Problem
In my previous tip, I showed one method of making bulk loading from different sources more efficient. By introducing staging tables and not changing much else, we were able to shave off 33% of runtime from a set of bulk operations, and reduce other resource drain as well. The problem is that contention just moved from the main table to the staging tables. How can we further reduce contention, while still avoiding expensive hardware changes or a bump to Enterprise Edition?
Solution
Recall that we implemented a process where we shifted a bulk insert to multiple, independent staging tables, and added a single background process to move those into the main (large) table:

That diagram intentionally left out the new location of contention: on each of the staging tables. I made the example simple, by running a bulk insert into each staging table, then after that was done, running the background process to sweep the new data into the main table. On a busy system, you don’t have that luxury; if those web servers tried to bulk insert while that background process is running, they would still get blocked. They’d be blocked for a shorter period, since any one web server would only have to wait for the processing of its own staging table, but we’d still like to eliminate as much of that locking and blocking as possible.
My implementation went on to create a second copy of the staging tables, which I’ll call "ready." A web server would bulk insert to the staging table. When the background process woke up, it would perform a metadata operation (schema transfer in my case, but sp_rename is also valid), transfer the new data into the ready table, and replace the staging table with an empty copy. This reduces contention since the metadata operation is super fast – so while the background process would have to wait for a bulk insert to finish, once it performed its operation, it would only be schema locking the staging table for a very short time, without anything being dependent on size-of-data. A diagram to illustrate:
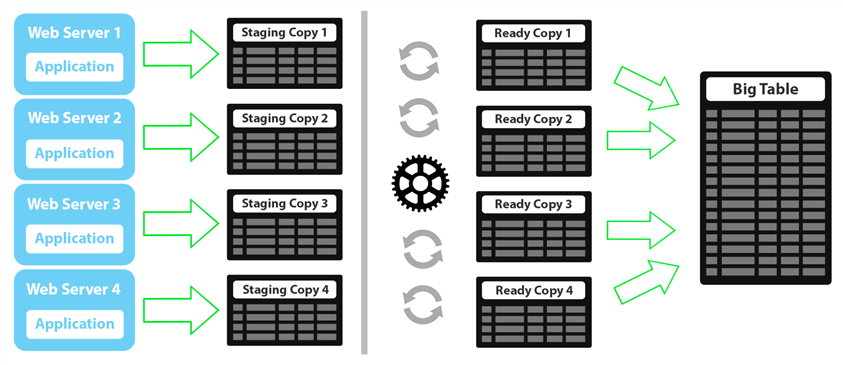
For a long time, I had been a proponent of implementing this shell game with what I call a "schema switch-a-roo" where you have a dummy schema and a standby schema. When it’s time to switch things out, you move the production table into the dummy schema, move the standby object to the production schema, and then move the former production table to standby. I thought I would revisit this approach when Kendra Little wrote an absolutely fantastic article on partition switch – she describes some very real risks with sp_rename and also some problems with my switch-a-roo process, and recommends partition switching instead.
And you’re probably thinking, well, partitioning is an Enterprise Edition feature, so I can’t use it, right? Well, partitioning is supported on SQL Server 2016 SP1 and above, on all editions, though lower editions will not take full advantage performance-wise. Thankfully, partition switching in and of itself is supported on SQL Server 2014 and up, on all editions, and doesn’t require any actual partition schema and function configuration. As Kendra points out, every table has one partition by default.
How does it work?
