Problem
The advent of Azure’s numerous data services has triggered both excitement and confusion in the data warehousing space for several reasons. Customers are interested in the concept of a Modern Cloud-based data warehouse, but may be overwhelmed by the overabundance of cloud-based services available on the market. They are interested to know how they could get started with implementing traditional data warehousing concepts such as dimensional modeling, Slowly Changing Dimensions, Star Schemas, and data warehousing E-T-L or E-L-T in the cloud. Traditional on-premises Microsoft technologies such as SQL Server Integrations Services (SSIS) is a mature data integration tool that has been prevalent for over a decade. As more cloud-based tools are becoming available and customers are interested in either migrating their E-T-L to the cloud, or simply interested in getting started with understanding data warehousing in the cloud, how can they get started and what tools might they use?
Solution
As more companies are expressing interest in a Cloud-based Modern Datawarehouse, Azure Data Factory is continuing to play a significant role in this Data Integration and ETL process. Microsoft continues to meet and exceed this need and interest by expanding their service offerings within Azure Data Factory by recently adding Mapping Data Flows, which allows for visual and code-free data transformation logic that is executed as activities with Azure Data Factory pipelines using scaled out Azure Databricks clusters. Essentially this offering, which is in preview at the time of this writing, brings Azure Data Factory one-step closer to Microsoft’s traditional SQL Server Integration Services, which has been used for Data Warehousing ETL for many years. Mapping Data Flows has tremendous potential in the Data warehousing space for several Data warehousing patterns such as Slowly Changing Dimensions Type I, Type II and Fact extraction, transformation, and data loading.
In this article, I will discuss the typical data warehousing load pattern known as Slowly Changing Dimension Type I and how Azure Data Factory’s Mapping Data Flow can be used to design this data flow pattern by demonstrating a practical example.
Modern Datawarehouse
Azure Data Factory plays a key role in the Modern Datawarehouse landscape since it integrates well with both structured, unstructured, and on-premises data. More recently, it is beginning to integrate quite well with Azure Data Lake Gen 2 and Azure Data Bricks as well. The diagram below does a good job of depicting where Azure Data Factory fits in the Modern Datawarehouse landscape. As we can see from this diagram, Data Factory is a key integrator between source, target and analytical systems. Additionally, by adding a code free graphical user-based interface such as Mapping Data Flow that utilizes Spark clusters under the hood, Azure Data Factory is sure to play a key role in the design and development of the Modern Datawarehouse.

Prepare Azure Resources
As a first step to exploring the services in Mapping Data Flows, we will need a few Azure Resources to be created. Specifically, the following services will need to be running online and can be created by using the Azure portal.
Prerequisites
1) Create a Data Factory: Refer to the following Microsoft document to create an Azure Data Factory. Remember to choose V2 which contain Mapping Data Flow, which is in preview at the time of this article: “Quickstart: Create a data factory by using the Azure Data Factory UI.”
2) Create a logical SQL Server and two SQL Databases (OLTP_Source and OLAP_Target): Refer to the following Microsoft article to create a SQL Database: “Quickstart: Create a single database in Azure SQL Database using the Azure portal.”
While creating my source SQL database, I will select the Sample AdventureWorksLT OLTP database which will contain sample tables with data that I can then use in my Data Factory pipeline.

After creating my SQL Server, I will make sure to add my Client IP to the firewall settings so that I can access the SQL Database from my local machine.


After configuring my firewall settings, I will navigate to SQL Server Management Studio and will then login using my credentials to verify that I can see my source and target databases. Additionally, my source database will contain the AdventureWorksLT tables, data, and schema.

As a last step to verify that I have all my necessary resources created, I will navigate to my resource group in the Azure portal and confirm that I have a Data Factory, Logical SQL Server, Source Database and Target Database.

Select a Datawarehouse Design Pattern
Slowly Changing Dimension Type I
Slowly Changing Dimensions are commonly used advanced techniques for dimensional data warehouses and are used to capture changing data within the dimension over time. While there are numerous types of slowly changing dimensions, Type I, which we will cover in this article, simple overwrites the existing data values with new values. The advantage of this method is that is makes updating the dimension easy and limits the growth to only new records. The disadvantage is that historical data will be lost since the dimension will always only contain current values for each attribute.
This demonstration will leverage Slowly Changing Dimension Type I within the Azure Data Factory pipeline.
Create an Azure Data Factory Pipeline and Datasets
Now that my Data Factory (V2) is online, I can begin creating my Pipeline for a Slowly Changing Type I ETL Pattern.
I’ll start by clicking ‘Author & Monitor’ to launch my Azure Data Factory console.

I will then create a new pipeline by clicking ‘Create Pipeline’.

