Problem
In a previous tip on Installing SQL Server vNext CTP1 on Red Hat Linux 7.2, we have read about how we can now install SQL Server 2017 on a Linux operating system. We would like to evaluate running SQL Server 2017 Availability Groups on Linux. How do we go about building the Linux environment for SQL Server 2017 Availability Groups?
Solution
To continue this series on Step-by-step Installation and Configuration of SQL Server 2017 Availability Groups on a Linux Cluster, we will look at configuring Pacemaker on Linux to provide high availability for the SQL Server 2017 Always On Availability Group. In Part 3, you have learned how to create the Always On Availability Group with its corresponding listener name. This tip will walk you through the installation and configuration of Pacemaker, the Linux cluster resource manager.
Introducing Pacemaker on Linux
On a Windows Server operating system, it is the Windows Server Failover Cluster (WSFC) that provides high availability, failure detection and automatic failover to the SQL Server Always On Availability Group. WSFC is an example of a cluster resource manager (CRM), a software that runs on all of the nodes in the cluster responsible for maintaining a consistent image of the cluster. The goal of a cluster resource manager is to provide high availability and fault tolerance to resources running on top of the cluster.
On a Linux operating system, the de facto cluster resource manager is the open source software Pacemaker. Its development is a collaborative effort driven mainly by RedHat and SUSE under the ClusterLabs organization with contributions from the community. Pacemaker is available on most Linux distributions but SQL Server Always On Availability Groups is only currently supported on Red Hat Enterprise Linux version 7.3/7.4, SUSE Linux Enterprise Server version 12 SP2 and Ubuntu version 16.04.
The Pacemaker stack consists of the following components:
- The Pacemaker software itself which is similar to the Cluster service on Windows
- Corosync, a group communication system similar to the heartbeat and quorum on Windows (don’t get confused with Heartbeat, which is a Linux daemon that functions similar to Corosync); it is also responsible for restarting failed application process
- libQB, a high-performance logging, tracing, inter-process communication and polling system similar to how the cluster.log is generated on Windows
- Resource Agents, software that allows Pacemaker to manage services and resources like starting or stopping a SQL Server Always On Availability Group resource like the cluster resource DLL on Windows
- Fence Agents, software that allows Pacemaker to isolate and prevent misbehaving nodes from affecting the availability of the cluster
An understanding of these different components is essential to properly configure and manage Pacemaker on Linux.
How to Install and Configure Pacemaker on Linux
Installing and configuring Pacemaker on Linux isn’t as easy as configuring a WSFC. Here’s a high-level overview of the steps for your reference. Be very careful with going thru all of the steps.
- Install the Pacemaker packages
- Start the pcs daemon and force it to start on system boot
- Configure the Linux firewall to allow Pacemaker communications
- Force the Pacemaker and Corosync daemons to start on system boot
- Assign a password to the default hacluster account
- Setup authentication between the Linux cluster nodes
- Create the Linux cluster
- Start the Linux cluster
- Configure fencing
- Configure resource-level policies
- Create a SQL Server login for Pacemaker
- Save credentials for the Pacemaker login on the local file system
Some of these steps have to be done on either one or all of the Linux servers. Read the NOTE section on every step before running the commands.
Step #1: Install the Pacemaker packages
NOTE: Perform this step on all of the Linux servers. Remember to log in with super user (root) privileges when performing these steps.
Run the command below to install Pacemaker and all of the related packages. This is similar to installing the Failover Clustering feature in Windows.
sudo yum install pacemaker pcs fence-agents-all resource-agents
If you look at the packages being installed, they refer to the different components that make up the Pacemaker stack.
- pcs = Pacemaker Configuration System, the Pacemaker and Corosync configuration tool
- fence-agents-all = a collection of all supported fence agents
- resource-agents = a repository of all resource agents (RAs) compliant with the Open Cluster Framework (OCF) specification
Note the existence of the SQL Server resource agent that was installed in Part 2.

Type y when prompted to download the packages, including the Linux security signing key.

