By: Eric Blinn | Comments | Related: 1 | 2 | 3 | 4 | 5 | 6 | 7 | > TSQL
Problem
I built a query that utilizes a subquery that needs to be compared back to a main query. I want to know how to best achieve this task. Should I use an IN statement? An EXISTS? Or maybe a JOIN? I need to know which options will be valid for my use case and which one will perform the best. I also need to be able to prove it.
Solution
As with many situations within SQL Server the answer depends on the circumstances. This tip will look at the pros and cons of each method and use a repeatable methodology to determine which method will offer the fastest performance. The best part about this tip is that the performance comparison methodology can be applied to any TSQL coding situation!
Compare SQL Server EXISTS vs. IN vs JOIN T-SQL Subquery Code
All of the demos in this tip will use the WideWorldImporters sample database which can be downloaded for free from here and will be run against SQL Server 2019. The images might be different, but the methodology should still work on older versions of SQL Server.
The subquery to be used will be a list of the top 3 sales people for a single quarter based on invoice count. For the simplicity of the example queries, this subquery will be stored as a view. As seen in this tip, for a simple query like this one, there likely isn't a difference in performance between using a view, CTE, or traditional subquery.
CREATE VIEW vTop3SPs2013Q2 AS SELECT TOP 3 SalespersonPersonID FROM Sales.Invoices WHERE InvoiceDate BETWEEN '4/1/2013' AND '6/30/2013' GROUP BY [SalespersonPersonID] ORDER BY COUNT(*) DESC
SQL IN Code
The IN statement can be used to find rows in a query where one column can be matched to a value in a list of values. The list of values can be hard coded as a comma-separated list or can come from a subquery as it does in this example.
IN statements are easy to write and understand. The only downside is that they can only compare a single column from the subquery to a single column from the main query. If 2 or more values need to be compared then the IN statement cannot be used.
Below is a query that returns some invoices that belonged to our top group of salespeople. Notice that the subquery returns exactly one row. This is a requirement for use of the IN statement. Also note that the query inside the parentheses is a fully functional query on its own. It can be highlighted and executed by itself.
SELECT Invoices.InvoiceID, Invoices.TotalDryItems, People.FullName FROM Sales.Invoices INNER JOIN [Application].People ON Invoices.SalespersonPersonID = People.PersonID WHERE SalespersonPersonID IN (SELECT SalespersonPersonID FROM vTop3SPs2013Q2) AND InvoiceDate BETWEEN '4/1/2013' AND '6/30/2013' AND TotalDryItems >= 4;
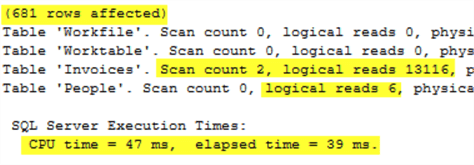
Executing that query with both STATISTICS IO and STATISTIC TIME enabled, outputs this information. This output will give us some metrics for performance to compare to the other options. If unfamiliar with how to get this output, please consult this tip.
SQL EXISTS Code
The EXISTS statement functions similarly to the IN statement except that it can be used to find rows where one or more columns from the query can be found in another data set, usually a subquery. Hard coding isn't an option with EXISTS.
Below is the same query as above except that the IN has been replaced by EXISTS. The format for EXISTS and its subquery is a little bit different than for IN. In this case, the subquery references a column, I.SalespersonPersonID, that does seem to be available to the subquery. For this reason, the subquery cannot be executed on its own and can only be executed in the context of the entire query. This can sometimes be difficult to understand.
Logically, think of it as having the subquery run once for every row in the main query to be determined if a row exists. If a row exists upon executing the subquery, then the Boolean return value is true. Otherwise, it is false. The selected column(s) of the subquery does not matter as the result is tied only to the existence or non-existence of a row based on the FROM/JOIN/WHERE clauses in the subquery.
SELECT I.InvoiceID, I.TotalDryItems, People.FullName FROM Sales.Invoices I INNER JOIN [Application].People ON I.SalespersonPersonID = People.PersonID WHERE EXISTS (SELECT 1 FROM vTop3SPs2013Q2 WHERE SalespersonPersonID = I.SalespersonPersonID) AND I.InvoiceDate BETWEEN '4/1/2013' AND '6/30/2013' AND I.TotalDryItems >= 4;
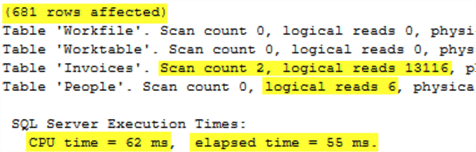
Executing this query returns the following statistical output which is virtually identical to the IN statement.
SQL INNER JOIN Code
A regular JOIN can be used to find matching values in a subquery. Like EXISTS, JOIN allows one or more columns to be used to find matches. Unlike EXISTS, JOIN isn't as confusing to implement. The downside to JOIN is that if the subquery has any identical rows based on the JOIN predicate, then the main query will repeat rows which could lead to invalid query outputs. Both IN and EXISTS will ignore duplicate values in a subquery. Take extra precaution when joining to a table in this fashion. In this example, the view will not return any duplicate SalespersonPersonID values, so it is a safe implementation of a JOIN.
SELECT I.InvoiceID, I.TotalDryItems, People.FullName FROM Sales.Invoices I INNER JOIN [Application].People ON I.SalespersonPersonID = People.PersonID INNER JOIN vTop3SPs2013Q2 ON I.SalespersonPersonID = vTop3SPs2013Q2.SalespersonPersonID WHERE InvoiceDate BETWEEN '4/1/2013' AND '6/30/2013' AND TotalDryItems >= 4;
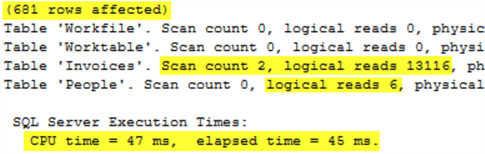
Executing this query returns the following statistical output which is, once again, virtually identical to the IN and EXISTS statement versions of the query.
Why are all of the statistics the same?
The statistics for each of these 3 options are virtually identical because the optimizer is compiling all 3 options into the same query plan. This can be seen by running all three queries together while viewing the actual execution plans. The screenshot below shows one plan, but the exact same plan appears in each of the 3 query options.