For more information related to creating a pipeline and dataset, check out the tip Create Azure Data Factory Pipeline.
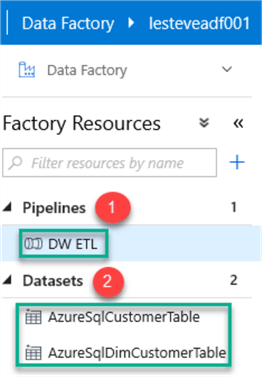
I will name my pipeline DW ETL which will contain the following two datasets:
1) AzureSqlCustomerTable: This is my OLTP Azure SQL Source database which contains my AdventureWorksLT tables. Specifically, I will use the Customer Table for my ETL.
2) AzureSqlDimCustomerTable: This is my OLAP Azure SQL Target database which contains my Dimension Customer Table. This dimension table will vary from the OLTP source table in that it contains fewer fields and contains an InsertedDate, UpdatedDate and HashKey, which I will use for my SCD Type I ETL pattern.
Once the Pipeline and Datasets are created, the Factory Resources will appear as follows:
Create Azure Data Factory Mapping Data Flow
Now that I have created my Pipeline and Datasets for my source and target, I are ready to create my Data Flow for my SCD Type I. For additional detailed information related to Data Flow, check out this excellent tip on “Configuring Azure Data Factory Data Flow.”
I will start by dragging my Data Flow from Activities onto my Data Factory canvas.

I will give it an intuitive name like SCDTypeI.

Prior to creating the Data Flow, I will make sure to turn on ‘Data Flow Debug’ mode since I will be testing out my pipeline voraciously prior to deploying it into production.
For more detail on Data Flow Debug mode, check out Microsoft’s document: “Mapping Data Flow Debug Mode”.

When I toggle on the Debug mode, I will be asked if I wish to proceed.

The clusters will take a few minutes to get ready.
Once Data Flow Debug mode is turned on, a green dot will appear to the right of it. Now I am ready to begin creating my Slowly Changing Dimension Type I Data Flow.

I will start Data Flow by adding and configuring my two datasets as sources.

Next, I will click the + icon next to AzureSqlCustomerTable to add a Derived column, which I will call CreateHash.

I’ll then select my Hash Columns and use the Hash function. For my scenario, my derived column will use the following function:
sha1(FirstName+LastName+CompanyName)

I will then add the following inputs, schema and row modifiers to my data flow.

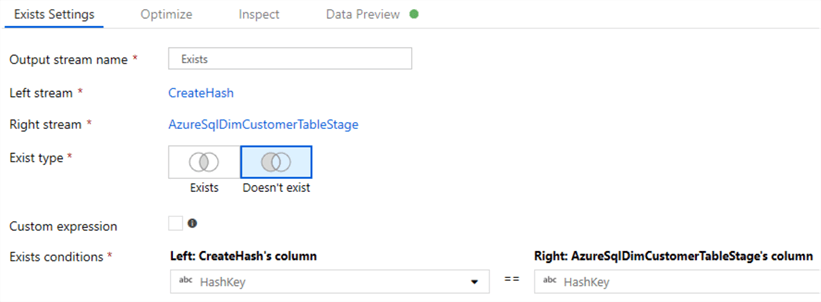
Exists
This will check if the hash key already exists by comparing the newly created source hash key to the target hash key.
LookupDates
This will join the CustomerID from the Source to the Target to ensure we pull in all pertinent records that we need.

SetAttributes
This will add two derived columns. InsertedDate will insert the current timestamp if it is null and UpdatedDate will always update the row with the current timestamp.

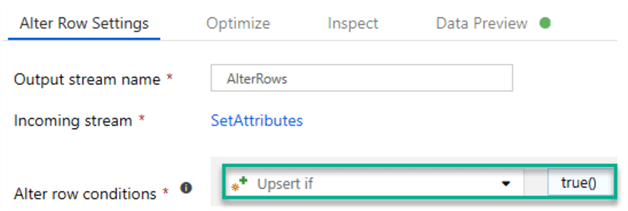
AlterRows
This will allow for upserts, with a condition set to true(), which will update or insert everything that passes through the flow.
Sink1
The sink will write back to the DimCustomer table.

Note that within the settings tab, ‘Allow upsert’ is checked, with CustomerID specified as the Key column.

Lastly, I will ensure that the mapping is accurate. ‘Auto Mapping’ may need to be disabled to correctly map the newly created derived columns.

Once my Slowly Changing Dimension Type I Data Flow is complete it will look like this.

I have now completed designing and configuring my SCD Type I Data Flow. Since I have switched on debug mode, I will simple click ‘Debug’ in the pipeline view and wait for the pipeline to complete running.

Once the pipeline completes running, I will see a green check-circle to the right along with the pipeline succeeded status. Since there was no data in my DimCustomer Table, this pipeline run will load all records to my DimCustomer table.

