Problem
Transferring SQL Server data from a source database with numerous data tables with time and system resource limit is a very common issue. Let's assume that we have:
- A hundred tables to transfer to a destination database in a simple way: table-to-table and field-to-field
- A Data Flow Task (DF-task) for each pair of source-destination tables.
We can design an ETL package in two extreme ways, where all DF-tasks are either:
- Run each sequentially, one by one (this take a long time to run and has low usage of CPU and RAM)
- The loads are not connected and they can all run at the same time (this can cause CPU and RAM overloading that can narrow and improve concurrent execution).
Solution
Possible Approach to Load Data in Parallel with SSIS
As practice shows, when the number of tables to transfer is large and so are the sizes of the tables, both the above-mentioned approaches do not give satisfactory results.
The better approach is to build a process in a semi-parallel way, meaning that a group of Data Flow Tasks (not all of them!) are executed concurrently. Such an approach shortens the time of execution and gives a more balanced usage of CPU and RAM.
One possible design of such an approach is shown below.

Figure 1
However, one can find at least three disadvantages in this structure:
- The package becomes inconvenient for visual observation and updates if a large number of tables are involved
- Manual changes in the structure are required when it needs to include new tables in the ETL process
- It is difficult to achieve balanced CPU and RAM usage with such a rigid and inflexible structure, which can cause extra time to process
- For example, if TABLE_1 is much larger than TABLE_2, TABLE_3 and TABLE_4, then DF_2, DF_3 and DF_4 finish faster than DF_1. This means that for a certain time a server is busy with TABLE_1 only and it propagates further ETL slowdown, because other tables (TABLE_5 – TABLE_8), can not start processing until DF_1 completes.
A similar situation can occur in other sequence containers. Therefore, the main reason of the slowdown is its serial nature, nothing moves forward until the currently running container gets finished.
Better Approach to Load Data in Parallel with SSIS
Another solution can be found based on the model below, which is defined in queuing theory as ‘a one-stage queuing model with multiple parallel servers’.

Figure 2
To avoid terminology confusion – ‘server’ within the Processing Module means a Processing Unit to serve (or process) a customer.
All servers in this model work asynchronously, i.e. when a server finishes the processing of a customer, it immediately takes another non-processed customer from the queue independently from other servers. There are K servers in Figure 2, therefore, the customers are dynamically distributed among K processing streams during run time. In other words, K is the rate of parallelism of the ETL process.
In terms of SSIS, this approach can be represented as follows:
- Each DF-task, associated to a source table, is implemented as a separate SSIS table loading package (TL-package), which is treated as a child SSIS package. These TL-packages should be represented as Connection Objects within the master SSIS package.
- Each server within the Processing Module is implemented as a SSIS ‘Execute Package Task’ (EP-task)
- The Processing Module is implemented as a master SSIS package, that operates in the following way.
- It scans in cycle the queue of source tables to find both an unprocessed table and a server that is free for processing at the moment (i.e. to identify the appropriate TL-package and the EP-task).
- Assigns the found child TL-package to the found EP-task, executes the task and marks the table as processed.
- Completes the ETL when all tables from the queue are processed.
This approach has three main advantages:
- Balanced usage of RAM and CPU, therefore, idle time is minimized.
- Scalability: no structural changes are needed when a new table should be included in the ETL process. Only appropriate child TL-packages need to be created and included in the pool of Connection Objects of the master package
- Configurability: if needed, it is very easy to include/exclude a server within the Processing Module, changing the rate of parallelism of the ETL process.
To comment further on the latter point: why maintaining configurability is so important?
- Computers in the development environment are often not as powerful as the production computers. Therefore, in development, the rate of parallelism might only be able to run at 3 or 4, but in production it might be able to run at 7 or higher. The proposed approach allows us to make this change easily at the configuration level. For example, you can include 20 servers within the Processing Module and enable only 2 or 3 of them for development. When deploying the package to test and production, you can enable more servers to increase the ETL bandwidth.
In fact, the master and the set of SSIS packages form an easily extendable framework (see Fig.3), that can provide flexibility and scalability of the ETL process.

Figure 3
Overview of SSIS Package to Load Data in Parallel
The data used in this sample package is taken from database AdventureWorksLT2012 (https://github.com/Microsoft/sql-server-samples/releases/tag/adventureworks2012).
The destination tables reside in the database AdWorksDestination, they have the same names and same data schema as the source tables. The list of tables to process is in the dbo.ETLlog table (see Figure 4).

