Problem
In the first part of this tip series we looked at how to map and view JSON files with the Glue Data Catalog. In this second part, we will look at how to read, enrich and transform the data using an AWS Glue job.
Solution
Please read the first tip about mapping and viewing JSON files in the Glue Data Catalog: Import JSON files to AWS RDS SQL Server database using Glue service.
In this part, we will look at how to read, enrich and transform the data using an AWS Glue job.
Read, Enrich and Transform Data with AWS Glue Service
In this part, we will create an AWS Glue job that uses an S3 bucket as a source and AWS SQL Server RDS database as a target. We will use a JSON lookup file to enrich our data during the AWS Glue transformation. The job will use the job bookmarking feature to move every new file that lands in the S3 source bucket.
Let’s start the job wizard and configure the job properties:

We will enter the job name, IAM role that has permissions to the s3 buckets and to our AWS RDS database. I chose Python as the ETL language.
If you want to track processed files and move only new ones, make sure to enable job bookmark. Note that job bookmarking will identify only new files and will not reload modified files.
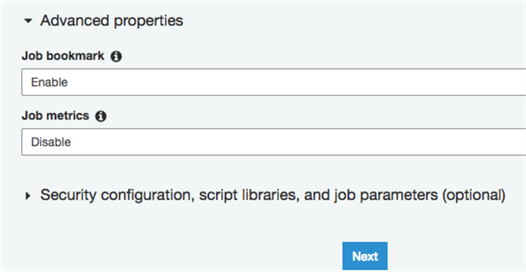
Bookmarks are maintained per job. If you drop the job, the bookmark will be deleted and new jobs will start processing all files in the bucket.
When you want to run a job manually, you will be prompted whether you want to keep Job Bookmark enabled or disable it and process all files.
In job parameters you can change concurrent DPUs per job execution to impact how fast the job will run, define how many concurrent threads of this job you want to execute, job timeout and many other settings. In our example I haven’t changed any of those parameters.
Add a SQL Server destination connection (Read Serverless ETL using AWS Glue for RDS databases for a step by step tutorial on how to add a JDBC database connection) and S3 source connection we will create in our script

After you press "save job and edit script” you will be taken to the Python script shell.
Here is a script that will support our requirements. Let’s follow line by line:
Create dynamic frame from Glue catalog datalakedb, table aws_glue_maria – this table was built over the S3 bucket (remember part 1 of this tip).
flights_data = glueContext.create_dynamic_frame.from_catalog(database = "datalakedb", table_name = "aws_glue_maria", transformation_ctx = "datasource0")
The file looks as follows:

Create another dynamic frame from another table, carriers_json, in the Glue Data Catalog – the lookup file is located on S3. Use the same steps as in part 1 to add more tables/lookups to the Glue Data Catalog. I will use this file to enrich our dataset. The file looks as follows:
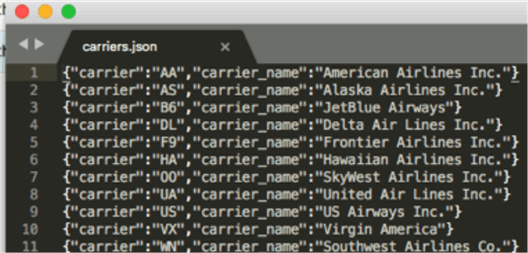
carriers_data = glueContext.create_dynamic_frame.from_catalog(database = "datalakedb", table_name = "carriers_json", transformation_ctx = "datasource1")
I will join two datasets using the Join.apply operator (dataframe1,dataframe2,joinColumn1DataFrame1,JoinColumn2dataframe2):
joined_data = Join.apply(flights_data,carriers_data,'carrier','carrier')
Build mapping of the columns. I want both carrier column and new column carrier_name from the lookup file:
applymapping1 = ApplyMapping.apply(frame = joined_data, mappings = [("year", "int", "year", "int"), ("month", "int", "month", "int"), ("day", "int", "day", "int"), ("dep_time", "int", "dep_time", "int"), ("dep_delay", "int", "dep_delay", "int"), ("arr_time", "int", "arr_time", "int"), ("arr_delay", "int", "arr_delay", "int"),("carrier", "string", "carrier", "string"), ("carrier_name", "string", "carrier_name", "string"), ("tailnum", "string", "tailnum", "string"), ("flight", "int", "flight", "int"), ("origin", "string", "origin", "string"), ("dest", "string", "dest", "string"), ("air_time", "int", "air_time", "int"), ("distance", "int", "distance", "int"), ("hour", "int", "hour", "int"), ("minute", "int", "minute", "int"), ("part_col", "string", "part_col", "string")], transformation_ctx = "applymapping1")
Create the output DataFrame and the target table name – it will be created if it does not exist.
datalake_dest = glueContext.write_dynamic_frame.from_jdbc_conf(frame = dropnullfields3, catalog_connection = "TestDataLakeDB", connection_options = {"dbtable": "flights_enriched", "database": "datalakedb"}, transformation_ctx = "datalake_dest")
Here is a full script the Glue job will execute.
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
flights_data = glueContext.create_dynamic_frame.from_catalog(database = "datalakedb", table_name = "aws_glue_maria", transformation_ctx = "datasource0")
carriers_data = glueContext.create_dynamic_frame.from_catalog(database = "datalakedb", table_name = "carriers_json", transformation_ctx = "datasource1")
joined_data = Join.apply(flights_data,carriers_data,'carrier','carrier')
applymapping1 = ApplyMapping.apply(frame = joined_data, mappings = [("year", "int", "year", "int"), ("month", "int", "month", "int"), ("day", "int", "day", "int"), ("dep_time", "int", "dep_time", "int"), ("dep_delay", "int", "dep_delay", "int"), ("arr_time", "int", "arr_time", "int"), ("arr_delay", "int", "arr_delay", "int"),("carrier", "string", "carrier", "string"), ("carrier_name", "string", "carrier_name", "string"), ("tailnum", "string", "tailnum", "string"), ("flight", "int", "flight", "int"), ("origin", "string", "origin", "string"), ("dest", "string", "dest", "string"), ("air_time", "int", "air_time", "int"), ("distance", "int", "distance", "int"), ("hour", "int", "hour", "int"), ("minute", "int", "minute", "int"), ("part_col", "string", "part_col", "string")], transformation_ctx = "applymapping1")
resolvechoice2 = ResolveChoice.apply(frame = applymapping1, choice = "make_cols", transformation_ctx = "resolvechoice2")
dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3")
datalake_dest = glueContext.write_dynamic_frame.from_jdbc_conf(frame = dropnullfields3, catalog_connection = "TestDataLakeDB", connection_options = {"dbtable": "flights_enriched", "database": "datalakedb"}, transformation_ctx = "datalake_dest")
job.commit()
Save the script and run the job.
Here is the result. Here is how my JSON flights data looks:
And here is how the carrier’s lookup file looks:

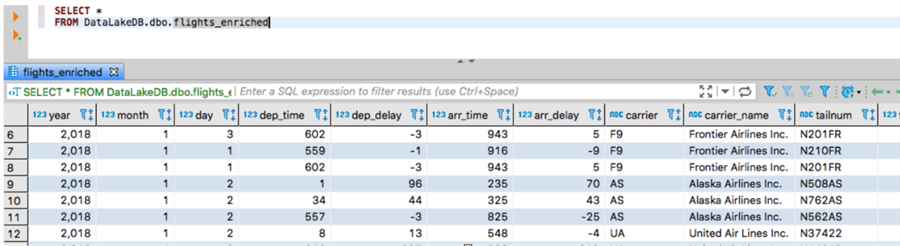
And here is the result table data in the SQL Server table after the job has finished execution:
Next Steps
- AWS Glue samples GitHub – https://github.com/aws-samples/aws-glue-samples
- What is Amazon Glue – https://docs.aws.amazon.com/glue/latest/dg/what-is-glue.html

Maria Zakourdaev is a Data Platform Microsoft MVP and a technology expert with more than 20 years of experience, a community leader with a profound knowledge of Microsoft products and services, while also being able to bring together diverse platforms, products, and solutions to solve real-world problems.
Maria has a hands-on experience managing various data management technologies in Azure, AWS and Google public cloud platforms, including SQL Server, Azure CosmosDB, AWS DynamoDB, MemSQL, MySQL, Postgresql, Snowflake, Redis, Amazon Redshift, Couchbase and Elasticsearch, Spark, Databricks, Big Query.
Maria is an organiser of the annual conference “Data TLV” ( ex “SQL Saturday Israel”), a free training event for any data professionals: http://datatlv.com.
- MSSQLTips Awards: Trendsetter (25+ tips) – 2022 | Author Contender – 2022 | Rookie Contender – 2018



Hi,
i am trying to find a resource tht uses from_options function and connects to sqlserver to extract data using a query.
is there such example? I have tried jdbc connection and extracted but the performance is not really great so wanted to know the dynmic frame using from_options usage.