Problem
How do you enforce data integrity rules on Delta Lake tables?
Solution
The Delta Lake technology that serves as the basis for the Lakehouse concept creates an abstraction layer on top of the file system and allows most of the features you would expect in traditional databases. However, Delta Lake tables do not have important database-specific features, like primary keys, foreign keys, and value constraints, that can help ensure data quality.
As part of the series dedicated to building a Lakehouse solution based on Azure Synapse Analytics, this tip will discuss how to enforce data integrity rules on Delta Lake tables using Synapse Mapping Data Flow.
Synapse Mapping Data Flow’s Data Integrity Transformations
Synapse Mapping Data Flow provides a few transformations that can enforce data integrity rules (see Implementing Deduplication Logic in the Lakehouse using Synapse Analytics Mapping Data Flow). It also offers an Assert transformation that combines multiple validation features with the following rules:
- Expect true: This rule validates boolean expressions based on input columns that should validate True or False.
- Expect unique: This rule validates the uniqueness of the input expression or column.
- Expect exists: This rule validates the existence of the matching values from secondary input.
The Assert transformation tags the failed output rows as erroneous, which can be checked by subsequent transformations. For this tip, I will use the Assert transformation to enforce the following data integrity rule types on the destination table:
- Uniqueness constraint: This constraint is often required for identity columns.
- Foreign key constraint: This constraint ensures that values from one table always match those in another.
- Value range constraint: This constraint ensures that values in specific columns fall under a certain value range.
Data Flow Design
The data flow described here reads the data from Azure SQL Database, validates the input, and, depending on the validation results, writes the output either to the destination or log table.
Here’s the overall design:

Data Flow Implementation
Let’s create a data flow and add a source transformation that points to the Product table within the AdventureWorks Azure SQL Database:

Add the Assert transformation and name it ValidateProduct. Note: This transformation has a Fail data flow setting, which would fail the data flow as a whole if checked:

However, the scenario for this tip assumes partial ingestion, even if some rows fail validation.
Our first rule will ensure the uniqueness of the ProductModelID column. Let’s use the Add button at the bottom of the screen to add the rule, select Expect unique as a type, and enter assertUnique in the Assert Id and ProductModelID in the Expression boxes:

Now, turn on the debug mode and validate the results:
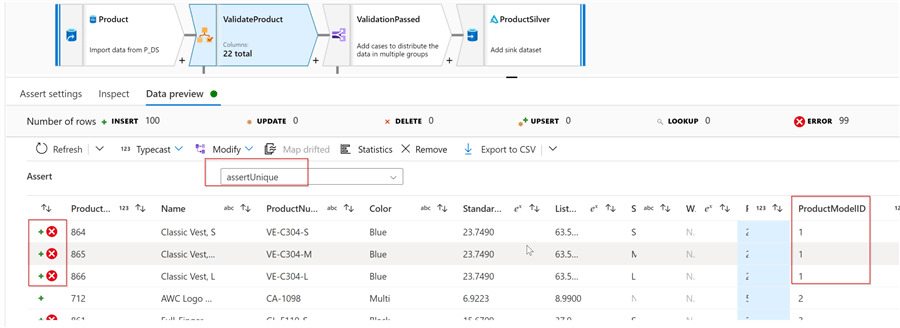
The Assert dropdown box at the top of the screen allows browsing each rule’s validation results separately. So let’s select the assertUnique rule. Notice that the first three rows with duplicate ProductModelID are marked as erroneous, which means the rule works as expected.
The Product table has the ProductCategoryID column that serves as a foreign key to the ProductCategory table. My second validation rule will check the foreign key matches between these tables. To simulate the mismatch, let’s remove the relationship constraints between these tables in the source AdventureWorks DB and run the following command:
Update [SalesLT].[Product] set ProductCategoryID=50 where ProductID<720
Next, let’s add another source transformation pointing to the ProductCategory table:

Now, let’s return to the settings tab of the ValidateProduct transformation and select ProductCategory as an additional stream:

Add another rule of type Expect exists, name it as assertForeignKey, and select Product@ProductCategoryID and ProductCategory@ProductCategoryID columns as matching columns:

Let’s do another quick validation to ensure this rule works as expected:

My third rule will ensure that the ListPrice column is not empty and is between 100 and 1000. So, let’s add the rule type of Expect true, name it assertValueRange and enter the following expression:
!!isNull(ListPrice) && between(ListPrice,100,1000)

