Problem
Sparse columns were added with SQL Server 2008 as a new feature that helps save space when columns have a high ratio of NULL values. We have a couple of very large and wide tables with Nullable columns and most of them don’t have data. We’d like to take advantage of sparse columns to save space. We ran SSIS (SQL Server Integration Services) Data Profiling Task to find sparse columns candidates (Null Ratio profile). With more than 500 candidate columns it will be hard to review and alter each column individually. How can we use the SSIS Data Profiling output XML file? Can we generate a script to modify columns based on Data Profiling output and apply to this script sparse columns requirements/restrictions?
Solution
As per this Microsoft article you can: “Consider using sparse columns when the space saved is at least 20 percent to 40 percent.” The same article has a table that provides estimated space saving by data types.
In our example below we will consider only columns that have at least 60% of Nullable columns. To check if a column is already set as sparse we can query sys.columns system catalog view (is_sparse or is_column_set columns):
SELECT [name] AS column_name, is_sparse, is_column_set <br /> FROM sys.columns <br /> WHERE OBJECT_NAME(object_id) = 'sparce_tbl_test' -- table name<br /> AND (is_sparse = 1 OR is_column_set = 1)
There are some limitations for the columns that might be converted to sparse. We will include most of these restrictions as filters in our solution/script. We will create a test table with nullable columns and populate this table with some data. Then, we will run SSIS Data Profiling Task to estimate Null Ratio in our columns.
Create and Populate Test Table
We will use this table to use for our tests and to create and test a demo script. Note, that indexes created only for the sparse columns limitations demonstration:
CREATE TABLE [dbo].[sparce_tbl_test](<br /> [col1] [int] IDENTITY(1,1) NOT NULL,<br /> [col2] [varchar](20) NOT NULL,<br /> [col3] [varchar](20) NULL,<br /> [col4] [varchar](20) NULL,<br /> [col5] [varchar](20) NULL,<br /> [col6] [varchar](20) NULL,<br /> [col7] [varchar](20) NULL,<br /> [col8] [int] NULL,<br /> [col9] [int] NULL,<br /> [col10] [int] NULL,<br /> [col11] [int] NULL<br />) ON [PRIMARY]<br />GO <br /><br />CREATE CLUSTERED INDEX [CLIX_sparce_tbl_test] ON [dbo].[sparce_tbl_test] ([col8] ASC)<br />GO<br />CREATE NONCLUSTERED INDEX [NCLIX_sparce_tbl_test_1] ON [dbo].[sparce_tbl_test] ([col10] ASC)<br />GO
We will populate the first two columns with some data:
SET NOCOUNT ON<br />GO<br />INSERT INTO dbo.sparce_tbl_test (col2,col3) SELECT CAST(RAND() AS VARCHAR(20)),' c3'<br />GO 10<br />INSERT INTO dbo.sparce_tbl_test (col2) SELECT CAST(RAND() AS VARCHAR(20)) <br />GO 20000
SSIS Data Profiling Task
Now we will create SSIS package and run the SSIS Data Profiling Task to estimate Null values percentage in our test table.
Here are high-level steps:
- Create the new SSIS package under the new or existing SSIS solution
- Add “Data Profiling Task” from the SSIS Toolbox to the package’s Control Flow:

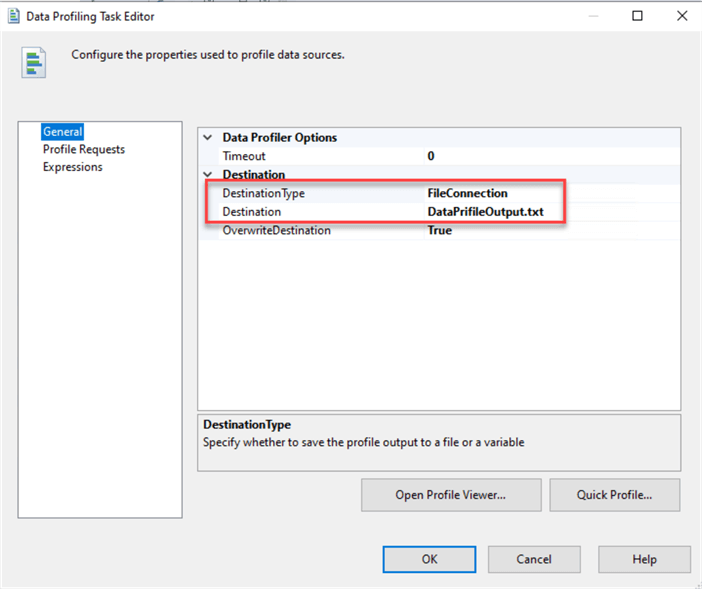
- Configure SSIS Destination (file that will have XML output with results of the Data Profiling):
- We’ll configure Profile by clicking on “Quick Profile…” button and selecting to compute only “Column Null Ratio Profile”:

