Problem
From time to time we need to load data to a database from flat files. How can we do this when the SQL Server database is hosted on the AWS cloud using the managed database service (RDS)? Regardless of the cloud provider, managed database services are usually limited in terms of server size and features. Among AWS SQL Server RDS limitations is that there is no support of Integration Services and you have no BULK operation permissions. The problem I need to solve is to watch for files in a S3 bucket and load them to a SQL Server RDS database as soon as they arrive. So how can this be done?
Solution
There are several solutions to deal with the above problem.
- You can create another instance, on-premises or an AWS EC2 instance where you will have a full set of SQL Server features, like bulk insert to run data load flows to the remote RDS database.
- Use third party ETL software, but it will most probably require an EC2 instance as well.
- You can use the serverless AWS Glue service, AWS Data Pipeline service or event-driven AWS Lambda function.
If we are working in a serverless architecture, the first two options are not optimal. So, today we will take a closer look at the AWS Glue service and I will talk about AWS Data Pipeline and Lambda functions in separate articles.
AWS Glue Service
AWS Glue service is an ETL service that utilizes a fully managed Apache Spark environment. Glue ETL can read files from AWS S3 – cloud object storage (in functionality AWS S3 is similar to Azure Blob Storage), clean, enrich your data and load to common database engines inside AWS cloud (EC2 instances or Relational Database Service).
AWS Glue builds a metadata repository for all its configured sources called the Glue Data Catalog and uses Python/Scala code to define the transformations of the scheduled jobs. The Glue Data Catalog contains various metadata for your data assets and can even track data changes.
Let me show you how you can use the AWS Glue service to watch for new files in S3 buckets, enrich them and transform them into your relational schema on a SQL Server RDS database. I will split this tip into 2 separate articles.
- Part 1 – Map and view JSON files to the Glue Data Catalog
- Part 2 – Read JSON data, Enrich and Transform into relational schema on AWS RDS SQL Server database
Add JSON Files to the Glue Data Catalog
In this article, we will prepare the file structure on the S3 storage and will create a Glue Crawler that will build a Glue Data Catalog for our JSON data.
In general, you can work with both uncompressed files and compressed files (Snappy, Zlib, GZIP, and LZO). Take into consideration that gzipped files are not splittable – a job that reads the files will not be able to split the contents among multiple mappers in a meaningful way therefore the performance will be less optimal. If your files are smaller than 1GB then it is better to use Snappy compression, since Snappy compressed files are splittable.
In this example, each JSON file contains flight information data rows in JSON format:
{"year":2018,"month":1,"day":1,"dep_time":4,"dep_delay":-6,"arr_time":738,"arr_delay":-23,"carrier":"US","tailnum":"N195UW","flight":1830,"origin":"SEA","dest":"CLT","air_time":252,"distance":2279,"hour":0,"minute":4}
{"year":2018,"month":1,"day":1,"dep_time":1,"dep_delay":96,"arr_time":235,"arr_delay":70,"carrier":"AS","tailnum":"N508AS","flight":145,"origin":"PDX","dest":"ANC","air_time":194,"distance":1542,"hour":0,"minute":1}
{"year":2018,"month":1,"day":1,"dep_time":8,"dep_delay":13,"arr_time":548,"arr_delay":-4,"carrier":"UA","tailnum":"N37422","flight":1609,"origin":"PDX","dest":"IAH","air_time":201,"distance":1825,"hour":0,"minute":8}
I want all data to be recognized as one table and make AWS Glue see that the table is partitioned. In such case, the root data folder must be "partitioned". In my example I have a daily partition, but you can choose any naming convention. Here is how the AWS S3 partitions pattern / naming convention should look:

If all files in the S3 folder will not have the same recognizable pattern, AWS Glue will create a separate table for each file.
Here are the wizard steps to create a Crawler. You will need to provide the following:
- Crawler name
- S3 path to parent folder where the files/partition subfolders are located
- AMI role that has permissions to access S3 bucket
- Define the schedule on which Crawler will search for new files.
- Chose the Crawler output database – you can either pick the one that has already been created or create a new one.
AWS Glue managed IAM policy has permissions to all S3 buckets that start with aws-glue-, so I have created bucket aws-glue-maria.