Updating a Record
To test the functionality of this pipeline, I will pick a record from my OLTP system and Update the LastName which is one of the values in my HashKey.
SELECT * FROM [SalesLT].[Customer] WHERE CustomerID = 148

I will then go ahead and update the LastName for CustomerID 148 from Brewer to Update.
UPDATE [SalesLT].[Customer] SET LastName = 'Update' WHERE CustomerID = 148 SELECT * FROM [SalesLT].[Customer] WHERE CustomerID = 148

Prior to re-running the ADF pipeline, when I do a select on my DimCustomer Table, I can see that the LastName is still ‘Brewer’.
SELECT * FROM [dbo].[DimCustomer] WHERE CustomerID = 148
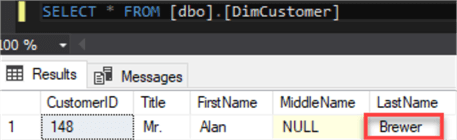
After I re-run my ADF pipeline, I will see that LastName has been updated appropriately which confirms that the ADF pipeline accounts for updates.

Inserting a Record
I will also test inserting a new record into my OLTP system and then re-run my ADF pipeline to see if the insert is picked up.

USE [mssqltipsOLTP_Source] GO INSERT INTO [SalesLT].[Customer] ([NameStyle] ,[Title] ,[FirstName] ,[MiddleName] ,[LastName] ,[Suffix] ,[CompanyName] ,[SalesPerson] ,[EmailAddress] ,[Phone] ,[PasswordHash] ,[PasswordSalt] ,[rowguid] ,[ModifiedDate]) VALUES (1 ,'Mr.' ,'John' ,'B' ,'Doe' ,NULL ,'MSSQLTips' ,NULL ,NULL ,NULL ,'L/Rlwxzp4w7RWmEgXX+/A7cXaePEPcp+KwQhl2fJL7d=' ,'1KjXYs4=' ,'2005-08-01 00:00:00:000') GO
My new record has been inserted into the [SalesLT].[Customer] Table.
SELECT * FROM [SalesLT].[Customer] WHERE CompanyName = 'MSSQLTips'

After I re-run my ADF Pipeline, I can see that the new OLTP record has also been inserted into my [dbo].[DimCustomer] table, which confirms that the ADF pipeline accounts for inserts.

Remember to turn off ‘Data Flow Debug’ mode when finished to prevent un-necessary costs and unused utilization within Azure Data Factory.
Also, remember to cleanup and delete any unused resources in your resource group as needed.

Next Steps
- In this article, we discussed the Modern Datawarehouse and Azure Data Factory’s Mapping Data flow and its role in this landscape. We also setup our source, target and data factory resources to prepare for designing a Slowly Changing Dimension Type I ETL Pattern by using Mapping Data Flows. Additionally, we designed and tested a Slowly Changing Dimension Type I Data Flow and Pipeline within Azure Data Factory.
- Check out Slowly Changing dimension for more information related to all SCD Types including advantages and disadvantages of each type.
- Check out Microsoft’s article: Get started quickly using templates in Azure Data Factory, as there are templates being added for Slowly Changing Dimension Type II, data cleansing and more.
- Read The Datawarehouse Toolkit by Ralph Kimball for a definitive guide to Dimensional Modeling.
- Explore creating Azure Data Factory pipelines for Slowly Changing Dimensions Type II and Fact Loading.

Ron C. L’Esteve is a Data and AI Leader and professional Author residing in Chicago, IL, USA. He is well-known for his impactful books and article publications on Azure Data & AI Architecture, Engineering, and Leadership. Ron holds a Master of Business Administration (M.B.A.) and Master of Science in Corporate Finance (M.S.F.) from Loyola University Chicago. Ron possesses deep technical skills and experience in designing, implementing, leading, and delivering modern Azure Data & AI projects for numerous clients around the world. He is a Motorola Certified Six Sigma Green Belt, a Microsoft Global Challenger, and also holds numerous additional Microsoft, Snowflake, and Databricks professional certifications in Big Data Engineering, Artificial Intelligence, Apache Spark and Data Platform Architecture.
- MSSQLTips Awards: Champion (100+ tips) – 2023 | Author of the Year – 2020-2021 | Rookie of the Year – 2019


What do you consider the best way to implement AuditPkgExecution, AuditTableProcessing, and DimAudit using Azure Data Factory and Azure Synapse Analytics?
Hi Ron L’Esteve,
Very nice and helpful article for learning ADF.
I was able to follow all steps in the article almost without any problem.
I just faced one problem about defining the schema of dbo.DimCustomer (at the beginning of article), which took me several hours.
I suggest mentioning the following sql script in the article.
CREATE TABLE dbo.DimCustomer (
[CustomerID] INT NOT NULL,
[Title] NVARCHAR (8) NULL,
[FirstName] [dbo].[Name] NOT NULL,
[MiddleName] [dbo].[Name] NULL,
[LastName] [dbo].[Name] NOT NULL,
[Suffix] NVARCHAR (10) NULL,
[CompanyName] NVARCHAR (128) NULL,
[SalesPerson] NVARCHAR (256) NULL,
[EmailAddress] NVARCHAR (50) NULL,
[InsertedDate] DATETIME NULL,
[UpdatedDate] DATETIME NULL,
[HashKey] NVARCHAR (128) NOT NULL,
PRIMARY KEY (CustomerID)<br>);
Thanx a lot for this valuable article.