Problem
We use databases to store information in tables. Once the data is written to those tables, often the need arises to update certain fields during the lifetime of the data. In the SQL language, we can use the UPDATE statement to achieve this goal. In this tutorial we cover several different examples of how to use the UPDATE statement.
Solution
In this tip, we’ll show you how you can use the T-SQL UPDATE statement to update data in a database table. We’ll be using the AdventureWorks 2017 sample SQL database. If you want to follow along, you can download the sample database and restore it on your system. You can copy paste the queries and execute them on your machine using Microsoft SQL Server Management Studio (SSMS).
Simple UPDATE SQL Syntax
A simple UPDATE statement can take the following format:
UPDATE Table SET Column = <some expression>;
Update a Single Column
Let’s look at fictitious example where [SickLeaveHours] is the column name with the INT data type in the [HumanResources].[Employee] table. The [SickLeaveHours] is set to 0, which is the set clause to update the existing records. Here is the sample Transact-SQL code:
UPDATE [HumanResources].[Employee]
SET [SickLeaveHours] = 0;
This will set all the rows of the existing data for the column SickLeaveHours in the Employee table to the value 0. You can also use an expression that references the column itself. In this example, we’re enhancing the VacationHours column with 10%.
UPDATE [HumanResources].[Employee]
SET [VacationHours] = [VacationHours] * 1.1;
When the UPDATE statement is executed, SQL Server will take the current value of each row and multiply it with 1.1. The result will be stored in the column. When you execute the statement in SSMS, the messages tab will display how many rows were updated by the statement:

Update Examples for Multiple Columns
You can also update multiple columns at once, by separating the columns with a comma. In this statement, we also update the ModifiedDate column of the table:
UPDATE [HumanResources].[Employee]
SET [VacationHours] = [VacationHours] * 1.1
,[ModifiedDate] = GETDATE();
It’s possible to reference columns of the same table, while they are being updated as well. Let’s say for example we are resetting all vacation hours to zero. At the same time, the sick leave hours are updated based on the current value of the vacation hours.
UPDATE [HumanResources].[Employee]
SET [VacationHours] = 0
,[SickLeaveHours] = IIF([VacationHours] < 10, 0, 25);
If SQL Server would update the VacationHours column first, you might assume that the SickLeaveHours column will also contain only zeroes, based on the expression (for more info about IIF and CASE, check out the tip SQL Server T-SQL CASE Examples). This is not the case though, the database engine updates both columns simultaneously, so the expression for the sick leave hours uses the values that were present in the VacationHours column before the UPDATE statement.

Updating a Subset of Rows
In many cases, you don’t want to update the entire table, but only certain rows. You can accomplish this by adding a WHERE clause to your UPDATE statement.
UPDATE myTable SET myColumn = <some expression> WHERE <Boolean expressions>;
Every row where the WHERE condition returns true will be updated; other rows will simply be skipped. The principle is the same as a WHERE condition in a SELECT statement (for more info, see the tip SQL Server SELECT Examples). We can for example update the sick hours only if they’re smaller than 10 (instead of using the IIF function as we did in the previous example):
UPDATE [HumanResources].[Employee]
SET [SickLeaveHours] = 0
WHERE [SickLeaveHours] < 10;
In general, it’s a best practice to restrict the rows you want to update, for performance reasons but also to avoid overwriting data that shouldn’t have been updated. When running an UPDATE query on a production server, you don’t want to forget your WHERE clause.
Updating a Single Table with Data from Multiple Tables
In the previous section, the new column values were either hardcoded or we used expressions on the columns of the table itself. It’s also possible to use data from other tables as well. We can do this by adding the FROM clause to the UPDATE statement. We can join the table we want to update with the other tables, and then we can use the columns of those other tables to update the original table. A skeleton query could look like this:
UPDATE t1
SET myColumn = <some expression using columns from t1 and t2>
FROM myTable t1<br />JOIN otherTable t2 ON t1.keycolumn = t2.keycolumn
WHERE <Boolean expressions>;
The first table in the FROM clause is the table we want to update. The alias t1 is assigned to this table. Then we join it against another table, with the alias t2. What’s important to notice is that after the UPDATE keyword, the alias t1 is used to indicate which table we want to update, instead of using the full table name.
In this example, we are giving our recently hired employees two extra days of vacation. We can do this by joining the Employee table with the JobCandidate table.
UPDATE e
SET [VacationHours] = e.[VacationHours] + 2
FROM [HumanResources].[Employee] e
JOIN [HumanResources].[JobCandidate] jc ON [jc].[BusinessEntityID] = [e].[BusinessEntityID];
No WHERE clause is needed, as the INNER JOIN already filters the data we need for the query. In some cases, where the logic becomes more complex, you might need to resort to subqueries or common table expressions (CTE). For example, the following query returns an error since you cannot directly aggregate in the SET list of the UPDATE statement.
UPDATE sh
SET [SubTotal] = SUM(sd.[UnitPrice] * sd.[OrderQty])
FROM [Sales].[SalesOrderHeader] sh
JOIN [Sales].[SalesOrderDetail] sd ON [sd].[SalesOrderID] = [sh].[SalesOrderID]
WHERE sh.[SalesOrderID] = 43659;