My Crawler is ready. As you can see, the "tables added" column value has changed to 1 after the first execution.

Crawler log messages are available through the Logs shortcut only after the Crawler finishes its first execution. During the subsequent executions, if the Crawler is still running, after clicking on the Logs shortcut you will still see the previous execution log messages. Remove the filter to see all crawler executions including those that are in progress.
Note that the Crawler has identified 3 partitions/folders in my bucket and added all data to the same table.

The table name the Crawler created equals the parent data folder name.

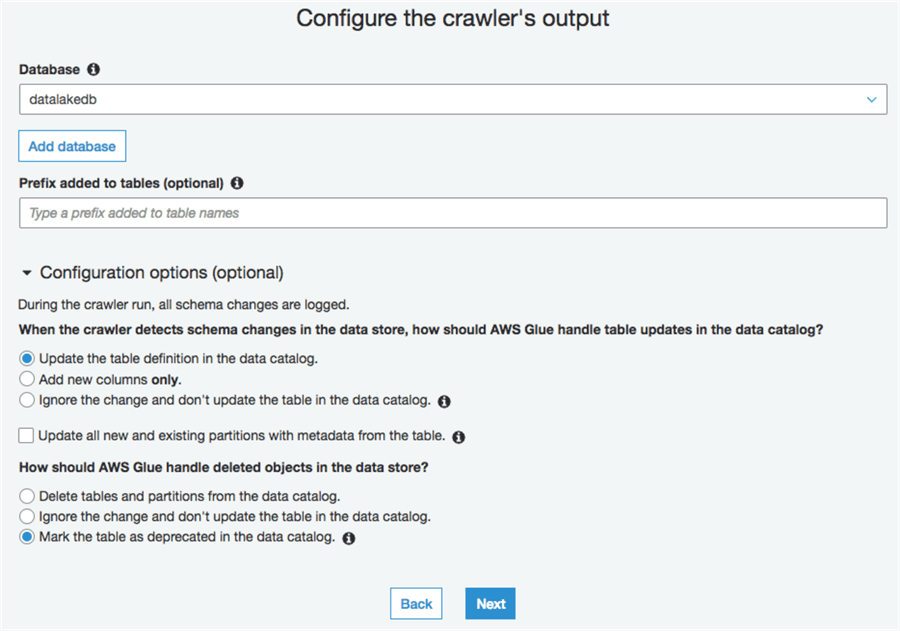
As you can see, the Crawler has parsed the JSON structure, turning each property into a column. In addition, a new column "partition" has been added. The Partition column will be used to partition elimination if you chose to use it as a filter in your queries.


If you want to give a specific name to the partition column, the naming convention of the folders should look like this:

Here is how the schema looks now. You can query on part_col like any other column in the table.
And I can see table partitions after clicking on "View partitions":

