Problem
I want to load data from different flat files stored in Azure Blob Storage to an Azure SQL Database. However, I only want to process new files. Files which already have been processed should be ignored. I cannot just delete them, since they are used by other processes as well. Can I achieve this requirement with Azure Data Factory?
Solution
With Azure Data Factory (ADF), we can copy data from a source to a destination (also called sink) using the Copy Data activity. In the source settings of this activity we can see there are a modified start and end datetime we can use to filter the files.

The question is: what do we need to enter in those text boxes? Luckily, ADF provides us with a wizard and a template to help us get started.
The Azure Data Factory Copy Data Tool
The Copy Data Tool provides a wizard-like interface that helps you get started by building a pipeline with a Copy Data activity. It also allows you to create dependent resources, such as the linked services and the datasets (for more information about these concepts, check out this tip – Azure Data Factory Overview).
In this tip, we’ll load data from a CSV file into a table in Azure SQL DB. The sample files can be downloaded here, while the destination table can be created with the following DDL statement:
CREATE TABLE [dbo].[topmovies]( [Index] [BIGINT] NULL, [MovieTitle] [NVARCHAR](500) NULL );
On the home page of ADF, choose Copy data.

In the first screen, name the task. This will be the name of the pipeline later on. You also need to choose a schedule. For incremental load to work, you need to choose a regularly schedule. A one-time run will not work and any configurations for incremental load will be disabled in the later steps.

Regarding the schedule, you can either choose between a “normal schedule” as the trigger type, or a tumbling window. Here we can see a regular schedule:

And here we have a tumbling window:

The tip Create Tumbling Window Trigger in Azure Data Factory ADF dives a bit deeper into tumbling windows and the difference with a schedule trigger.
In the next screen, you can choose between existing linked services, or the option to create a new one. If you don’t have a connection to Azure Blob Storage, you need to create it here. An example is given in the tip Transfer On-Premises Files to Azure Blob Storage.

Once the connection to Azure Blob Storage is created, you need to specify the location of the files you want to copy:

In the same screen, you can also specify the loading behavior. In our case, we definitely want the “Incremental load: LastModifiedDate” option.

If you’ve chosen a regular schedule, you can see the start and end of the window.

In the example above, the schedule runs every 24 hours, so every file with a modified date between the schedule time and the schedule time minus 24 hours will be picked up by ADF. In the case of a tumbling window, no parameters are shown. They’ll show up in a later step though.

As the last step in the source configuration, you need the file format. If you’ve specified a folder or a specific file, you can choose the Detect text format, which will detect the settings for you and render a preview of the file at the bottom.

On the other hand, if you specified a wildcard pattern, such as myfolder/*.csv, you’ll get an error message:

In step 3 of the wizard, we’ll configure the destination. Choose Azure SQL DB from the list of available linked services, or create a new connection.

In the next step, choose the destination table:

If the metadata is known from the source file, the columns are mapped automatically onto those of the table:

For a tumbling window, you can find the window parameters here. In step 4 of the copy data tool, you can specify a couple of data movement settings. You can leave everything to the default settings.

Step 5 gives you an overview of the to-be generated pipeline:

In the last step, everything is created and published to the ADF environment:

If we take a look at the Copy Data activity in the generated pipeline, we can see the tumbling window parameters are filled in in the source settings:

The first time the pipeline runs, it will only pick up files if there’s a modified data after the start date of the schedule. Files already present will be ignored.

If a new file is added to the blob container, it will be picked up in the next run:

Using an Azure Data Factory Pipeline Template
Another option to create a pipeline with this incremental load pattern is using a template. On the home page, choose Create pipeline from template.

In the template gallery, choose the Copy new files only by LastModifiedDate template.