Step #2: Start the pcs daemon and force it to start on system boot
NOTE: Perform this step on all of the Linux servers. Remember to log in with super user (root) privileges when performing these steps.
Run the commands below to start the pcs daemon and force it to launch on system boot.
sudo systemctl start pcsd sudo systemctl enable pcsd

Step #3: Configure the Linux firewall to allow Pacemaker communications
NOTE: Perform this step on all of the Linux servers. Remember to log in with super user (root) privileges when performing these steps.
Run the command below to allow Pacemaker communications between cluster nodes. By default, FirewallD is the firewall solution available on RHEL/CentOS.
sudo firewall-cmd --add-service=high-availability --zone=public --permanent

In cases where the Linux firewall does not have a built-in high availability configuration, you can explicitly open the following port numbers:
- TCP port 2224 = for pcs and internode communication
- TCP port 3121 = for running Pacemaker Remote, used for scaling out Pacemaker and having the different components run on different servers
- UDP port 5405 = for Corosync
sudo firewall-cmd --zone=public --add-port=2224/tcp --permanent sudo firewall-cmd --zone=public --add-port=3121/tcp –permanent sudo firewall-cmd --zone=public --add-port=5405/udp --permanent
Run the command below to reload the new firewall rule added
sudo firewall-cmd --reload

Step #4: Force the Pacemaker and Corosync daemons to start on system boot
NOTE: Perform this step on all of the Linux servers. Remember to log in with super user (root) privileges when performing these steps.
Run the commands below to force the Pacemaker and Corosync daemons to start on system boot.
sudo systemctl enable pacemaker.service sudo systemctl enable corosync.service

Step #5: Assign a password to the default hacluster account
NOTE: Perform this step on all of the Linux servers. Remember to log in with super user (root) privileges when performing these steps.
Run the command below to assign a password to the default hacluster account. Use the same password on all cluster nodes.
sudo passwd hacluster

By default, a new user account named hacluster is created when Pacemaker is installed. This account is used to manage the Linux cluster. Since there is no centralized directory service for authentication, this user account is created on all nodes and used to impersonate the security context of the administrator managing the Linux cluster. Hence, the hacluster account needs to have the same password on all of the cluster nodes.
Step #6: Setup authentication between the Linux cluster nodes
NOTE: Perform this step on ANY of the Linux servers. You don’t need to run it on all nodes. Remember to log in with super user (root) privileges when performing these steps. This example uses linuxha-sqlag1 to run the command.
Run the command below to authenticate thru each of the Linux cluster nodes using the hacluster user. You will be prompted for the password for the hacluster user.
sudo pcs cluster auth linuxha-sqlag1.testdomain.com linuxha-sqlag2.testdomain.com linuxha-sqlag3.testdomain.com -u hacluster

Step #7: Create the Linux cluster
NOTE: Perform this step on ANY of the Linux servers. You don’t need to run it on all nodes. Remember to log in with super user (root) privileges when performing these steps. This example uses linuxha-sqlag1 to run the command.
Run the command below to create the Linux cluster. LINUXHACLUS is the name of the Linux cluster with linuxha-sqlag1, linuxha-sqlag2 and linuxha-sqlag3 as nodes.
sudo pcs cluster setup --name LINUXHACLUS linuxha-sqlag1.testdomain.com linuxha-sqlag2.testdomain.com linuxha-sqlag3.testdomain.com

Step #8: Start the Linux cluster
NOTE: Perform this step on ANY of the Linux servers. You don’t need to run it on all nodes. Remember to log in with super user (root) privileges when performing these steps. This example uses linuxha-sqlag1 to run the command.
Run the command below to start the cluster service on all nodes.
sudo pcs cluster start --all

Step #9: Configure fencing
NOTE: Perform this step on all of the Linux servers. Remember to log in with super user (root) privileges when performing these steps.
Fencing is the process of isolating and preventing a misbehaving node from affecting the availability of the cluster. It is similar to how Quarantine works in Windows Server 2016 failover clusters (the concept of fencing has been in Windows since Windows Server 2003 thru the implementation of quorum types but have been improved with the introduction of Quarantine). In a cluster that has a shared resource, like a shared disk, fencing prevents the misbehaving node from accessing it to avoid potential data corruption. This allows the cluster to be in a clean, known state.
The way fencing is implemented in Pacemaker is thru STONITH – an acronym for “Shoot The Other Node In The Head”. There are different STONITH devices and plugins that can be used to implement fencing, depending on your environment. You can use a smart power distribution unit (PDU), a network switch, HP iLO devices or even plugins like a VMWare STONITH agent. At the moment, there is no supported STONITH agent for Hyper-V nor Microsoft Azure (or any cloud environment). For this example, since no STONITH device is used, it will be disabled.
NOTE: This is not recommended in a production environment. Properly configure a STONITH device and keep it enabled.
Run the command below to disable STONITH.
sudo pcs property set stonith-enabled=false

