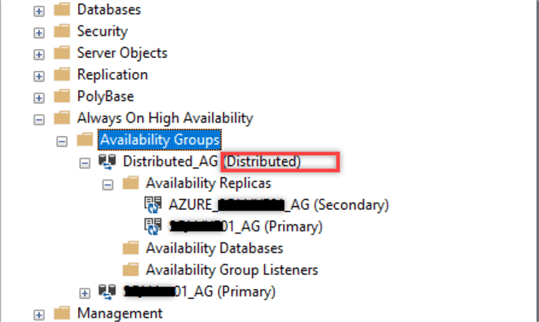
As you can see, you will not find any databases in the Availability Databases folder even after adding databases to the distributed AG. In addition, you cannot find any Availability Group Listeners because it does not have any listeners, which means that you cannot connect to it as an instance.
Other questions that may come up are:
- How can I monitor the status of the Distributed AG?
- How to add databases to the Distributed AG?
- How to test manual failover of the Distributed AG?
I will answer these questions and give you some troubleshooting techniques for common issues I faced in the second part of this tip.
Next Steps
- Check this great enhancement for Configure a Dedicated Network Adapter for SQL Server Always On Distributed Availability Groups Data Replication Traffic
- Check that awesome tip from Edwin M Sarmiento Setup and Implement SQL Server 2016 Always On Distributed Availability Groups, which helped me a lot in my implementation.
- Setup and Implement SQL Server 2016 Always On Basic Availability Groups
- Adding SQL Server AlwaysOn Availability Groups to existing Failover Clusters
- Check the official documentation of distributed AG from Microsoft:

As a certified Microsoft SQL Server Database Administrator (MCP, MCSA, MCSE, and MCT) with a Bachelor’s degree in computer science and hands-on experience overseeing the design, development, and maintenance of various database systems (For more information check here.), working as Senior SQL server consultant for more than 10 customers (private, government and semi-government sectors) at Saudi Arabia.
I enjoy solving large, complex data problems enjoy the process of building and determining a solution. I am able to quickly identify new resolutions that will not only help solve major business problems but also ensure that the business maintains local, federal and business sector compliance given my extensive research abilities and deep industry knowledge.