We need to start by creating new, empty copies of each staging table (changing DumpsterCopyX to DumpsterStagingX here; for the original schema, see part 1). In order to use partition switch, the schema must match, so let’s do:
SELECT TOP 0 a,b,c,d,e,f,g,h,i,j INTO dbo.DumpsterStaging1 FROM dbo.DumpsterTable;
SELECT TOP 0 a,b,c,d,e,f,g,h,i,j INTO dbo.DumpsterStaging2 FROM dbo.DumpsterStaging1;
SELECT TOP 0 a,b,c,d,e,f,g,h,i,j INTO dbo.DumpsterStaging3 FROM dbo.DumpsterStaging1;
SELECT TOP 0 a,b,c,d,e,f,g,h,i,j INTO dbo.DumpsterStaging4 FROM dbo.DumpsterStaging1; SELECT TOP 0 a,b,c,d,e,f,g,h,i,j INTO dbo.DumpsterReady1 FROM dbo.DumpsterStaging1;
SELECT TOP 0 a,b,c,d,e,f,g,h,i,j INTO dbo.DumpsterReady2 FROM dbo.DumpsterStaging1;
SELECT TOP 0 a,b,c,d,e,f,g,h,i,j INTO dbo.DumpsterReady3 FROM dbo.DumpsterStaging1;
SELECT TOP 0 a,b,c,d,e,f,g,h,i,j INTO dbo.DumpsterReady4 FROM dbo.DumpsterStaging1; SELECT TOP 0 a,b,c,d,e,f,g,h,i,j INTO dbo.DumpsterStandby1 FROM dbo.DumpsterStaging1;
SELECT TOP 0 a,b,c,d,e,f,g,h,i,j INTO dbo.DumpsterStandby2 FROM dbo.DumpsterStaging1;
SELECT TOP 0 a,b,c,d,e,f,g,h,i,j INTO dbo.DumpsterStandby3 FROM dbo.DumpsterStaging1;
SELECT TOP 0 a,b,c,d,e,f,g,h,i,j INTO dbo.DumpsterStandby4 FROM dbo.DumpsterStaging1;
The web servers will continue to bulk insert into the staging tables as they have (just update the procedure to the new table name pattern). The background process will:
- switch StagingX into ReadyX
- switch StandbyX into StagingX
- now the web servers can bulk insert into staging again
- process ReadyX
- truncate ReadyX and switch back into StandbyX
If you want to keep the staging data around just in case something goes wrong in the meantime., you may want to wait to perform step 4 until the beginning of the next time the process runs.
We’re going to use WAIT AT LOW PRIORITY so the background process doesn’t interfere (details on how this works and an additional article by Joe Sack here). We can set it to only wait for a certain amount of time, then decide what we want to do when that threshold is reached. We can either give up and retry again on next execution, or we can kill off all the blockers. I would say the former is preferential, so it’s what I’ve used here, but your choice depends on whether you value getting that bulk data loaded into the main table over all other activity.
CREATE PROCEDURE dbo.DumpsterBackgroundProcess
AS
BEGIN
SET NOCOUNT ON; BEGIN TRANSACTION; -- switch Staging1 to Ready1: ALTER TABLE dbo.DumpsterStaging1 SWITCH TO dbo.DumpsterReady1
WITH (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 5 MINUTES, ABORT_AFTER_WAIT = SELF)); -- switch Standby1 to Staging1: ALTER TABLE dbo.DumpsterStandby1 SWITCH TO dbo.DumpsterStaging1;
COMMIT TRANSACTION;
-- bulk insert can now resume on Standby1
-- process Ready1: INSERT dbo.DumpsterTable(a,b,c,d,e,f,g,h,i,j)
SELECT a,b,c,d,e,f,g,h,i,j FROM dbo.DumpsterReady1;
-- truncate Ready1 and switch back into Standby1: TRUNCATE TABLE dbo.DumpsterReady1;
ALTER TABLE dbo.DumpsterReady1 SWITCH TO dbo.DumpsterStandby1; -- repeat for 2, 3, 4 -- if you have a LOT of threads, just use dynamic SQL
