Problem
This tip is part of the series of posts, dedicated to the building of end-to-end Lakehouse solutions leveraging Azure Synapse Analytics. In the previous post (see Implementing Facts on Lakehouse using Synapse Mapping Data Flow-part1, Implementing Facts on Lakehouse using Synapse Mapping Data Flow-part2), we’ve explored the implementation of incremental data upload for the fact tables. In this tip, we’ll discuss another common fact processing task: fact-to-dimension mapping.
Solution
On a typical transactional database, the fact-to-dimension relationship is based on the natural keys. However, for analytical data warehouses, it’s recommended to base this relationship on surrogate keys. Surrogate key usage on dimensions allows for preserving historical changes to them. This means the relationship between facts and dimensions needs to be based on surrogate keys.
Data model
Let me illustrate this with an example taken from the Adventure Works database that we have been using throughout this series. This database is transactional, and as you can see from the following diagram, the relationship between SalesOrderHeader and Customer tables is based on the CustomerID key, which is a natural key:

Figure 1
This relationship needs to be transitioned into the following surrogate key-based relationship when moving to the data warehouse:

Figure 2
Notice that CustomerKey is the surrogate key for the Customer table.
The ETL pipeline design
The data flow we’re going to build needs to have a logic to replace natural keys with surrogate keys. In addition, it needs to handle empty values for the natural key column, by assigning them a surrogate key for an unknown dimension member.
Here are a few more details regarding the flow we’re going to cover here:
- It will run between Silver and Gold layers and populate the FactSalesOrderHeader table.
- The SalesOrderHeader table has multiple natural keys, but we’re going to cover only the links to DimCustomer and DimDate tables.
- It will use the DimCustomer Gold table with the surrogate key and Slowly Changing Dimension (SCD) logic in it. This dimension also should have an unknown member, and the common approach is to add a dimension with a surrogate key value of -1 and ‘Unknown’ values for other attributes. So, please follow my earlier posts Implement Surrogate Keys Using Lakehouse and Azure Synapse Analytics and Implementing Slowly Changing Dimensions on Lakehouse with Synapse Mapping Data Flow to build a data flow for the DimCustomer table and run it, to populate the DimCustomer table.
- It will use the DimDate Gold table with the surrogate key, so build data flow to populate the DimDate table (see Implement Time Dimensions on Lakehouse using Azure Synapse Analytics Mapping Data Flow for more details), before proceeding to the next steps. Also, create a Spark SQL notebook and run the following code to insert an unknown dimension member:
INSERT INTO DimDate (DateID,Date,Year,Quarter,Month,Day) VALUES (19000101,'1900-01-01',1900,1,1,1)
- Finally, you’ll also need to build the relevant pipelines to fetch SalesOrderHeader data from Azure SQL DB up to the Silver layer (see my previous posts in this series).
Let’s create a new data flow and name it DataflowSilverGold_SalesOrderHeader. Next, add a source transformation of Delta format and point it to the delta/silver/SalesOrderHeader folder, as follows:
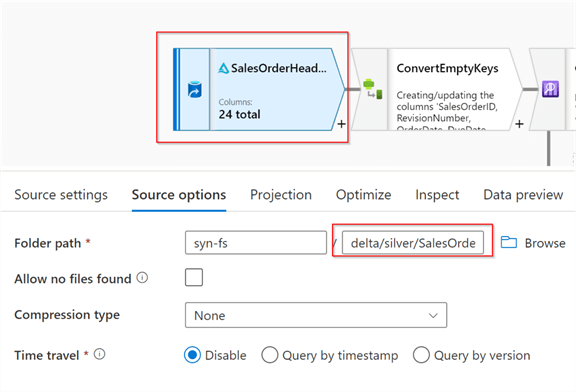
Figure 3
We’ll need to schematize this data source, so navigate to the Projection tab and click the Import schema button to fetch the table schema, as follows:
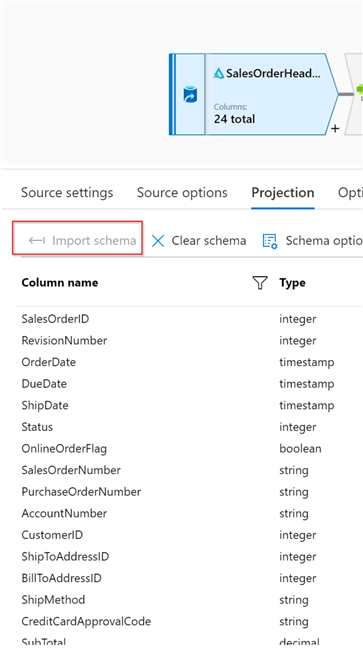
Figure 4
Next, add a Derived column transformation with the following expressions:
| Column | Expression |
|---|---|
| CustomerID | iifNull(CustomerID, -1,CustomerID) |
| OrderDate | iifNull(OrderDate, toDate('1900-01-01','yyyy-MM-dd'), OrderDate) |
These calculated columns convert empty natural keys to their corresponding unknown-member surrogate keys. Here’s the required screenshot:

Figure 5
Next, add a source transformation to read the DimCustomer Delta table and name it DimCustomerGold, as follows:

Figure 6
Switch to the Projection tab and import the schema for this data source.
Now, because the DimCustomer table is a type 2 SCD dimension, we need to read only the active version of each dimension. So, let’s add a Filter transformation with the following condition:
IsActive==1
Here’s the related screenshot:
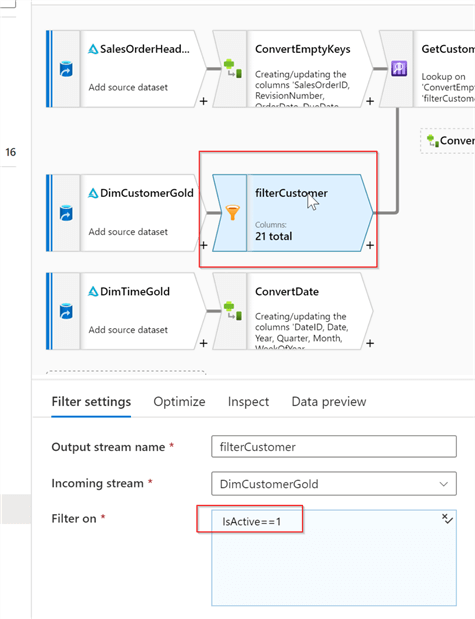
Figure 7
Now we can join these two streams using a Lookup transformation, as follows:
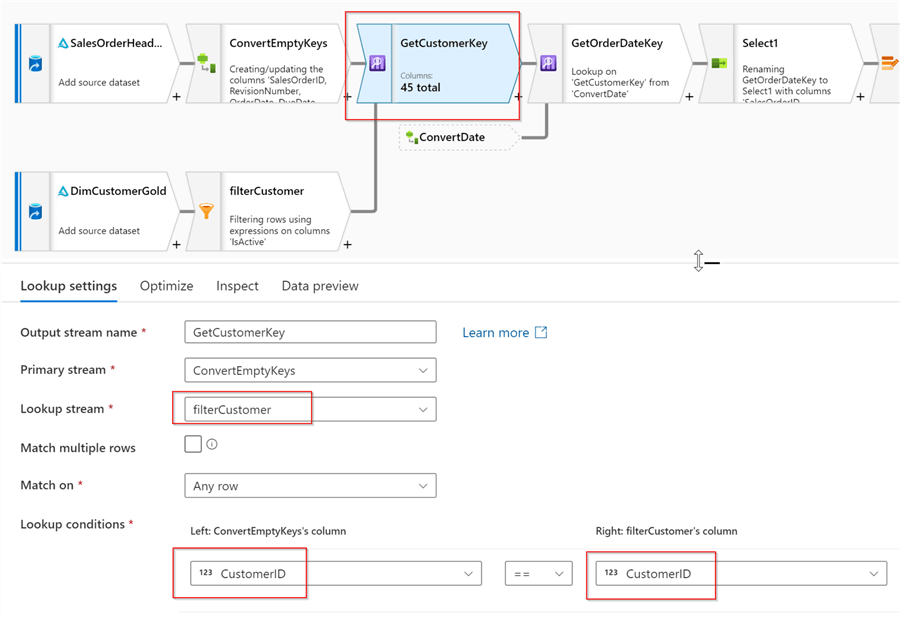
Figure 8
Notice that I’ve selected a natural key for the lookup join.
Next, let’s add a source for the DimDate table, and name it DimTimeGold, as follows:

Figure 9
Switch to the Projection tab and import the schema for this data source as well.
The Date field in the DimDate table comes with the date data type, but because my calculated column from ConvertEmptyKeys transformation is of timestamp type, I’ve added an extra type conversion component. Add Derived columntransformationafter the DimTimeGold, name it ConvertDate and include the following expression:
| Column | Expression |
|---|---|
| Date | toTimestamp(toString(Date, 'yyyy-MM-dd'),'yyyy-MM-dd') |
Here’s the screenshot:
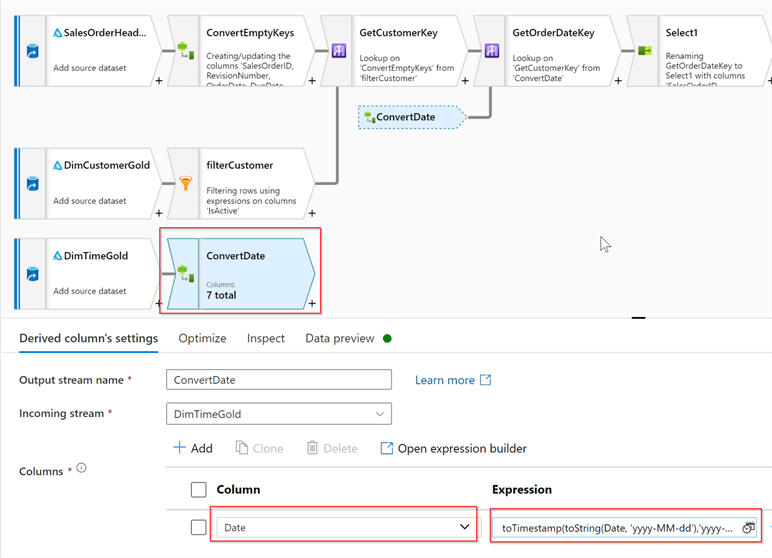
Figure 10
Now we can link the fact and time dimension, using the previously used method-so, add a lookup transformation at the end of the main data stream with the following settings:

Figure 11
Now it’s time to refine our column list- let’s add Select transformation, keep all the fields from the SalesOrderHeadertable, except natural keys CustomerID and OrderDate. Also include surrogate keys from the relevant dimensions, as follows:
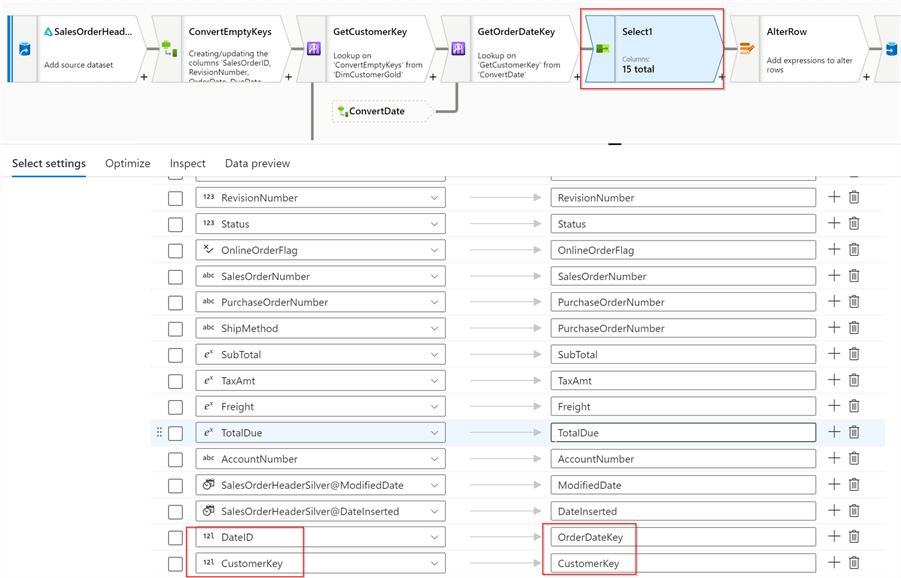
Figure 12
Now that we have core components in place, let’s turn on Debug mode and validate the results:
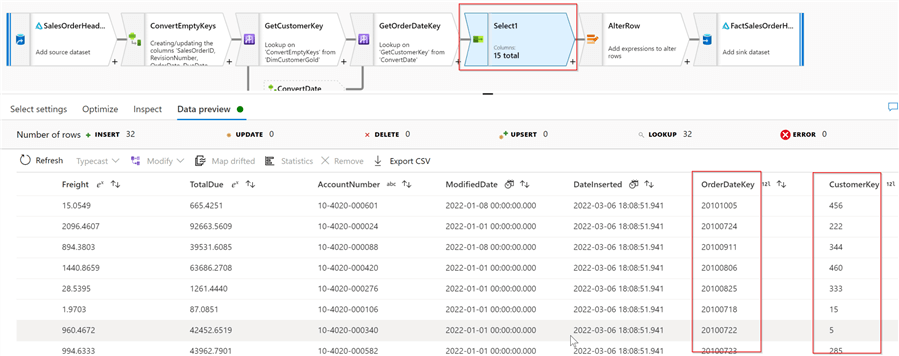
Figure 13
Finally, let’s add Alter row transformation, as our data flow is expected to have an upsert logic. Here’s a screenshot with the relevant settings:
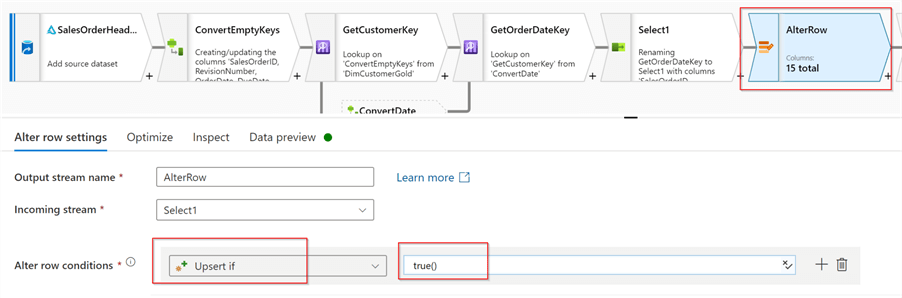
Figure 14
As always, we’ll conclude the data flow by adding the Delta Sink transformation, pointing to the delta/gold/FactSalesOrderHeader folder. Here are the required settings:

Figure 15
This concludes the data flow’s design. Here’s the end-to-end data flow design:
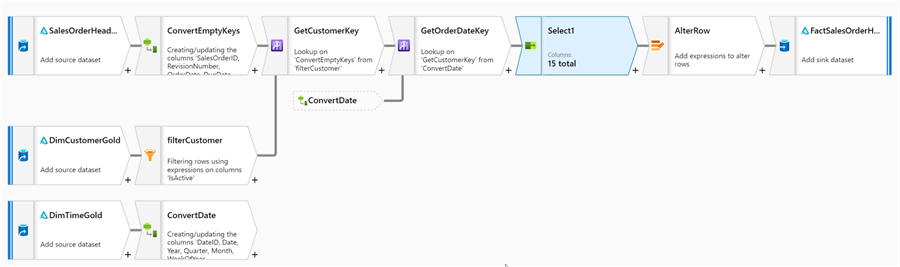
Figure 16
Next Steps
- Read: Common Data Warehouse Development Challenges
- Read: Dimension Surrogate Keys
- Read: Mapping data flows in Azure Data Factory

Fikrat Azizov (MCSE Data Platform and MCSE Azure Solutions Architect) has been working with SQL Server since 2002. Fikrat’s main passions are SQL Server performance optimization, cloud data technologies and machine learning. Fikrat is currently working as a Solutions Architect at Slalom Canada.
- MSSQLTips Awards: Author of the Year Contender – 2019-2022 | Rising Star (50+ tips ) – 2021
I am worrying about the upsert in the sink.
Following you flow, this will update an existing fact with the actual surrogate key from customer dimension (eg if quantity has changed) as your lookup is filtered (reading only actual rows).
Imho, your lookup needs to get the SK from customer table as it was when the order was inserted (that’s why I am using a Lifecycle_Start and Lifecycle_End in a dimension, and my lookup fetches lines with order_date between <LS_TS> and <LE_TS>).