Problem
This tutorial is part of a series dedicated to the building of a Lakehouse solution, based on Azure Synapse Analytics. In the previous posts (see Implement data deduplication in Lakehouse using Synapse Analytics Mapping Data Flow and Enrich your data in Lakehouse using Synapse Mapping Data Flow), we’ve discussed technics to address some common processing needs in the Lakehouse. Handling missing values is another common task, which we’re going to discuss in this tip.
Solution
Missing Value Handling Technics
Data values could be missing for a variety of reasons, including device or application issues and human mistakes. Depending on the purpose of your data warehouse, allowing missing values might lead to some issues. If your data warehouse is built to serve enterprise reporting, missing values will cause gaps and data quality issues. On the other hand, if your data warehouse is designed to serve the data science needs, handling missing values might be a mandatory requirement, as many machine-learning models do not work well with such data.
Here is the list of a few common missing value handling technics:
- Missing dimension attributes in the dimensional model – For example, you may receive dimension data that contain business keys, but not all the attributes. The valid attributes in many cases arrive later, so this case requires special handling. This is called a late-arriving dimension problem, and I’ll cover it in one of the upcoming tips dedicated to dimensional modelling.
- Missing measure attributes in the time-series data – This is a frequent problem with IoT data, caused by device connectivity issues. One of the common processing technics to handle this is an interpolation. There’re many ways to interpolate missing data, and one of them involves interpolation based on the average of the adjacent values.
- Missing measure attributes in the fact data – Many machine learning models require missing values to be replaced and the simplest approach is to replace missing values with some fixed string, like ‘N/A’.
I’ll cover interpolation and fixed value replacement technics here.
The Data Flow Design
I’ll use the data flow we built as part of the data enrichment exercise (see Enrich your data in Lakehouse using Synapse Mapping Data Flow for more details), and add a few transformations to handle missing data. Here’s how the target data flow will look like:

Figure 1
Here is the description of the added transformations:
- GetAdjasentValues – This is a Window transformation to calculate adjacent values. The idea is to use valid values from adjacent rows within the row groups to interpolate missing values.
- FillMissingValues – This is a Derived column transformation to fill missing values.
Data Preparation
As you may remember from previous discussions, the pipeline that fetches data from the landing zone into Bronze layer tables had a change history maintenance logic. In other words, it adds a new data snapshot on each execution. As a result, our Bronze tables contain various versions of the same row from multiple executions. To prepare the data, let’s nullify some values for a few rows in the source AdventureWorks/Customer table, using the following script:
update [SalesLT].[Customer] SET [CompanyName] =Null, Phone=Null where CustomerID <5
Here’s how this table looks after the change:

Figure 2
We’ll fill missing Phone column values with a fixed ‘N/A’ string and interpolate the CompanyName field from the previous versions of the same rows.
Let’s open Azure Synapse Studio and execute pipelines CopyPipeline_Landing_Json and CopyRawToDelta to fetch updated data into the Bronze tables.
Once pipelines are executed, we can use Synapse Serverless scripts to validate data in Bronze tables. Let’s create a SQL script, as follows:
Figure 3
Replace the DatalakeAct with your data lake account name in the script below and run it:
SELECT
TOP 100 CompanyName,Phone,DateInserted
FROM
OPENROWSET(
BULK 'https://DatalakeAct.blob.core.windows.net/syn-fs/delta/bronze/Customer/',
FORMAT = 'DELTA'
) AS [result]
WHERE CustomerID=1 Order by DateInserted Desc
As you can see from the below screenshot, we have the row versions from two ingestions, with the latest ingestion having missing values:
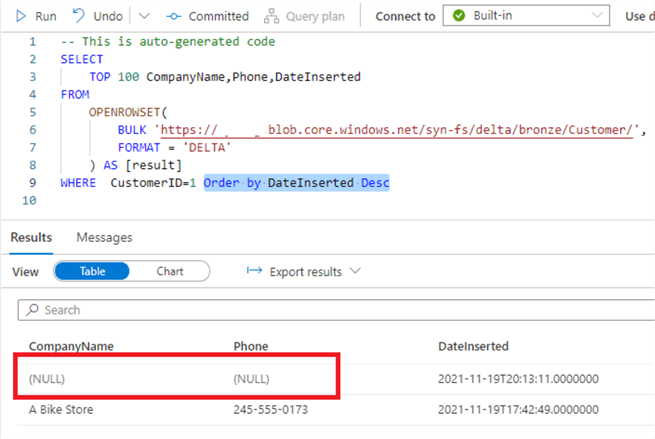
Figure 4
The Data Flow Implementation
Let’s open the DataflowBonzeSilver_Customer data flow we created in the previous tip and turn on a Debug mode.
Add A Window transformation after AddMetadataColums transformation and call it GetAdjasentValues.
This transformation will group the rows based on the primary key and for each row, within the group, it’ll fetch a column value from the previous row. In this demo we’re using a simple value substitution formula, however the same technic and can be used to come up with more sophisticated interpolation, like average/max/min calculation.
The Window transformation requires multiple settings and one of them is the Over setting which defines the primary identifier for the data source. Enter CustomerID in the left textbox, as follows:
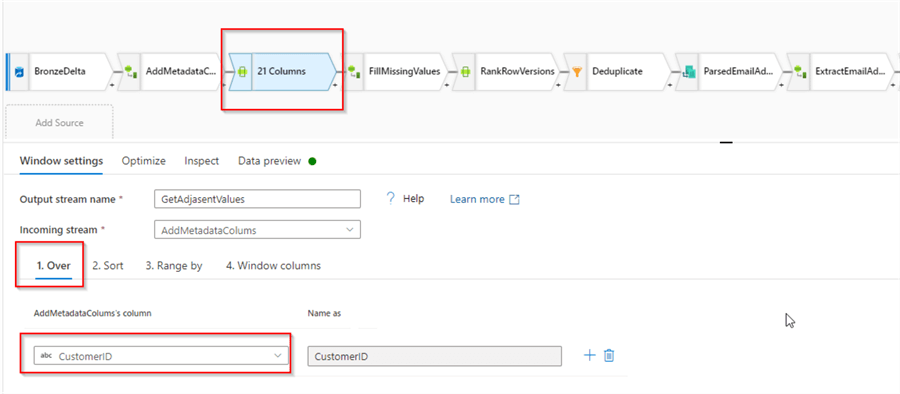
Figure 5
Navigate to the Sort tab and select DateInserted column- this will define the column by which rows within the row group need to be ordered:
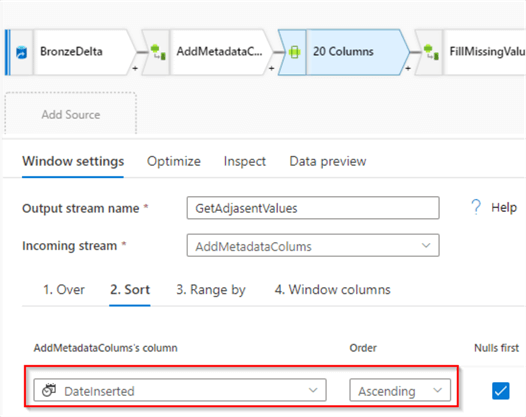
Figure 6
Finally, navigate to the Window columns tab and add the following calculated column:
- Column: CompanyName_Prev , Expression: lag(CompanyName)
The lag function here brings the column value from the previous row within the row group. If the row happens to be the first row, this function will return null. Here’s the screenshot:

Figure 7
Let’s validate the output from the source transformation, to confirm the formula works as expected:
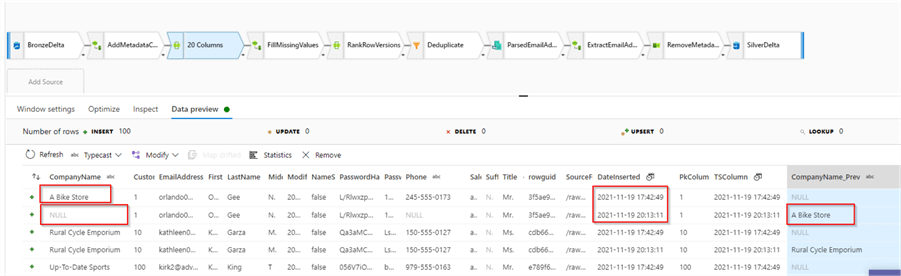
Figure 8
Next add a Derived column transformation with the following calculated columns:
- Column: CompanyName, Expression:
iif(isNull(CompanyName),CompanyName_Prev,CompanyName) - Column: Phone, Expression:
iif(isNull(Phone),"N/A",Phone)
These expressions will check the corresponding columns for missing values and replace them with either previous values or fixed strings. Here’s the screenshot:
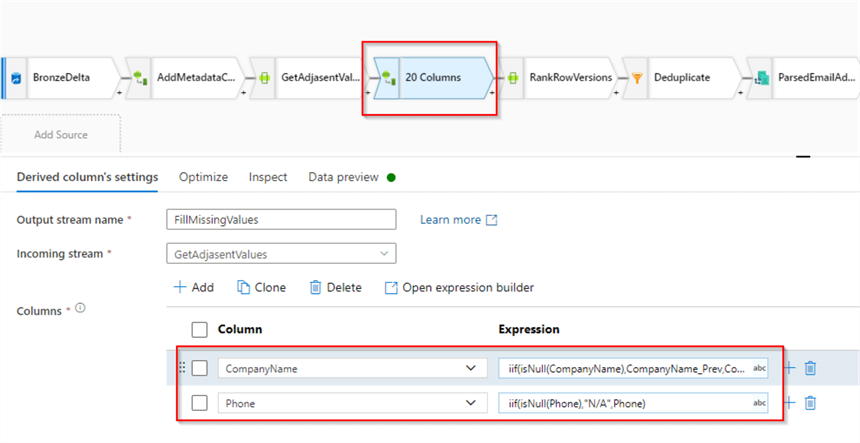
Figure 9
Let’s validate the results:

Figure 10
With these changes, our data flow now includes the most common ETL processing tasks, including missing value treatment, data deduplication and data enrichment. We’ll discuss dimensional modelling-related tasks in the few next posts.
Next Steps
- Read: Common Data Warehouse Development Challenges
- Read: Implement data deduplication in Lakehouse using Synapse Analytics Mapping Data Flow
- Read: Enrich your data in Lakehouse using Synapse Mapping Data Flow
- Read: Mapping data flows in Azure Data Factory

Fikrat Azizov (MCSE Data Platform and MCSE Azure Solutions Architect) has been working with SQL Server since 2002. Fikrat’s main passions are SQL Server performance optimization, cloud data technologies and machine learning. Fikrat is currently working as a Solutions Architect at Slalom Canada.
- MSSQLTips Awards: Author of the Year Contender – 2019-2022 | Rising Star (50+ tips ) – 2021