END
GO
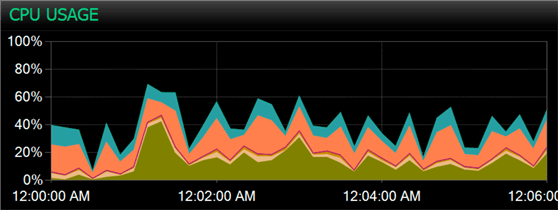
To test this out, I set all five jobs to run every 15 seconds, with the background process on a 5-second offset, and let them run for 6 minutes. This ensures that things run at the same time, and any concurrency issues are reflected in both overall resource metrics and how many times each job was able to run. I did this first with the original version from the previous tip as a baseline. The bulk load jobs managed to run three times, while the background process only ran once (and in fact took 14 minutes to complete). Here were the waits observed and the CPU usage throughout the initial six minute window:

After moving to the switch methodology, the background process still only ran once (and it took longer this time, just over 19 minutes), but the bulk load jobs were able to run 5 times each in the same time frame. Here are the wait and CPU charts for the new method:
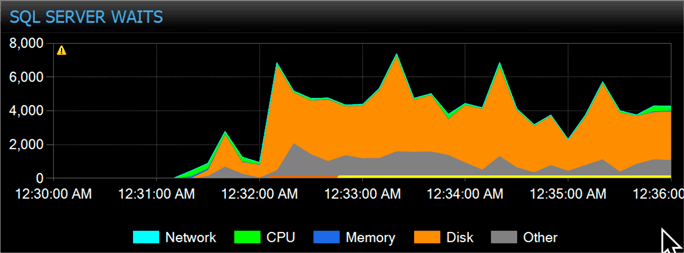
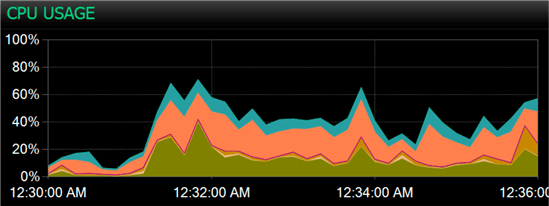
And a random data point for wait stats during processing:
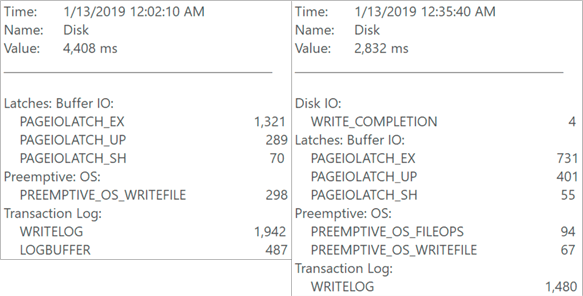
If you don’t notice any huge differences, you’re not alone. We’re still seeing relatively high disk waits, spread between writing to the log and latching data pages, and CPU usage is around the same, with peaks in the 60% range in both cases. The goal today was to reduce contention on the staging table, and we’ve accomplished that, even if we haven’t made any noticeable dents in overall resource usage. You can play around with frequency of the background process to balance how long it takes, how much it uses resources per run, and how frequently the data in the main table is updated.
Summary
In part 1 of this series, we minimized contention experienced by web or application servers bulk inserting into a table. In this segment, we eliminated much of the contention on the staging tables we created to spread out that load. There is still going to be significant resource usage no matter how you are shuffling around big volumes of data, but we can prevent certain areas of the system from feeling too much of the pain. A busy system is still going to see contention on the big table, of course. But we’re no worse off in that regard, and that contention will always be there anyway, unless you shift your read activity away. If you need further relief, and the cost of Enterprise Edition or the complexity of Availability Groups is still a non-starter, you can see my article, "Readable Secondaries on a Budget", where I describe how to simulate AGs with an elaborate log shipping scheme.
Next Steps
Read on for related tips and other resources:
- Minimally Logging Bulk Load Inserts into SQL Server
- Troubleshooting Common SQL Server Bulk Insert Errors
- Options to Improve SQL Server Bulk Load Performance
- Different Options for Importing Data into SQL Server
- Scale SQL Server Bulk Loading on a Budget, Part 1

Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He also blogs at sqlblog.org.
- MSSQLTips Awards: Author of the Year – 2016, 2023 | Leadership (200+ tips) – 2022