Figure 4
The structure of the main SSIS ETL package is shown in Figure 5.
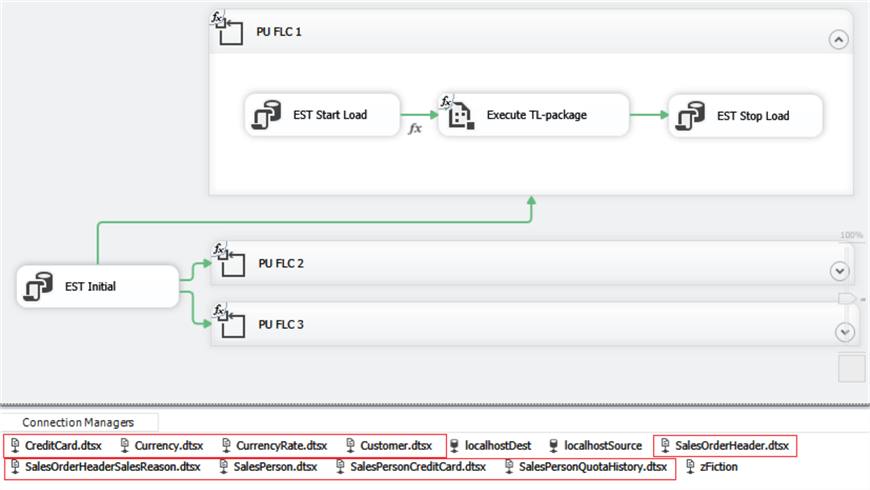
Figure 5
The package includes three For Loop Containers (PU FLC) with unique numbers 1, 2, 3. Each of these containers plays the role of a Processing Unit that should transfer source data to the destination in parallel.
The Connection Managers pool includes connections to each of the TL-packages (outlined in red above).
Each TL-package is very simple (see Fig.6a and 6b for the table Sales.CreditCard). The TL-package CreditCard.dtsx for Sales.CreditCard.

Figure 6a

Figure 6b
The algorithm of a Processing Unit consists of the following steps.
- Seek a non-processed table in the dbo.ETLlog with an empty StartTime. It is performed by the SQL task ‘EST Start Load’ in Figure 5.
- If such table is found, its name goes to the user variable @[User::vTableName]. If it is not found, i.e. (@[User::vTableName] = ”), the Processing Unit is stopped.
- If, for example, @[User::vTableName] =’Sales.CreditCard’ and the process is running, the current timestamp is set in the StartTime column of the dbo.ETLlog table and the unique number of the Processing Unit – in the FlowNr column (see Figure 7)

Figure 7
The TL-package name is defined for the selected table. Example: the table name Sales.CreditCard results to the TL-package name CreditCard.dtsx – the value of the user variable @[User::vPackageName]. This value is passed as an input parameter to the ‘Execute TL package’ task for further execution (see Figure 8). This is how a Processing Unit gets switched dynamically from one table to another.

Figure 8
When the TL-package is finished, the EndTime column gets a current timestamp (the SQL task ‘EST Stop Load’ in Fig.5) and the process repeats again from step 1.
The Main ETL package stops when all Processing Units are finished, i.e. when there is no record in the dbo.ETLLog with an empty value in the StartTime column. The result of the Main ETL execution is shown in Figure 9.
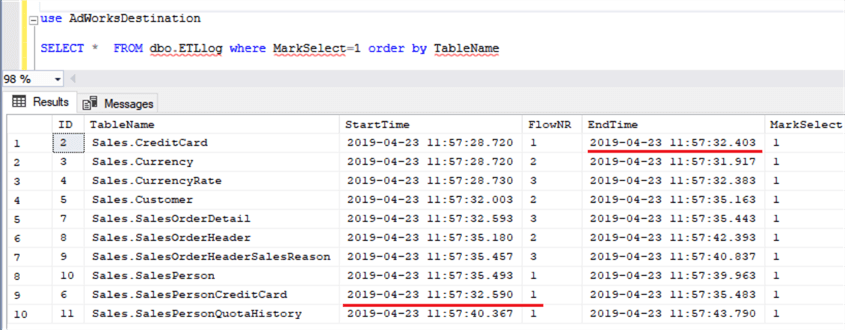
Figure 9
Above, the first three records show that Processing Unit 1, 2 and 3 started at the same time and they continued working asynchronously, processing a new table after finishing the current one. The rows underlined in red in Fig.9 show that the table Sales.SalesPersonCreditCard is taken by the first Processing Unit just after the table Sales.CreditCard is processed.
Configurability and Scalability
The ETL process can be pre-configured in different ways.
- By marking tables in the MarkSelect column and process only tables where MarkSelect = 1 (module ‘EST Start Load’ in Fig.5). It is useful in cases where you need to do a partial data transfer.
- Scalability of this ETL can be provided in two ways.
- Structural scalability – To include a new table in the ETL process, all that is needed is to i) insert the table name into dbo.ETLlog, ii) to implement an appropriate TL-package , iii) include the link to the new package in the Connection Managers pool of the Main ETL. No other structural change is required.
- Processing scalability – Sometimes it may be needed to vary the number of Processing Units, i.e. to change the rate of parallelism of the Main ETL. It can be achieved by using an additional configuration table, like the one in Fig. 10.