If I add another folder 2018-01-04 and a new file inside it, after crawler execution I will see the new partition in the Glue Data Catalog. Now you can even query those files using the AWS Athena service.
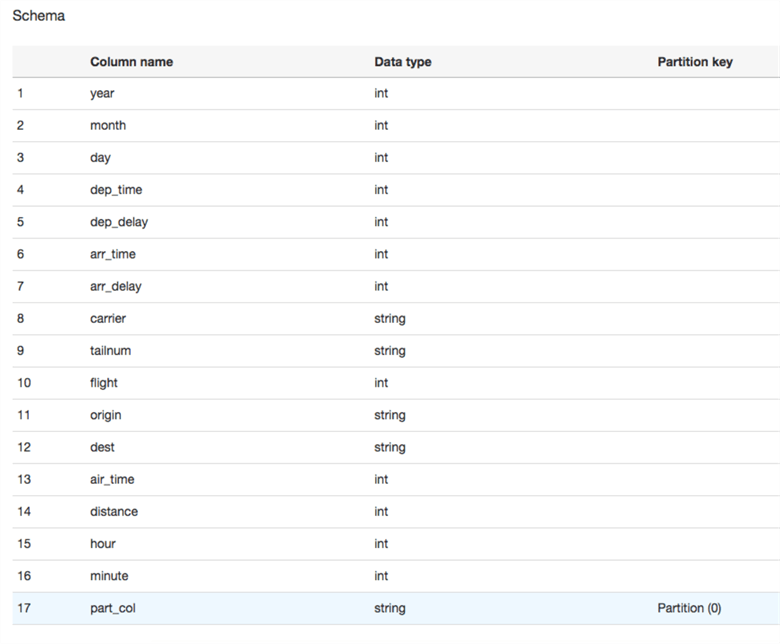
If we click on the View Properties link, we can see the rows metadata. Note the Key Size, RecordCount, averageRecordSizie, etc. metadata that will help to query those files in the future.
{
"StorageDescriptor": {
"cols": {
"FieldSchema": [
{
"name": "year",
"type": "int",
"comment": ""
},
{
"name": "month",
"type": "int",
"comment": ""
},
{
"name": "day",
"type": "int",
"comment": ""
},
{
"name": "dep_time",
"type": "int",
"comment": ""
},
.....
]
},
"location": "s3://aws-glue-maria/part_col=2018-01-02/",
"inputFormat": "org.apache.hadoop.mapred.TextInputFormat",
"outputFormat": "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat",
"compressed": "false",
"numBuckets": "-1",
"SerDeInfo": {
"name": "",
"serializationLib": "org.openx.data.jsonserde.JsonSerDe",
"parameters": {
"paths": "air_time,arr_delay,arr_time,carrier,day,dep_delay,dep_time,dest,distance,flight,hour,minute,month,origin,tailnum,year"
}
},
"bucketCols": [],
"sortCols": [],
"parameters": {
"sizeKey": "5028",
"objectCount": "1",
"recordCount": "23",
"averageRecordSize": "218",
"compressionType": "none",
"classification": "json",
"typeOfData": "file"
},
"SkewedInfo": {},
"storedAsSubDirectories": "false"
},
"parameters": {}
}
Clicking on "Edit Table", will get the following window where you can edit the above metadata if you think that statistics are wrong.

In the next post we will see how we can join the above JSON data with another file and load the final results into an AWS RDS SQL Server database.
Next Steps
- Check out other AWS tips
- Setting up VPC to access RDS data stores: https://docs.aws.amazon.com/glue/latest/dg/setup-vpc-for-glue-access.html
- What is Amazon Glue https://docs.aws.amazon.com/glue/latest/dg/what-is-glue.html
- Amazon Glue pricing https://aws.amazon.com/glue/pricing/

Maria Zakourdaev is a Data Platform Microsoft MVP and a technology expert with more than 20 years of experience, a community leader with a profound knowledge of Microsoft products and services, while also being able to bring together diverse platforms, products, and solutions to solve real-world problems.
Maria has a hands-on experience managing various data management technologies in Azure, AWS and Google public cloud platforms, including SQL Server, Azure CosmosDB, AWS DynamoDB, MemSQL, MySQL, Postgresql, Snowflake, Redis, Amazon Redshift, Couchbase and Elasticsearch, Spark, Databricks, Big Query.
Maria is an organiser of the annual conference “Data TLV” ( ex “SQL Saturday Israel”), a free training event for any data professionals: http://datatlv.com.
- MSSQLTips Awards: Trendsetter (25+ tips) – 2022 | Author Contender – 2022 | Rookie Contender – 2018