Here are the validation results:
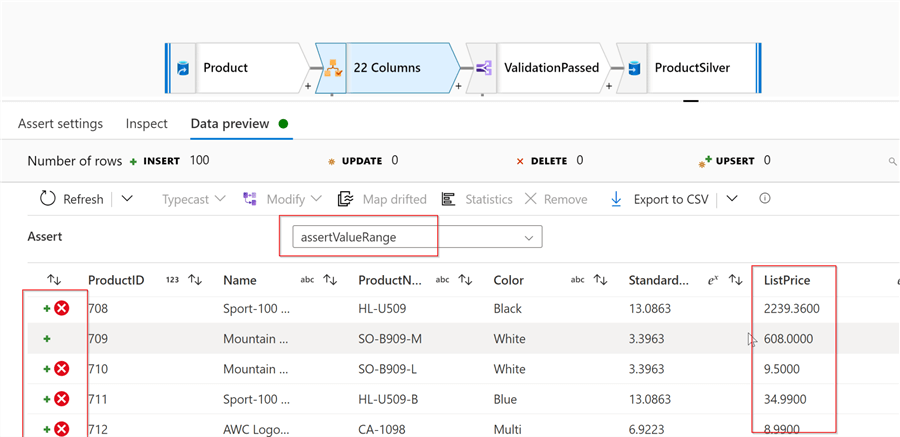
Our validation transformation tags the rows without performing any actions on them. Let’s take care of the actions now. Add a conditional transformation that will split the rows into two streams- rows that passed the validation and the rows that failed:

Name the successful validation stream as ValidationPassed and enter an expression !isError(). This expression identifies the input rows that have been tagged as erroneous. Also, name the other stream as ValidationFailed.
Let’s validate results by navigating to the Data preview tab and selecting the ValidationPassed condition from the top dropdown box:
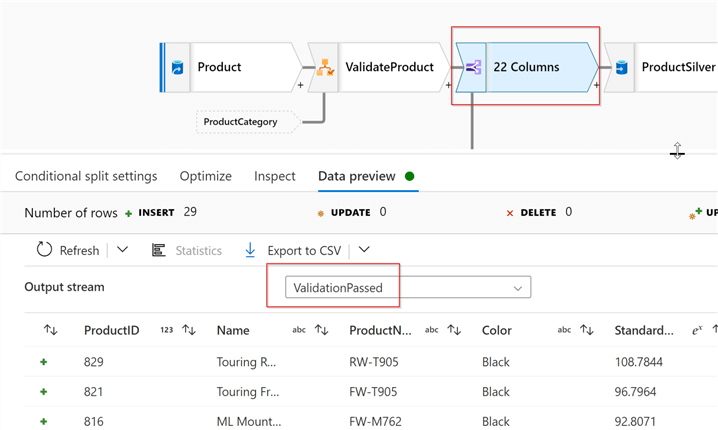
And complete the successful validation stream by adding a Delta Lake-type sink that points to the Product table’s location:

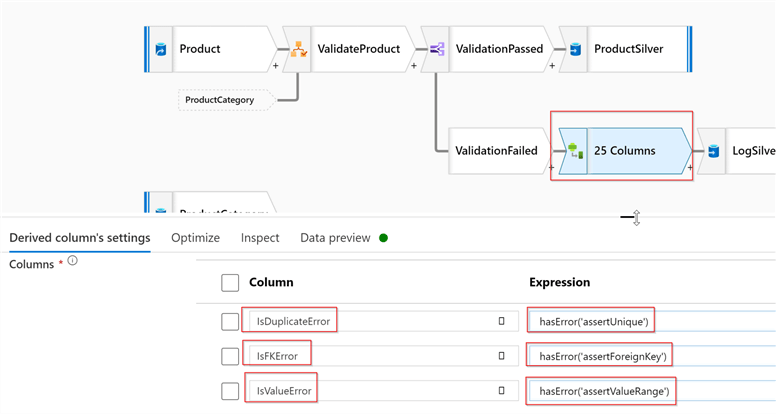
Now, let’s complete the failed validation stream. The rows that failed the Assert validation can be tested using the hasError function, which expects the validation rule name as a parameter. So, let’s add the Derived column transformation with the following expressions:
| Column name | Expression |
|---|---|
| IsDuplicateError | hasError('assertUnique') |
| IsFKError | hasError('assertForeignKey') |
| IsValueError | hasError('assertValueRange') |
Here’s the screenshot:
Now we can write the results into another Delta Lake sink that points to the IngestionErrors table folder:

Here are the validation results from this sink:

Next Steps
- Check out the following tips for more information:

Fikrat Azizov (MCSE Data Platform and MCSE Azure Solutions Architect) has been working with SQL Server since 2002. Fikrat’s main passions are SQL Server performance optimization, cloud data technologies and machine learning. Fikrat is currently working as a Solutions Architect at Slalom Canada.
- MSSQLTips Awards: Author of the Year Contender – 2019-2022 | Rising Star (50+ tips ) – 2021