- And after configuring and running a “Quick Profile” we will have Request configuration that has SQL Server name, database name, and our test table name:

The “ConnectionManager” will be our SQL Server and database, “TableOrView” – the sparse candidate table and all columns (*) as the “Column” property.
This tip has more details on how to configure and run SSIS Data Profiling Task (mssqltips.com).
After executing the SSIS package we can see in a Data Profile Viewer that all columns except col1 and col2 might be good candidates for converting to the sparse columns:

You can also identify columns qualified for the sparse columns conversion by using the T-SQL script as described in this tip.
Using Data Profiling Output File
During Data Profiling Task configuration in SSIS we specified the Destination file:

This file has an XML structure, and we will use it in our script to analyze the output.
We will join XML output with System Catalog Views that contain information about columns, indexes, and data types (sys.columns, sys.indexes, sys.index_columns, and sys.types).
Note, that the output file should be located on a server from where we run our script. In our case we copied it over from SSIS server to the SQL Server with our “db_sparse_test” database to this location: “C:\temp\DataProfileOutput.txt”. We will use this location in our script below.
We will also incorporate in our query some filters that will return qualified columns based on the sparse columns restrictions:
USE db_sparse<br />GO<br /><br />DECLARE @profiles xml<br /> <br />SELECT @profiles = P<br />FROM OPENROWSET (BULK 'C:\temp\DataProfileOutput.txt', SINGLE_BLOB) AS Profiles(P)<br /> <br />DECLARE @hdoc int<br /> <br />EXEC sys.sp_xml_preparedocument @hdoc OUTPUT, @profiles, N'<root xmlns_xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns_xsd="http://www.w3.org/2001/XMLSchema" xmlns_d="http://schemas.microsoft.com/sqlserver/2008/DataDebugger/"/>'<br /><br />;WITH dp AS <br />(SELECT * FROM OPENXML(@hdoc, N'/d:DataProfile/d:DataProfileOutput/d:Profiles/d:ColumnNullRatioProfile/d:Column') <br /> WITH ( <br /> [Schema] VARCHAR (200) '../d:Table/@Schema',<br /> [Table] VARCHAR (200) '../d:Table/@Table',<br /> [ColName] VARCHAR(100) '@Name' , <br /> [RowCount] INT '../d:Table/@RowCount',<br /> [NullCount] INT '../d:NullCount')<br /><br /> )<br />SELECT DISTINCT dp.* , <br /> NullCount*100.0/[RowCount] PercentOfNullable, <br /> t.[name] data_type_name, <br /> c.max_length, <br /> c.[precision], <br /> c.scale, <br /> CASE WHEN ISNULL(ic.index_id, 0) <> 0 THEN '-- ' ELSE '' END +<br /> 'ALTER TABLE dbo.' + dp.[Table] + ' ALTER COLUMN ' + dp.[ColName] + ' ' + t.[name] +<br /> CASE WHEN t.[name] LIKE '%char%' THEN '(' + CAST(c.max_length AS VARCHAR(20)) + ')' <br /> WHEN t.[name] = 'decimal' THEN '(' + CAST(c.[precision] AS VARCHAR(20)) + CAST(c.scale AS VARCHAR(20)) + ')' <br /> ELSE '' <br /> END<br /> + ' SPARSE NULL; ' AS AlterScriptSample,<br /> INDEXPROPERTY(ic.OBJECT_ID, i.name,'IsClustered') AS HasClusteredIndex, --A sparse column cannot be part of a clustered index or a unique primary key index.<br /> INDEXPROPERTY(ic.OBJECT_ID, i.name,'IsUnique') AS HasUniqueIndex, <br /> CASE WHEN ISNULL(ic.index_id, 0) <> 0 THEN 'Review indexes dependencies' <br /> ELSE '' END AS Notes<br />FROM dp JOIN sys.columns c <br /> ON dp.[Schema] = OBJECT_SCHEMA_NAME(c.object_id) <br /> AND dp.[Table] = OBJECT_NAME(c.object_id) AND dp.[ColName] = c.[name]<br /> JOIN sys.partitions p <br /> ON c.object_id = p.object_id<br /> JOIN sys.types t <br /> ON c.system_type_id = t.system_type_id <br /> LEFT JOIN sys.index_columns ic <br /> ON c.object_id = ic.object_id AND c.column_id = ic.column_id<br /> LEFT JOIN sys.indexes i <br /> ON ic.object_id = i.object_id AND ic.index_id = i.index_id<br />WHERE NullCount*100.0/[RowCount] > 60 -- more than 60% of data has NULLs<br /> AND c.is_nullable = 1 -- only NULLable columns can be sparse <br /> AND t.[name] NOT IN ('geography', 'geometry', 'image', 'ntext', 'text' ,'timestamp') -- unsupported data types (can't be sparse)<br /> AND t.is_user_defined = 0 -- unsupported data types (can't be sparse)<br /> AND c.is_identity = 0 -- can't be sparse<br /> AND c.is_filestream = 0 -- can't be sparse<br /> AND c.is_rowguidcol = 0 -- can't be sparse<br /> AND c.rule_object_id = 0 -- can't be sparse<br /> AND c.default_object_id = 0 -- can't be sparse<br /> AND c.is_computed = 0 -- can't be sparse<br /> AND c.is_sparse = 0 -- already sparse<br /> AND p.data_compression_desc = 'NONE' -- table can't be compressed<br />ORDER BY 11 DESC; <br />EXEC sys.sp_xml_removedocument @hdoc
After applying these rules we have got the results below:
- Only Nullable columns will be displayed as candidates to the sparse columns conversion
- Some data types (including user-defined data types) can’t be used with the sparse columns
- Column cannot have the Filestream attribute
- Column cannot have the Identity property
- Column cannot have the Rowguidcol property
- Candidate columns cannot have rules or defaults bound to them
- We exclude columns that are already sparse
- Only return columns where 60% or more data has NULLs
- The table cannot be compressed
- Columns with indexes on them should be reviewed. The line with these columns in the script will be commented out. Some indexes might need to be dropped and re-created after the column conversion to sparse. Other indexes cannot be used with the sparse columns (see “restrictions” section of the Use Sparse Columns – SQL Server | Microsoft Docs).

