Problem
I often see users performing a UNION or UNION ALL between two tables where the corresponding column data types don’t match. An implicit conversion appears in the execution plan, and they worry about the performance implication of the conversion first. There is something far more sinister lurking in the details, but this is not made very obvious in the native tools.
Solution
When SQL Server Management Studio shows an execution plan, it shows the estimated costs by I/O and CPU combined, and it shows the line widths between operators by row size alone. Sometimes an operator is very I/O-heavy, but it can be balanced by another operator that is very CPU-heavy. Since most SQL Server systems, even in 2018, are I/O-bound, this can hide problems. Similarly, the number of rows is not always directly indicative of a lot of data moving – think about cases like a million 3-byte dates vs. ten 300kb chunks of XML. While 10 rows might look like a lot less data than a hundred thousand rows, how much data is represented in each row is important too.
So, sometimes, it pays to look into the details beyond what SSMS will show you. Unfortunately, SQL Server will often get its guesses wrong, too. For example, for every row, an XML column is assumed to have 4KB of data. For a lot of queries, this estimate is not an extremely relevant piece of information, so being accurate is typically not overly harmful. But if you’re dealing with a very I/O-intensive workload, or are very network-constrained, you might find that queries take longer than you’d expect. And if you have queries with operations that require memory – such as sorting – your memory grants will end up being a lot larger than you typically need.
Impact of mismatched data types in UNION
An example I’ll pull from a recent Q & A question is someone who was performing a union between a varchar(10) column and a varchar(max) column. As I mentioned above, they were concerned that while the query worked fine in their own environment, it might cause some performance pain at scale. It will, but not in the way the user thought.
Let’s set up two simple tables, and we’ll populate them with the same number of rows (10,000) and the exact same data (every value is <= 10 characters):
CREATE TABLE dbo.t1 (i int IDENTITY(1,1) PRIMARY KEY, c1 varchar(10) );<br />CREATE TABLE dbo.t2 (i int IDENTITY(1,1) PRIMARY KEY, c1 varchar(max));<br />GO
INSERT dbo.t1(c1) SELECT TOP (1000) LEFT(name,10) FROM sys.all_columns ORDER BY name;<br />INSERT dbo.t2(c1) SELECT TOP (1000) LEFT(name,10) FROM sys.all_columns ORDER BY name;<br />GO 10
Now, if we run a query against t1, another against t2, and then a union all against both:
SELECT i, c1 FROM dbo.t1;<br /><br />SELECT i, c1 FROM dbo.t2;<br /><br />SELECT i, c1 FROM dbo.t1<br />UNION ALL<br />SELECT i, c1 FROM dbo.t2;
Here is what SSMS shows:

On first glance, it looks like the scans of both tables are equivalent in terms of cost, if you are to believe the relative, estimated cost percentage attributed to each plan. Note that the arrows between the operators are the same size as well, so there is no real visual clue that anything is different between t1 and t2. If we look closer, namely the tooltips over the arrows, we see that there is a major difference:

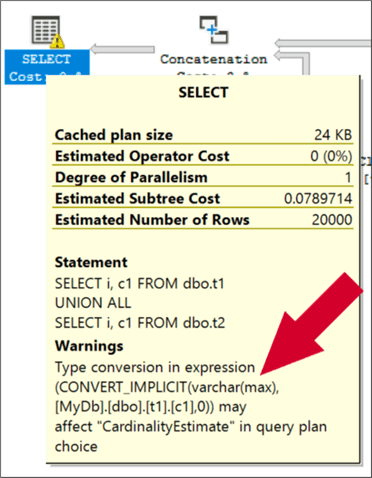
Because of the declared size of the columns, not the data that’s actually in the table, SQL Server has to estimate that the columns are populated by 50% on average, which leads to the average row size being calculated at ~4kb for t2. Why 4kb? Varchar(max) is treated the same as varchar(8000).
Further to that, when you perform a UNION between the tables (or a join or other operations too), the smaller column must be made compatible with the larger column, so you get an implicit conversion of the varchar(10) column up to varchar(max), for every row in the table with the smaller column. This is exposed in the execution plan as a Compute Scalar, which a lot of people tend to ignore.
To us humans, this conversion doesn’t seem logical, since no value from t1 could ever possibly be larger than ten characters. So, it makes even less sense to guess that every value must be 4kb. Here’s the warning that makes people nervous:
In SentryOne Plan Explorer, if you look at the same plans by default, they look a lot like the execution plans in SSMS:

However, if you change the metric used to render line widths of the arrows from Rows to Data Size (MB), you get a much more obvious visual indication that something else is going on:

In this simple case, the mismatch is not really a big deal and, other than changing the table structure, there’s not much we can do about it anyway. These are only estimated data size numbers, after all; we know our table only contains rows that contain 10 characters, so we shouldn’t be panicking about the amount of data that is coming across the wire.
As I said, though, there’s something more dangerous lurking behind here, so I’m not going to focus so much on the conversion itself or the amount of actual data we need to be worried about.
Let’s think about what has to happen when you introduce an operation to the UNION execution plan that requires memory, such as a sort. We can change the query to have an ORDER BY:
SELECT i, c1 FROM dbo.t1<br />UNION ALL<br />SELECT i, c1 FROM dbo.t2<br />ORDER BY c1;
The execution plan now looks like this:
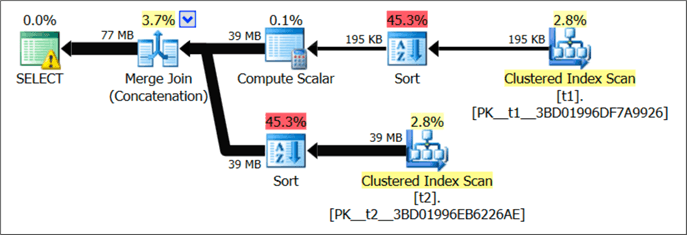
But the tooltip has some additional information that should make us worried:
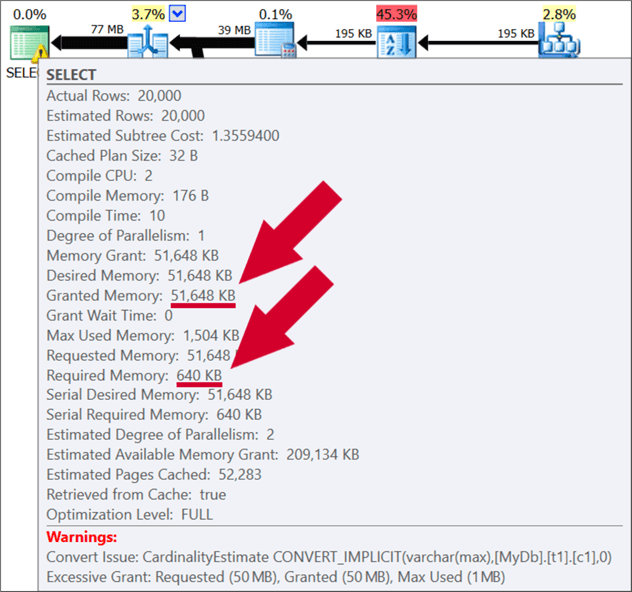
We have an additional warning about an excessive memory grant, and we see in the details that the granted memory was over 50 MB when we really didn’t end up using more than 1.5 MB. Again, in and of itself, and on an otherwise idle machine, this doesn’t cause any issue. What you should worry about is when 20, or 150, or 999 concurrent users are running queries with similarly exaggerated memory grants.
The solution in this case would be to make the t2 column not varchar(max) if it doesn’t have to be, or if it needs to support more than 10 characters but less than 8000, something reasonable in between that will lead to more realistic data size estimates (and hence more reasonable memory grants).
The moral of the story is that, when you see an implicit conversion, you should dig deeper in case it is hiding something like this.
Next Steps
Read on for related tips and other resources:
- Convert Implicit and the related performance issues with SQL Server
- Concatenation of Different SQL Server Data Types
- SQL Server performance issues when using mismatched data types
- How to read SQL Server graphical query execution plans
- More intuitive tool for reading SQL Server execution plans

Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He also blogs at sqlblog.org.
- MSSQLTips Awards: Author of the Year – 2016, 2023 | Leadership (200+ tips) – 2022