Problem
This tip is part of the series of posts, dedicated to the building of end-to-end Lakehouse solutions leveraging Azure Synapse Analytics. In the previous post (see Implementing Fact-to-Dimension Mapping on Lakehouse using Synapse Mapping Data Flow), we explored the ways to build surrogate key-based relationships between fact and dimension tables. Sometimes fact tables receive dimension keys before they become available in related dimension tables. This is called the late-arriving dimensions (or early arriving facts) problem. In this tip, we’ll discuss the ways to handle late-arriving dimensions.
Solution
There’re a few common methods of handling late arriving dimensions:
- Delete fact rows having unmatched dimension keys.
- Move fact rows having unmatched dimension keys into a separate landing table, and reprocess them later when those dimensions become available.
- Keep unmatched fact rows, and generate dummy dimension rows based on these keys. Typically, non-key attributes of those rows are marked as ‘unknown’ (see Late Arriving Dimensions for more details).
While each of these approaches has its pros and cons, I like the last approach, because it involves less reprocessing of fact tables. Accordingly, the solution described here covers approach #3.
The data preparation
The AdventureWorks database I’ve been using throughout this series has a star schema with tight foreign key relationships between fact and dimension tables. So, I’ll imitate the customer key mismatch scenario by executing the following commands on the source AdventureWorks database:
ALTER TABLE [SalesLT].[SalesOrderHeader] DROP CONSTRAINT [FK_SalesOrderHeader_Customer_CustomerID] GO UPDATE [SalesLT].[SalesOrderHeader] SET CustomerID=40000 WHERE SalesOrderID<=71776
Note that the new natural key selected here does not exist in the Customer table. Once these rows are updated, please run all the intermediate pipelines to fetch these changes to the SalesOrderHeader silver table.
The ETL pipeline design
The data flow we’re going to build will have the following high-level logic:
- Match dimension keys to existing dimensions, using natural keys.
- Replace non-empty natural keys with surrogate keys for those dimensions that have matches.
- Replace empty natural keys with the special surrogate key dedicated to an unknown dimension member.
- For the fact rows, that have unmatched natural keys, generate dummy dimension rows with those unmatched keys, mark other attribute values as ‘unknown’ and write them into the dimension table.
- Update ‘unknown’ attributes later when those dimension values arrive.
I’m going to use the data flow we’ve created in Implementing Fact-to-Dimension Mapping on Lakehouse using Synapse Mapping Data Flow, which already has the logic for steps 1-3, as a starting point. Here’s the design of this data flow:

Figure 1
We’ll enrich this solution with the components required for step #4. And step #5, will be covered by the dimension update logic that’s part of any dimension processing flow (see this post for an example).
First, let’s add a data source transformation reading from the DimCustomer gold table- we’ll need it to get the highest available surrogate key, that would be used for surrogate key calculation. Here’s the screenshot:
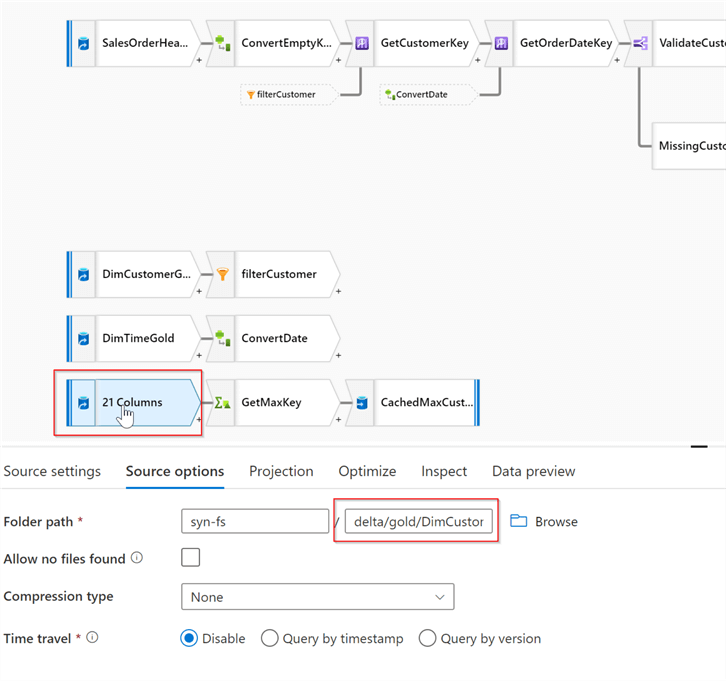
Figure 2
Next, add an aggregate transformation to the end of this stream, select the Aggregate button and provide the following expression, to calculate the highest available surrogate key:
MaxCustomerKey: max(CustomerKey)
Here’s the screenshot with the required settings:

Figure 3
Finally, add a sink transformation and select cache as a sink type, as follows:

Figure 4
The cache transformation will allow us to store the highest available surrogate key in memory- we’ll use it later when generating the new dimension rows.
Here is the result from the data validation screen:

Figure 5
Next, let’s select Select1 transformation and add a new fixed mapping for the CustomerID field, as follows:

Figure 6
At this point, we need to split a data stream into two sub-streams:
- Rows with the CustomerID keys having matches in the DimCustomer table
- Rows with the CustomerID keys having no matches in the DimCustomer table
There’re a few ways to achieve this split, but I’ll use Conditional split transformation for this purpose.
So, let’s add Conditional split transformation and configure two branches, as follows:
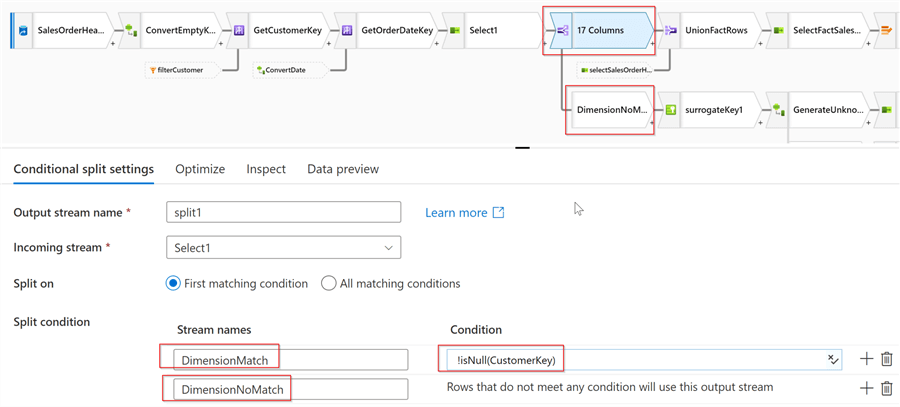
Figure 7
This split will direct the rows with non-empty CustomerKey values (i.e. rows with matches in the DimCustomer table) into the DimensionMatch branch, and the remaining rows into the DimensionNoMatch branch.
Accordingly, the DimensionNoMatch branch will contain the logic to generate new DimCustomerrows. Here I’m going to use the same surrogate keys and SCD fields generation technics that were described in my earlier posts (see Implement Surrogate Keys Using Lakehouse and Azure Synapse Analytics and Implementing Slowly Changing Dimensions on Lakehouse with Synapse Mapping Data Flow for more details).
Let’s add a Surrogate key transformation to this branch, to generate sequential row numbers. Here’s is the screenshot:

Figure 8
Next, add a Derived column transformation named GenerateUnknownCusomer with the following expressions:
| Column | Expression |
|---|---|
| CustomerKey | toInteger(CachedMaxCustomerKey#outputs()[1].MaxCustomerKey)+SurrogateKey |
| CustomerID | CustomerID |
| FirstName | "Missing attribute" |
| LastName | "Missing attribute" |
| EmailAddress | "Missing attribute" |
| EffectiveFromDate | currentDate('yyyy-MM-dd') |
| EffectiveToDate | toDate('9099-01-01','yyyy-MM-dd') |
| IsActive | 1 |
| RowSignature | crc32(256,CustomerID,"Missing attribute","Missing attribute","Missing attribute") |
Note that I’ve summed sequential row numbers with the previously cached highest existing CustomerKey value, to calculate a surrogate key. Here’s the screenshot:
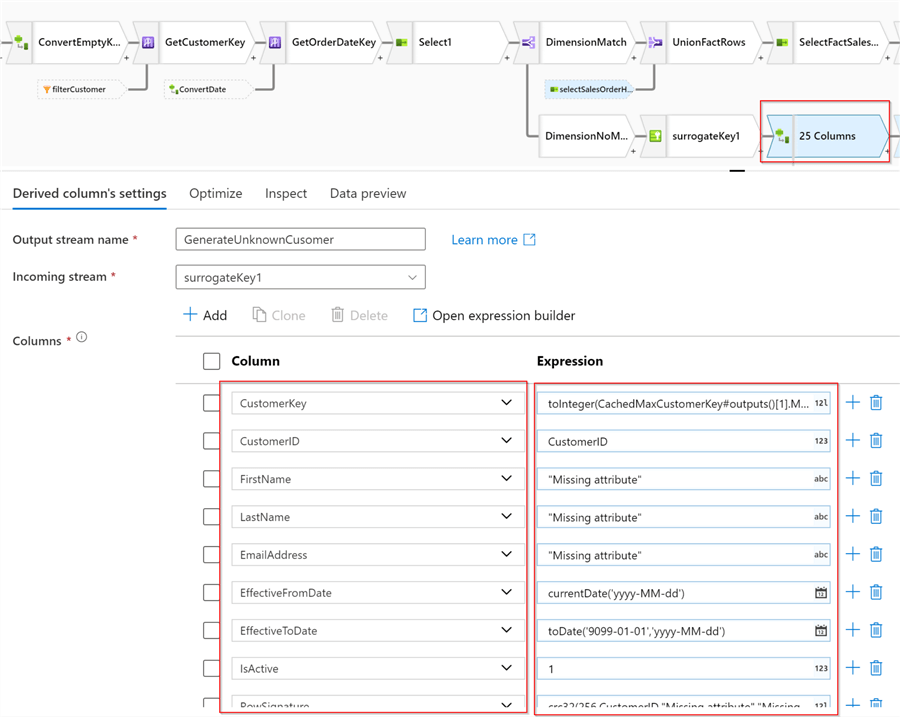
Figure 9
Let’s add a Select transformation named selectSalesOrderHeader, and limit the output to the fields specific to the FactSalesOrderHeader table, as follows:
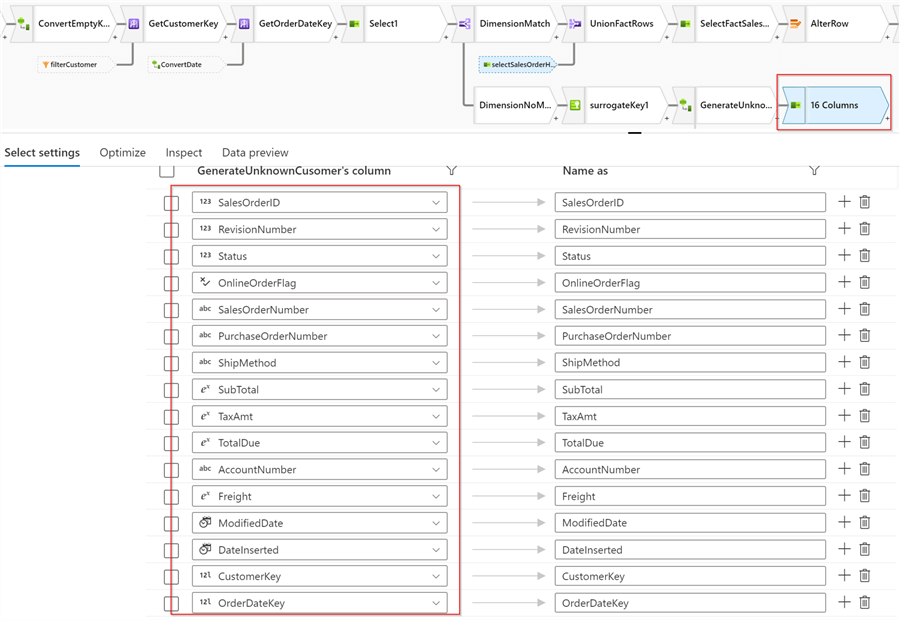
Figure 10
Let’s do a quick validation to ensure we have the correct surrogate keys:

