Problem
This article is part of the series of tutorial posts, dedicated to the building of a Lakehouse solution, based on Azure Synapse Analytics. In the previous post, Implement data deduplication in Lakehouse using Synapse Analytics Mapping Data Flow, we discussed techniques to deduplicate the data. In this tutorial, we’re going to explore another common Lakehouse transformation – data enrichment.
Solution
Data enrichment may be required for a variety of reasons, like:
- Extracting useful features from the source data. For example, the source data may include a column with JSON or comma-delimited strings and extracting some parts of it may be useful.
- Fetching data from external sources. For example, the source data may include an identity column and we might be interested in bringing its description from another data source.
The data enrichment, like deduplication, can be part of the transformations between the Bronze and the Silver layers.
The Data Flow Design
I’m going to leverage the deduplication data flow we’ve built in the previous post, and add extra transformations to it to demonstrate data enrichment technics.
Let’s open Azure Synapse Studio, clone the DataflowBonzeSilver data flow and name it DataflowBonzeSilver_Customer. Unlike DataflowBonzeSilver flow, this data flow is going to be table-specific, it’ll include only Customer table transformations.
This flow has multiple transformations designed for deduplication purposes. Here’s how it looks so far:

Figure 1
We’ll add data enrichment transformations at the end of it, just before the RemoveMetadataColumns transformation. Here’s how our target data flow will look:

Figure 2
We’ll also need to customize some of the existing transformations, to make this flow specific to the Customer table.
Here is a brief description of these transformations:
- ParsedEmailAddress. This transformation will parse the EmailAddress column from the source and generate a new column with the complex data type.
- ExtractEmailAddressPart. This transformation will read the column generated in the previous step and split it into two parts – user name and domain parts.
Configure Debugging Settings
Let’s turn on a debug mode and add debug parameters that will allow us to build the pipeline interactively.
Please enter following values as debug parameters:
- SourceTableName: “Customer”
- TargetTableName: “Customer”
- PrimaryKey: “CustomerID”
- TimestampColumn: “DateInserted”
Here’s the screenshot:
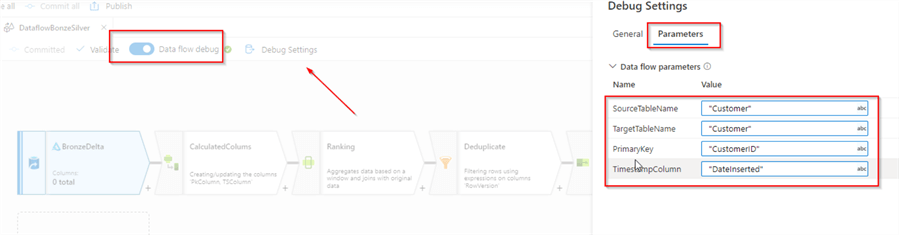
Figure 3
Source Transformation
Let’s select BronzeDelta transformation and navigate to the Source options tab. Use the Browse button to navigate to the folder that hosts Bronze Delta Lake files for the Customer table, as follows:
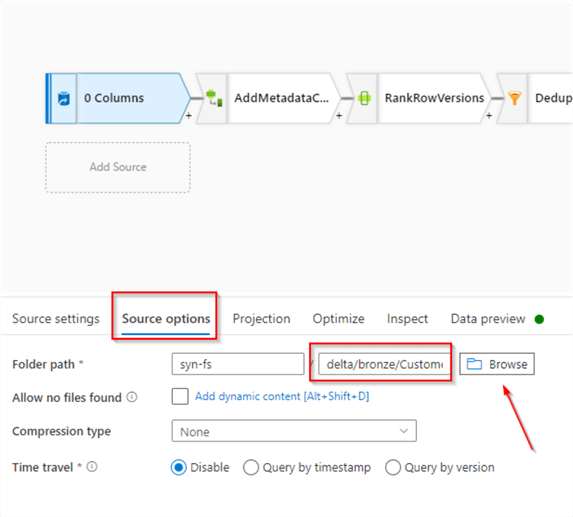
Figure 4
We’ll also need to fetch the schema for this table, so let’s navigate to the Projection tab and click the Import schema button, as follows:
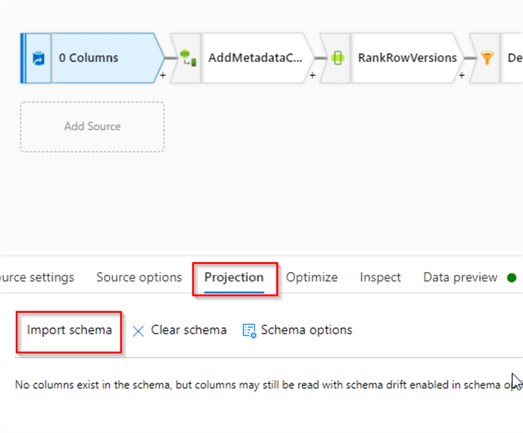
Figure 5
Here’s the screenshot of the Projection tab with the imported schema:

Figure 6
ParsedEmailAddress Step
Before adding a new transformation let’s select the Deduplicate step and examine the data from its output:

Figure 7
Our goal is to split the EmailAddress column into two parts – username and domain parts.
Let’s add a Parse transformation after the Deduplication step and select the DelimitedText option. Expand Delimited text settings section, select Edit checkbox and enter @ symbol as a delimiter:

Figure 8
Enter the following settings:
- ParsedEmailAddress in the Column text box, to define a new column’s name.
- EmailAddress in the Expression text box, to indicate a source column to be parsed.
- (UserName as string, Domain as string) in the Output column type text box, to define a schema of the new column.
Here’s the screenshot:

Figure 9
Let’s validate the results:

Figure 10
Notice we created a ParsedEmailAddress column with the complex data type. Next, we’ll split this column into its parts.
ExtractEmailAddressParts Step
Next, let’s add Derived column transformation after the ParsedEmailAddress step and add the following calculated columns:
- UserName: ParsedEmailAddress.UserName
- Domain: ParsedEmailAddress.Domain
Here’s the screenshot:

Figure 11
Let’s validate the results:

Figure 12
RemoveMetadataColumn Step
As you may remember from the previous post, this step was designed to eliminate all the columns that are not required in the target table. We’ll need to customize it, by adding the column ParsedEmailAddress to the exclusion list. Select this transformation, open the expression builder for the left-hand side textbox and modify the existing expression as follows:
name!="PkColumn"&&name!="TSColumn"&&name!="RowVersion"&&name!="ParsedEmailAddress"
Here’s the screenshot:

Figure 13
Here’s the screenshot with the validation results:

Figure 14
Building Parent Pipeline
Because the data flow we built here was for a specific table, our parent pipeline can be simple. Let’s create a data integration pipeline, add data flow activity to it and select the DataflowBonzeSilver_Customer data flow, as follows:

Figure 15
Navigate, to the Parameters tab and enter Customer table-related parameters, as follows:

Figure 16
This concludes the design of the parent pipeline. Let’s run it in debug mode and ensure that it succeeds:

Figure 17
Next Steps
- Read: Mapping data flows in Azure Data Factory
- Read: Azure Synapse Analytics Overview
- Read: Building Scalable Lakehouse Solutions using Azure Synapse Analytics
- Read: Common Data Warehouse Development Challenges

Fikrat Azizov (MCSE Data Platform and MCSE Azure Solutions Architect) has been working with SQL Server since 2002. Fikrat’s main passions are SQL Server performance optimization, cloud data technologies and machine learning. Fikrat is currently working as a Solutions Architect at Slalom Canada.
- MSSQLTips Awards: Author of the Year Contender – 2019-2022 | Rising Star (50+ tips ) – 2021