Problem
After more than a decade working with the Microsoft Data Platform, and more specifically the business intelligence stack, I can look back and tell you there are some things I wish I’d known sooner. In this tip, we cover some topics that – if I could go back in time – I would tell my younger self to pay attention to.
Solution
Aaron Bertrand wrote a similar tip about his SQL Server career: Five Things I Wish I Knew When I Started My SQL Server Career. In this tip I am going to share some of the things I wish I knew early on in my career.
Lesson 1 – Don’t invest (too much) in SharePoint BI
It’s easy to say looking back. Now we know Power BI Desktop and the Power BI service have taken over the realm of self-service BI, but who would’ve guessed 5 years back? At the time, if you wanted an integrated portal where you could host your business intelligence artifacts, SharePoint was your only option. For SSRS, you could use Report Manager, a lightweight site to host your SSRS reports, data sets and data sources. But it couldn’t handle interactive Excel dashboards or Power Pivot. Report Manager was also hard to customize.
SharePoint sites seemed like an ideal solution: you could customize the site, and it could handle SSRS, Excel and Power Pivot. The problem was that it was not that easy to set-up. Usually, BI people didn’t have the necessary SharePoint skills to set up the server correctly, and SharePoint people didn’t have the BI skills to configure the BI components. Most of the time, you had to use Kerberos to delegate authentication or you had to know how to implement service credentials correctly.
Learning SharePoint
I invested some time in trying to learn SharePoint. This started with a course on SharePoint business intelligence components (which also included how to create interactive diagrams with Visio). I experimented with setting up a SharePoint server on a virtual machine (you needed quite a strong laptop for that), which resulted in a long series of blog posts. In the end, I only did one project where I could use all this knowledge. When this project was finished, Power BI took over. Everything that SharePoint did, Power BI does better: you have the interactive Power BI reports of course, but you can also host Excel files or analyze data sets in Excel. The Power Pivot engine is integrated into Power BI Desktop and you can now also host SSRS reports in Power BI (now called paginated reports). Even the Visio integration is present…
The question is, what should I invested in instead? Well, maybe I could’ve played around more with Power Pivot so the DAX language wouldn’t hold that many secrets to me. Or I could’ve spent more time with Azure.
Lesson 2 – NULLs can be evil
I’ve spent a lot of time debugging a piece of T-SQL code, wondering why a couple of rows were missing or why some value wasn’t calculated, only to realize: NULL values! The problem with NULL values is in Boolean logic, they equate to unknown, which is neither true or false. For example, if you try to convert a NULL to a Boolean value, you get NULL as a result:

Everything breaks down when you’re doing comparisons and NULL values are involved. Let’s suppose we have the following SQL query which checks if one value is bigger, smaller or equal than another value:
DECLARE @a INT
DECLARE @b INT
SET @a = 1
SET @b = 5
SELECT CASE WHEN @a < @b THEN 'a is smaller'
WHEN @a > @b THEN 'a is bigger'
WHEN @a = @b THEN 'a and b are equal'
END AS Test
At first sight, this code checks all the possible outcomes, right? If you run the code, it will return that a is smaller than b. However, if one of the values is NULL (below I commented out the line that sets a value for b), the code will simply return NULL.
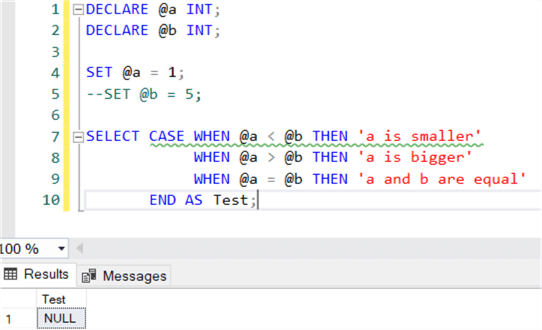
Code like this can easily be fixed by using ISNULL or COALESCE, but also by specifying an ELSE clause for each CASE statement. But NULL values can also introduce issues with operators like (NOT) IN, SOME and ANY. You can find some examples in the tip SQL Server IN vs EXISTS. You can declare all columns as NOT NULL to try to avoid NULL values popping up, but remember joins like LEFT JOIN and FULL OUTER JOIN can also introduce NULL values in your result set!
If you have unit tests, it is always a good idea to include some checks for NULL values.
Lesson 3 – Use compression
SQL Server has a magical button to save disk space and IO and it’s called compression. With row or page compression (row being a subset of page compression), data is compressed inside the pages of the table. It depends on the structure of the table and the contents of the columns of course, but it is not unusual to see the size of the table go down up to 40% or even more. Everything has a trade-off and in this case it’s CPU cycles. Compressing your data might in some cases lead to slower queries, for example when the data comes from cache a non-compressed table might be a bit faster. So, test it out for your environment.
Typically, compression is a good fit for data warehouses since most tables are large and have a lot of scans. Enabling compression will significantly reduce the IO for those tables. Compression is available for Standard Edition since SQL Server 2016 sp1. Keep in mind though, a clustered columnstore index might compress your data even further and might have additional benefits such as segment and column elimination. Be sure to check those out as well.
Let’s take a look at an example of page compression. In the WideWorldImporters data warehouse, I created a bigger version of the Fact Orders table. The result is an 18 million row table with a size of almost 3.7GB. Of this table, a copy was taken. With the following code, we enable page compression on this copy:
ALTER TABLE [Fact].[Order_Big_Compressed] REBUILD WITH ( DATA_COMPRESSION = PAGE
The results:
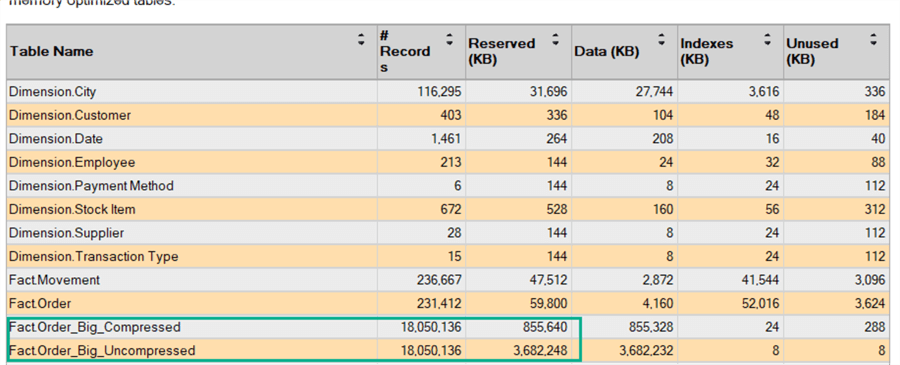
As you can see, the size of the table on disk is reduced by over 70% to 856MB.
Lesson 4 – Be aware of the defaults
When you install SQL Server and other features, most of them are installed with the default settings, especially if you clicked next-next-finish in the SQL Server setup. Some of those defaults can have an impact on performance or the health of your server:
- The default recovery model of a database is full recovery. Chances are big – certainly in a data warehouse – that you don’t need point-in-time recovery. Setting the recovery model to simple or bulk-logged will save time on INSERTS, but also on the size of the transaction log.
- The defaults of the SSIS catalog are not that optimal. Not only the recovery model (see the previous point), but also the log retention settings can cause your SSISDB to grow in size. Check out the tip SQL Server Integration Services Catalog Best Practices to see what you can do about those defaults.
- The default size of a database is really small. You most likely want to provision a much bigger size for your database so it’s not busy growing all the time. The auto growth settings are also problematic, especially for earlier versions of SQL Server. If not careful, a log file could fill up the whole disk.
- And you definitely don’t want to install everything on the c:\ drive of your server!
Aside from configuration defaults, there are some default behaviors in the T-SQL query language. One that springs to mind is the default window frame extent for window functions. If you specify an ORDER BY clause, the default frame extent is RANGE UNBOUNDED PRECEDING AND CURRENT ROW which might not always give the results you expect. Here’s an example that illustrates the difference:

For more information, check out the tutorial on window functions.
Lesson 5 – White space is important
After NULL values, this is probably the most common reason for lost debugging time (at least in my case): white space characters. SQL Server ignores white space if the data type is (n)varchar, but it doesn’t when (n)char is used. However, Integration Services (SSIS) doesn’t always ignore white space, especially in the Lookup component. The Lookup is white space and case sensitive, so it can happen that you expect a match, but the row is sent to the no match output. By just inspecting the column values visually, it’s not always obvious white space characters are involved!
Before you configure your lookup component, it’s a good idea to trim the columns. You can use the T-SQL functions LTRIM, RTRIM or TRIM, but SSIS has equivalent functions available in the derived column transformation. TRIM has the advantage that you can also use it to remove other characters as well. Keep in mind, it’s not only the actual space character, but also control characters, carriage returns, etcetera. The first 32 characters in the ASCII table are potential white space troublemakers.
Another trick to avoid issues in the Lookup component is to cast all string columns to upper case, just to make sure there are no troubles with the case.
Next Steps
- There are plenty of learning resources on MSSQLTips.com. Check out the webinars and tutorials for example.
- If you’re looking for more Business Intelligence tips, check out this list.

Koen Verbeeck is a seasoned business intelligence consultant with over a decade of experience with the Microsoft Data Platform. He holds several certifications, including Azure Data Engineer. He’s a prolific writer, with over 375 articles on technologies such as Microsoft Fabric, SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at various events such as PASS, SQLBits, dataMinds Connect and many others. He frequently delivers educational webinars on MSSQLTips.com. For his efforts, Koen has been awarded the Microsoft MVP data platform award for many years.
- MSSQLTips Awards:
- Leadership Award (200+ Tips) – 2021
- Author of the Year – 2014/2020/2022
- Author Contender – 2024/2025