Step #10: Configure resource-level policies
NOTE: Perform this step on all of the Linux servers. Remember to log in with super user (root) privileges when performing these steps.
In a WSFC, the way the cluster manages a resource depends on how it is configured. Take a look at the screenshot below which is a property of a SQL Server Always On Availability Group running on a WSFC.

The Response to resource failure section of the Policies tab specifies that if a resource fails, the cluster will attempt to restart it once (defined by the Maximum restarts in the specified period field) on the current node first within a period of 15 minutes. If the restart is unsuccessful, the cluster will failover the resource to any of the available cluster nodes.
Pacemaker has a similar property called start-failure-is-fatal. If a resource fails, Pacemaker will attempt to stop it and restart it, choosing the best location each time and can be the same node that it was previously running on. This behavior is determined by the migration-threshold (similar to the Maximum restarts in the specified period field) and the failure-timeout parameters. When the start-failure-is-fatalparameter value is set to false, the cluster will decide whether to try starting on the same node again based on the resource's current failure count and migration threshold.
Run the command below to set the cluster property start-failure-is-fatal to false.
sudo pcs property set start-failure-is-fatal=false

Step #11: Create a SQL Server login for Pacemaker
NOTE: Perform this step on all of the SQL Server instances configured as replicas in the Always On Availability Group.
Similar to WSFC, Pacemaker will be responsible for performing automatic failover of the SQL Server Always On Availability Group. This is done thru the Linux cluster resource agent for SQL Server Always On Availability Groups – mssql-server-ha. In order for Pacemaker to perform automatic failover, it needs to be able to connect to SQL Server via a login.
Run the script below to create the SQL Server login named pacemakerLogin.
--Run this on the primary replica/LINUXHA-SQLAG1. Just to be sure, enable SQLCMD mode in SSMS
--Pass the SQL Server credentials since this is configured for mixed mode authentication
:CONNECT LINUXHA-SQLAG1 -U sa -P y0ur$ecUr3PAssw0rd
USE master
GO
CREATE LOGIN pacemakerLogin
WITH PASSWORD = 'y0ur$ecUr3PAssw0rd';
GO
You also need to grant the SQL Server login the appropriate permissions to manage the Always on Availability Group, like running the ALTER AVAILABILITY GROUP command to initiate a failover.
NOTE:Be sure to replace LINUX_SQLAG with the name of your Always On Availability Group.
--Run this on the primary replica/LINUXHA-SQLAG1. Just to be sure, enable SQLCMD mode in SSMS
--Pass the SQL Server credentials since this is configured for mixed mode authentication
:CONNECT LINUXHA-SQLAG1 -U sa -P y0ur$ecUr3PAssw0rd
USE master
GO
GRANT ALTER, CONTROL, VIEW DEFINITION ON AVAILABILITY GROUP::LINUX_SQLAG TO pacemakerLogin
GO
GRANT VIEW SERVER STATE TO pacemakerLogin
GO
Create the same login on all of the Availability Group replicas.
--Run this on the secondary replica/LINUXHA-SQLAG2. Just to be sure, enable SQLCMD mode in SSMS
--Pass the SQL Server credentials since this is configured for mixed mode authentication
:CONNECT LINUXHA-SQLAG2 -U sa -P y0ur$ecUr3PAssw0rd
USE master
GO
CREATE LOGIN pacemakerLogin
WITH PASSWORD = 'y0ur$ecUr3PAssw0rd';
GO
GRANT ALTER, CONTROL, VIEW DEFINITION ON AVAILABILITY GROUP::LINUX_SQLAG TO pacemakerLogin
GO
GRANT VIEW SERVER STATE TO pacemakerLogin
GO
--Run this on the secondary replica/LINUXHA-SQLAG3. Just to be sure, enable SQLCMD mode in SSMS
--Pass the SQL Server credentials since this is configured for mixed mode authentication
:CONNECT LINUXHA-SQLAG3 -U sa -P y0ur$ecUr3PAssw0rd
USE master
GO
CREATE LOGIN pacemakerLogin
WITH PASSWORD = 'y0ur$ecUr3PAssw0rd';
GO
GRANT ALTER, CONTROL, VIEW DEFINITION ON AVAILABILITY GROUP::LINUX_SQLAG TO pacemakerLogin
GO
GRANT VIEW SERVER STATE TO pacemakerLogin
GO
Step #12: Save credentials for the Pacemaker login on the local file system
NOTE: Perform this step on all of the Linux servers. Remember to log in with super user (root) privileges when performing these steps.
Pacemaker will use the SQL Server login – pacemakerLogin – to connect to the SQL Server instances configured as Availability Group replicas. In order to remember the login name and password, the credentials need to be stored in a file. You need to create a file named passwd in the /var/opt/mssql/secrets folder
Run the command below to create the file named passwd using the vi command.
sudo vi /var/opt/mssql/secrets/passwd