To work around this issue, a CTE can be used to pre-calculate the aggregate:
WITH CTE_agg AS
(
SELECT [SalesOrderID], Subtotal = SUM([UnitPrice] * [OrderQty])
FROM [Sales].[SalesOrderDetail]
WHERE [SalesOrderID] = 43659
GROUP BY [SalesOrderID]
)
UPDATE sh
SET [SubTotal] = c.[Subtotal]
FROM [Sales].[SalesOrderHeader] sh
JOIN CTE_agg c ON c.[SalesOrderID] = [sh].[SalesOrderID];
Testing your UPDATE Statement
Since you’ll be overwriting data, you might want to make sure the UPDATE statement does what it is intended to do. There are two options for quick testing:
- Using a transaction
- Inserting a SELECT
Using a Transaction
With the first option, you surround the UPDATE query with an explicit transaction:
BEGIN TRAN; UPDATE Table SET Column = <some expression> WHERE <Boolean expressions>; COMMIT;
ROLLBACK;
You run the BEGIN TRAN statement along with the UPDATE statement. This will update the data in the table inside the current transaction context. You can check the data in the table to verify everything is updated correctly. If this is the case, you can execute the COMMIT statement to commit the transaction or you can use the ROLLBACK statement to roll back the transaction and undo the changes to the table.
Using the query from the previous example, we get this script:
BEGIN TRAN;
WITH CTE_agg AS
(
SELECT [SalesOrderID], Subtotal = SUM([UnitPrice] * [OrderQty])
FROM [Sales].[SalesOrderDetail]
WHERE [SalesOrderID] = 43659
GROUP BY [SalesOrderID]
)
UPDATE sh
SET [SubTotal] = c.[Subtotal]
FROM [Sales].[SalesOrderHeader] sh
JOIN CTE_agg c ON c.[SalesOrderID] = [sh].[SalesOrderID];
SELECT [SubTotal]
FROM [Sales].[SalesOrderHeader]
WHERE[SalesOrderID] = 43659;
ROLLBACK;
COMMIT;
To test this, we run this part first:

If the result is what we expect, the COMMIT statement can be executed, otherwise we select ROLLBACK and execute that line of code. As long as neither of those statements is run, the transaction is open and the changed data is not persisted. More info can be found in What is a transaction?.
Using a Select Statement
The other option is to insert a SELECT into the UPDATE statement and “hide” it using comments. To test the query, we select only the relevant portion to see the data that is going to be changed. For example:
UPDATE e
SET [VacationHours] = e.[VacationHours] + 2
-- SELECT *
FROM [HumanResources].[Employee] e
JOIN [HumanResources].[JobCandidate] jc ON [jc].[BusinessEntityID] = [e].[BusinessEntityID];
To test this query, we select everything right after the double dash and execute it:

With this trick, you can quickly inspect which rows are going to be updated, as long as the UPDATE statement has a FROM clause.
Updating a View
In all of the examples we have used physical tables to update. But SQL Server also allows you to update data through a view. There are a couple of prerequisites to have an updateable view:
- The UPDATE statement can only reference columns from one base table. This means it’s not possible to update multiple tables at once using a single UPDATE statement.
- The view columns that are modified must directly reference the data of the base table. This means an aggregation function cannot be used, or any other expression using other columns. Using UNION (ALL) or other set operators are also prohibited.
- There’s no ORDER BY, GROUP BY, HAVING or DISTINCT.
- TOP is not used together with the WITH CHECK OPTION clause.
You can find more info on the prerequisites in the documentation. To illustrate with an example, we’re going to use the HumanResources.vEmployee view of the Adventure Works database. This view has the following definition which is based on a SELECT query:
CREATE VIEW [HumanResources].[vEmployee] AS
SELECT
e.[BusinessEntityID]
,p.[Title]
,p.[FirstName]
,p.[MiddleName]
,p.[LastName]
,p.[Suffix]
,e.[JobTitle]
,pp.[PhoneNumber]
,pnt.[Name] AS [PhoneNumberType]
,ea.[EmailAddress]
,p.[EmailPromotion]
,a.[AddressLine1]
,a.[AddressLine2]
,a.[City]
,sp.[Name] AS [StateProvinceName]
,a.[PostalCode]
,cr.[Name] AS [CountryRegionName]
,p.[AdditionalContactInfo]
FROM [HumanResources].[Employee] e
INNER JOIN [Person].[Person] p
ON p.[BusinessEntityID] = e.[BusinessEntityID]
INNER JOIN [Person].[BusinessEntityAddress] bea
ON bea.[BusinessEntityID] = e.[BusinessEntityID]
INNER JOIN [Person].[Address] a
ON a.[AddressID] = bea.[AddressID]
INNER JOIN [Person].[StateProvince] sp
ON sp.[StateProvinceID] = a.[StateProvinceID]
INNER JOIN [Person].[CountryRegion] cr
ON cr.[CountryRegionCode] = sp.[CountryRegionCode]
LEFT OUTER JOIN [Person].[PersonPhone] pp
ON pp.BusinessEntityID = p.[BusinessEntityID]
LEFT OUTER JOIN [Person].[PhoneNumberType] pnt
ON pp.[PhoneNumberTypeID] = pnt.[PhoneNumberTypeID]
LEFT OUTER JOIN [Person].[EmailAddress] ea
ON p.[BusinessEntityID] = ea.[BusinessEntityID];
As you can see, the view adheres to the prerequisites. This means we can run the following UPDATE statement:
UPDATE [HumanResources].[vEmployee]
SET [Title] = 'Testing'
WHERE [BusinessEntityID] = 255;
We can indeed see the data has changed:
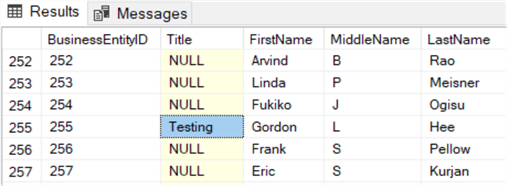
The prerequisites mention a single base table, but the view has several tables joined together using INNER JOINs. This means you can also update columns from other tables, such as the Person.Address table for example.
UPDATE Tips and Tricks
- If you want to update multiple tables at the same time – which is not possible in a single UPDATE statement – and you want to make sure they all succeed or fail together, you need to use explicit transactions.
- You can however update, delete and insert rows at the same time using the MERGE statement. The tip Using MERGE in SQL Server to insert, update and delete at the same time explains the concept. However, the MERGE statement can be buggy, so make sure to read Use Caution with SQL Server's MERGE Statement as well.
- Running a large UPDATE statement can be a costly process. Not only does SQL Server need to update the data, but also keep locks on the table and update the transaction log. To speed up large updates, you can use a batching strategy. The tip Optimize Large SQL Server Insert, Update and Delete Processes by Using Batches provides you with more detail. The tip UPDATE Statement Performance in SQL Server also gives more info about the performance aspect.
- You can use @@rowcount to programmatically determine how many rows you’ve updated.
- You can use the UPDATE SQL statement at any location where you can run SQL scripts. So not only in SQL Server Management Studio, but also in stored procedures, Integration Services, sqlcmd, PowerShell, Azure Data Factory, SQL Server Agent and so on.
Next Steps
- You can learn more about T-SQL DML code:
- SELECT statement in this SQL tutorial
- Learn about SQL DELETE code
- INSERT INTO SQL Server Command
- MERGE Logic
- The tip Insert and Delete SQL Server Data with Views uses the concept of updateable views for inserting and deleting data from tables.
- The tip SQL Update Statement with Join in SQL Server vs Oracle vs PostgreSQL compares how you can use the FROM clause in an UPDATE statement in different database engines.
- Learn about the SQL DROP TABLE and TRUNCATE TABLE commands.

Koen Verbeeck is a seasoned business intelligence consultant with over a decade of experience with the Microsoft Data Platform. He holds several certifications, including Azure Data Engineer. He’s a prolific writer, with over 375 articles on technologies such as Microsoft Fabric, SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at various events such as PASS, SQLBits, dataMinds Connect and many others. He frequently delivers educational webinars on MSSQLTips.com. For his efforts, Koen has been awarded the Microsoft MVP data platform award for many years.
- MSSQLTips Awards:
- Leadership Award (200+ Tips) – 2021
- Author of the Year – 2014/2020/2022
- Author Contender – 2024/2025

Very good blog