Each copy of the query plan shows a missing index recommendation. Acting on that recommendation and creating the index will modify the plans and query performance statistics. Will it modify them all the same way? Let's find out. First, make the index, then rerun the 3 queries.
CREATE NONCLUSTERED INDEX mssqltips ON [Sales].[Invoices] ([InvoiceDate],[TotalDryItems]) INCLUDE ([InvoiceID],[SalespersonPersonID]);
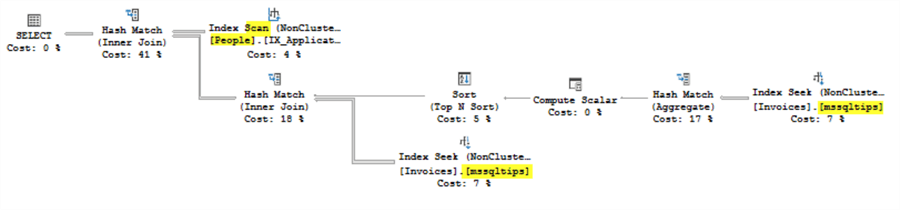
Now execute all 3 statements together again. Something interesting happens. All 3 plans have changed from the versions they were before the index creation, but they are not identical this time. The IN and EXISTS got the same new plan, but the JOIN gets a different plan.
The plan for the IN and EXISTS used the new index twice and performed a SEEK on the People table.

This plan was generated for the JOIN version of the query. It used the new index twice, but performed a SCAN on the people table.
Checking the IO and TIME statistics for the 3 queries shows identical statistics for the 2 queries that shared a plan, but improved statistics and execution time for the JOIN version. If this were a query getting ready to be promoted to production, going with the JOIN would probably be the best bet.

Conclusion
This query is a great example that while the optimizer strives to treat each option the same, it won't always do that. Using this performance verification methodology, along with understanding the value and limitations of each query option, will allow the programmer to make the best choice in each situation.
Next Steps
- Check out this tip that uses the same methodology to compare subquery types
- This tip shows how to use STATISTICS TIME and STATISTICS IO with more detail
- This tip covers how to read visual query plans.
- Check out this Performance Tuning Tutorial






About the author
 Eric Blinn is the Sr. Data Architect for Squire Patton Boggs. He is also a SQL author and PASS Local Group leader.
Eric Blinn is the Sr. Data Architect for Squire Patton Boggs. He is also a SQL author and PASS Local Group leader.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