Type the login name and password on the file and save it.
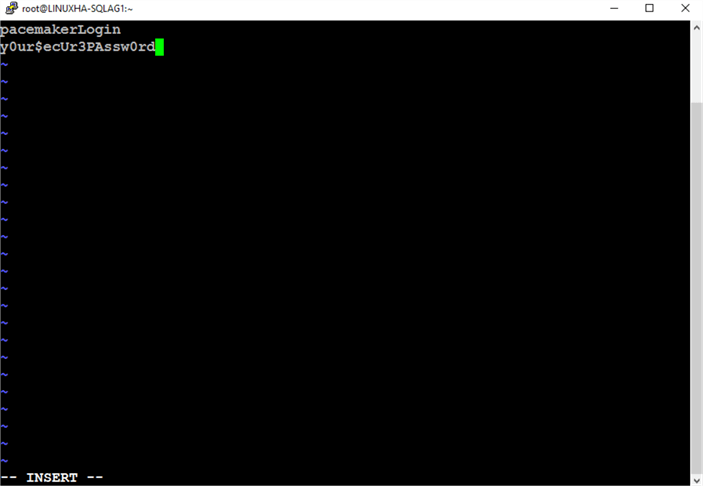
Since you are logged in as root when you created the file, it will be owned by the root user. You can verify this by running the command below.
sudo ls -l /var/opt/mssql/secrets

Run the command below to restrict access to the file by only allowing the file owner (root) read-only permissions.
sudo chmod 400 /var/opt/mssql/secrets/passwd

Repeat this step to make sure that the passwd file exists on all of the nodes in the Linux cluster.
All you’ve done up to this point is to install and configure Pacemaker in preparation for configuring SQL Server Always On Availability Group to run on top of the cluster. Run the command below to check the status of the cluster.
sudo pcs status --full

Notice that even though the Pacemaker and Corosync daemons have been configured to start on system boot in Step #4, they are still marked as disabled. This was done after the cluster has been created. The reason for this is that not all administrators would want to enable the cluster to start up on reboot. For example, if the node went down, you might want to be sure that it was fixed before re-joining the cluster. If you want to force the Pacemaker and Corosync daemons to start on system boot, you need to perform Step #4 after the SQL Server Always On Availability Group has been added as a resource on the cluster.
In the next tip in this series, you will configure the SQL Server 2017 Always On Availability Group and the virtual IP address of the listener name as resources in the cluster.
Next Steps
- Review the previous tips on SQL Server on Linux
- Read more on the following topics

Edwin M. Sarmiento is the Managing Director of 15C, a consulting and training company that specializes on designing, implementing and supporting SQL Server infrastructures. He is a Microsoft SQL Server MVP and Microsoft Certified Master from Ottawa, Canada specializing in high availability, disaster recovery and system infrastructures running on the Microsoft server technology stack ranging from Active Directory to SharePoint and anything in between. He is very passionate about technology but has interests in music, professional and organizational development, and leadership and management matters when not working with databases. Edwin lives up to his primary mission statement: “To help people and organizations grow and develop their full potential.”
- MSSQLTips Awards: Champion Award (100+ tips) – 2017 | Author of the Year Contender – 2020, 2017