Figure 11
All what we need to do from a fact table perspective is to add these rows to the DimensionMatch branch. So, let’s add Union transformation, and select selectSalesOrderHeaderas a secondary stream, as follows:
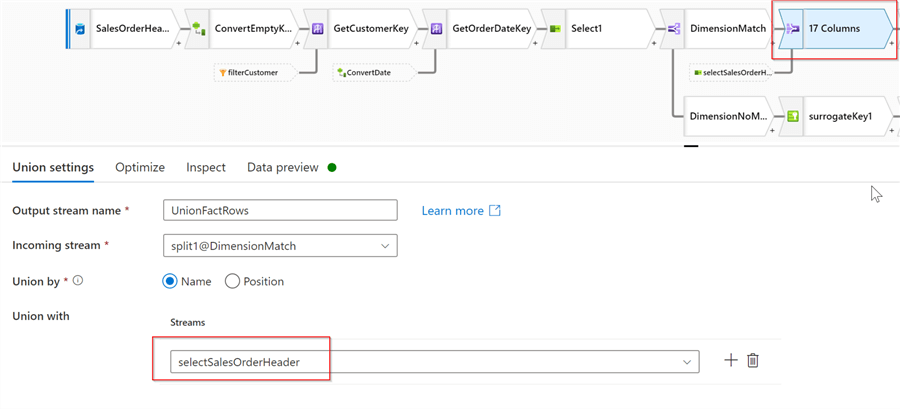
Figure 12
Let’s add another Select transformation to eliminate the CustomerID field, that’s not required in the target fact table:

Figure 13
Now it’s time to complete the logic to write into the DimCustomer table. Let’s add a Branch transformation after GenerateUnknownCusomer, as follows:

Figure 14
Add a Select transformation, and keep only fields specific to the DimCustomer table, as follows:

Figure 15
Because we’re going to insert/update against the target table, we’ll also need Alter row transformation, as follows:

Figure 16
And we’ll conclude this sub-branch with the sink transformation pointing to the DimCustomer Delta table, as follows:

Figure 17
Let’s validate the output of this stream:
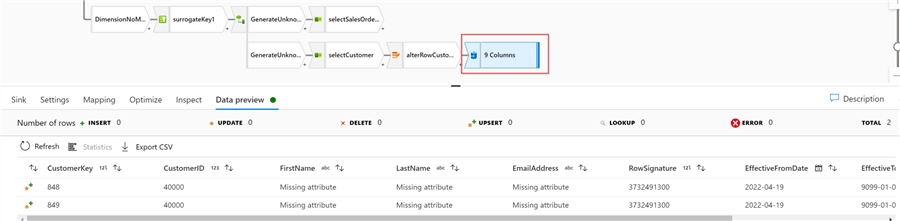
Figure 18
Next Steps
- Read: Common Data Warehouse Development Challenges
- Read: Conditional split transformation in mapping data flow
- Read: Union transformation in mapping data flow
- Read: Mapping data flows in Azure Data Factory

Fikrat Azizov (MCSE Data Platform and MCSE Azure Solutions Architect) has been working with SQL Server since 2002. Fikrat’s main passions are SQL Server performance optimization, cloud data technologies and machine learning. Fikrat is currently working as a Solutions Architect at Slalom Canada.
- MSSQLTips Awards: Author of the Year Contender – 2019-2022 | Rising Star (50+ tips ) – 2021