On the next screen, you can choose the source and the destination connections. A big difference with the Copy Data Tool is the template only supports binary sources, which rules out Azure SQL DB as a destination.
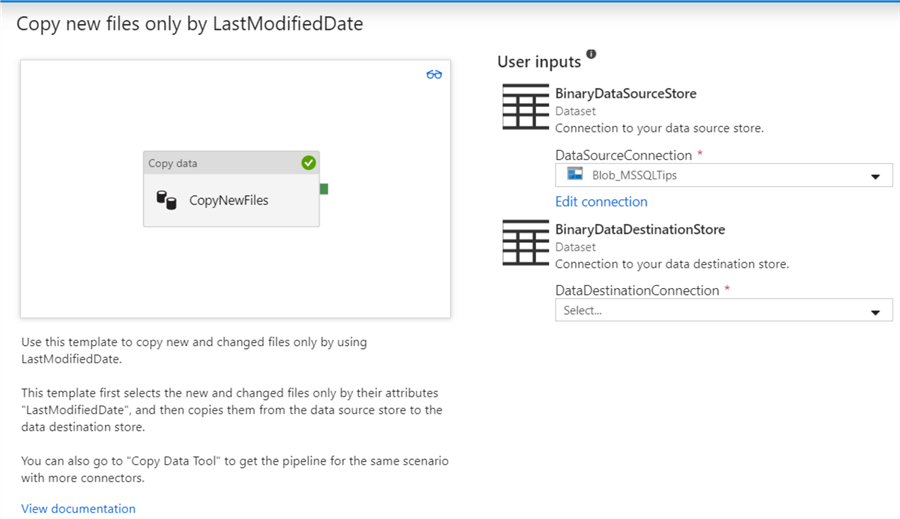
The template will create a pipeline with a Copy Data activity, together with a bunch of pipeline parameters:

It’s up to the user to build a framework using this pipeline and parameters in order to implement the incremental load pattern.
Conclusion
In Azure Data Factory, we can copy files from a source incrementally to a destination. This can either be achieved by using the Copy Data Tool, which creates a pipeline using the start and end date of the schedule to select the needed files. The advantage is this setup is not too complicated. The disadvantage is that if files already exist before the schedule starts, they are not copied to the destination. Or, if you want to reload all files, you have to change the schedule (tumbling windows deal best with this scenario) or by re-copying the files so their modified date changes.
The other option is using the template. This sets the foundation of the incremental load pattern, but leaves everything else to the developer. The advantage is you can probably build this out to a more flexible framework than the one used by the Copy Data Tool.
Next Steps
- If you want to follow along, you can find the sample data here.
- There are already quite some tips on Azure Data Factory on the MSSQLTips website. You can find an entire list here.
- For more Azure tips, check out these articles.

Koen Verbeeck is a seasoned business intelligence consultant with over a decade of experience with the Microsoft Data Platform. He holds several certifications, including Azure Data Engineer. He’s a prolific writer, with over 375 articles on technologies such as Microsoft Fabric, SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at various events such as PASS, SQLBits, dataMinds Connect and many others. He frequently delivers educational webinars on MSSQLTips.com. For his efforts, Koen has been awarded the Microsoft MVP data platform award for many years.
- MSSQLTips Awards:
- Leadership Award (200+ Tips) – 2021
- Author of the Year – 2014/2020/2022
- Author Contender – 2024/2025


Hi Koen,
Thanks for the reply. I knew that I had saw it elsewhere but being new and not having any documentation I just could not recall where it was.
Hi Bill,
they indeed changed the user interface of the copy data tool. If you want the file loading behavior dropdown, you need to select “schedule” in the first step, instead of “run once now”.
Regards,
Koen
Something is missing when browsing for the File or Folder… In the latest Copy Data Tool Template, the Load Behavior option is not available.
If I only select the Folder, and error is encountered on the next step because the blob cannot be found. If I enter a File with a Wildcard, the same error is encountered.
Not sure what I am missing. The Load Behavior option is not available on the Browse for File or Folder Screen.
Please help. I am a total newb at this and I am losing time.
Hi,
I haven’t tried this myself, but what if you map for file3 (which seems to have all columns)? Hopefully the other files will load as well and have NULL values for the extra columns.
Koen
I want to load files from blob storage to azure SQL database in single table. But some files column increases And it will
through error on that files . And i want to load all files with their column in single azure sql table .How i can increase the table column that all files data copy on single column?
file1 column:
ID,name,age
file2 column:
ID,name,age,Gender
file3 column:
ID,name,age,Gender,Father_name
Hi Santosh,
I touch a bit on the subject in this tip:
https://www.mssqltips.com/sqlservertip/5962/send-notifications-from-an-azure-data-factory-pipeline–part-2/
Its awesome.
One request , If possible than please publish a blog about error/exception handling in ADF
Hi SK,
you can modify your existing pipelines to work with parameters, as shown in the template.
It’s up to you to store the values of the last run, so when the pipeline starts executing, it can retrieve the previous values and only pick up files that have not yet been processed.
Regards,
Koen
Thanks for this thread. How we will be doing the same thing in already existing pipeline . Like can we do that in copy data in pipelines or we have to create ony either of above 2 ways. I have a pipeline which i will be scheduling and every time it should pick the last modified files which is like current month -4 and it will create 4 files due to data size constraints for -4 months data . So it should read recent 4 files created and loaded to the next layer in azure and subsequently to sql db. Thanks in advance