Note, that we commented out part of the script where indexes have to be potentially dropped and recreated (or where additional review is required based on Microsoft’s article):
ALTER TABLE dbo.sparce_tbl_test ALTER COLUMN col9 int SPARSE NULL; <br />ALTER TABLE dbo.sparce_tbl_test ALTER COLUMN col7 varchar(20) SPARSE NULL; <br />ALTER TABLE dbo.sparce_tbl_test ALTER COLUMN col6 varchar(20) SPARSE NULL; <br />ALTER TABLE dbo.sparce_tbl_test ALTER COLUMN col5 varchar(20) SPARSE NULL; <br />ALTER TABLE dbo.sparce_tbl_test ALTER COLUMN col4 varchar(20) SPARSE NULL; <br />ALTER TABLE dbo.sparce_tbl_test ALTER COLUMN col3 varchar(20) SPARSE NULL; <br />ALTER TABLE dbo.sparce_tbl_test ALTER COLUMN col11 int SPARSE NULL; <br />-- ALTER TABLE dbo.sparce_tbl_test ALTER COLUMN col8 int SPARSE NULL; <br />-- ALTER TABLE dbo.sparce_tbl_test ALTER COLUMN col10 int SPARSE NULL;
Testing the Script with a Real Table
We ran the same process on our large table that has 581 columns.
After running SSIS Data Profiling Task only 13 columns had less than 60% of NULLs and 1 column didn’t qualify (had timestamp data type). The space used by the data (sp_spaceused) after converting columns to sparse dropped from 3,076 MB to 206 MB:

Note, that this script was tested with specific tables and data types. Make sure you run it in a Non-Production environment first and test dependent application(s) before making any changes in Production. Also, review additional sparse columns restrictions in this Microsoft’s article before altering columns.
Next Steps
- Read this tip: SQL Server Sparse Columns Identifying Columns For Conversion. This is another way (without SSIS) of finding sparse columns candidates.
- Check this blog SQL SERVER – Performance Benefit of Using SPARSE Columns? and find more links with sparse columns posts on the same page.

Svetlana has been working in IT for more than 17 years. Most of her career has focused on Database Administration (both SQL Server and Oracle) and Database Development. Databases are Svetlana’s passion, but she also has fun helping co-workers and friends in troubleshooting non-database related issues. Svetlana tries to explore and learn as many SQL Server features as possible. Her favorite SQL Server features are Policy Based Management, SSIS, SSRS and Master Data Services. One of Svetlana’s areas of expertize is cross systems / database integration. Svetlana is currently a hands-on Database Team Lead in Calgary, Canada where she promotes SQL Server.
Svetlana likes to share her knowledge with others and enjoys learning herself. Her hobby is photography, but now she spends her free time away from Database Administration with her little girl who proudly wears her MSSQLTips shirt. Svetlana blogs at http://databaserefresh.com and posts her pictures to https://plus.google.com/u/0/111115767149899859037/posts. Her Twitter account is @magasvs.
- MSSQLTips Awards: Rising Star (50+ tips) – 2018 | Author of the Year Contender – 2015-2017