Figure 10
This data can be used within the ‘EST StartLoad’ module of each Processing Unit using the following T-SQL script.
DECLARE @PU_FLC_Nr INT =5; -- the unique number of a Processing Unit; to be passed parametrically DECLARE @TableName VARCHAR(100) =''; -- the name of a new table selected for processing IF NOT EXISTS(SELECT 1 FROM dbo.ETL_ParaRate WHERE PU_FLC_Nr = @PU_FLC_Nr) BEGIN RETURN -- exit with empty value of @TableName that causes Processing Unit stop. END; -- continuation with table selection and definition of TL package
The script returns an empty table name when the Processing Unit unique number is not given in dbo.ETL_ParaRate. It causes the Processing Unit to not run, excluding it from further ETL processing.
Many Processing Units may be defined within the Main ETL in advance. The rate of parallelism of the Main ETL can be easily modified by including them in or excluding them from the dbo.ETL_ParaRate prior to the ETL run.
The ETL results for the case when PU_FLC_Nr = 3 is excluded from the configuration table is given in Fig. 11.

Figure 10
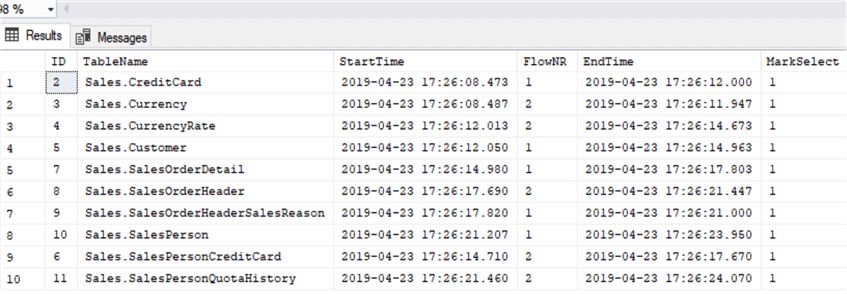
Figure 11
Figure 11 depicts the results of ETL process.
Possible Extensions
The described ETL framework is based on a log table (dbo.ETLlog), a configuration table (dbo.ETL_ParaRate) and Main SSIS package, consisting of several For Loop Containers to work in parallel. Of course, this is just a basic framework structure that can be extended in multiple ways.
Let's have a look at possible extensions.
1) The status of a currently processed table may be necessary to know. For that purpose an additional column ‘Status’ can be added in the table dbo.ETLlog set to:
- ‘RUNNING’, when the TL-package started;
- ‘OK’, when the table is successfully processed;
- ‘FAIL’, when the table loading failed.
- Later the tables with Status=FAIL can be manually or automatically reloaded (say, after fixing the detected issues).
2) Sometimes the order of transfer of the source tables is important. If that matters, it makes sense to introduce another column ‘Priority’, for example from 1 (highest priority) to N (lowest priority). In this case the table with Priority = N should be selected, if all tables of higher Priority = (N-1) are already processed.
A Real Life Use Case
A real task from the author’s experience included 20+ source databases of identical structure, each containing 60+ tables, i.e. around 1300 tables in total to be transferred per each ETL run. In many of these tables the number of extracted records reached up to 2.5 million with dozens and dozens of columns in the table structures. The batch ETL time limit was set to 45 minutes.
The basic framework was applied here in a two-level option:
- First - Country level - the Main package with four Processing Units to cover all 20+ source databases
- Second - Table level - implemented as an SSIS package with six Processing Units to cover 60+ tables from a country database
In this solution a Processing Unit at the Country level calls not a TL-package for table data transfer – it calls a parameterized reusable SSIS package to transfer data from all 60+ tables from a country database. The country name is used as an input parameter to set the connection to the appropriate database.
The task was successfully solved mainly due to this hierarchical structure of the Main ETL – a real advantage in composing multi-level ETL.
Conclusions
The given approach is rather compact and can be successfully used in a mass data transfer at the initial pre-transformation stage. It makes possible to build flexible, configurable, and scalable ETL processes. It can be much more advantageous and productive when combined with other (not obvious) functionalities that SSIS provides.
Next Steps
- Check out these other SSIS development tips
- Download the scripts and SSIS Package to support this tip.

Aleksejs Kozmins is a professional in the Data Warehousing and Business Intelligence area. He has been working in this direction for 15+ years. His main interests lay in development of data integration processes based on SQL Server Integration Services enriched with Visual Studio.NET and efficient usage of T-SQL applied to large data sets. Focused mainly on rational building of ETL, including ETL configuration, detailed logging, productive staging, easy control functions, etc. The achieved results have been successfully introduced in various European scale IT projects. Further, Aleksejs has published his papers on Data Integration topics in the proceedings of International Workshops.
- MSSQLTips Awards: Rookie of the Year Contender – 2019


Hi,
How do I secure the parallell processes not selecting the same row from the ETL-table?
My script is often selecting the same row on the first iteration resulting in dupicates in the table.
Br
Martin
Thanks, it is very useful.
Hi Martin, there is a link in the Next Steps section of the article to download the scripts and SSIS package.
-Greg
Hello, where can I find the Zip-file with the solution?
Stumbled across this while researching Parallel processing in SSIS. I downloaded and opened the solution and noticed you actually use the (NOLOCK) table hint when selecting the next item in the queue. How does this solution guarantee that each for loop processes a different table? Isn’t it possible that the same queue record is selected in different for loops? Thanks.
Hi – How is this solution better than using tasks not connected by precendence constraints? You write that this can cause CPU and RAM overloading but wouldn’t setting the package property MaxConcurrentExecutables to an appropriate number reduce that possibility?