By: Aaron Bertrand | Updated: 2022-11-16 | Comments (2) | Related: 1 | 2 | 3 | More > Database Administration
Problem
In my previous tip, I explained how we are inclined to use archive tables and how they become increasingly problematic over time. This tip will focus on ways to mitigate the issues.
Solution
As soon as you realize your growth rates are higher than expected, you need to plan to buy or allocate more disk space. There is no way around this—more data means more disk. You can delay the inevitable for a little bit with better compression, but this is not a long-term fix, and it can impact query performance in different ways (trading CPU for I/O).
Once more disk is in place, you can plan your growth better.
While planning, you can help alleviate slower-performing searches immediately by considering some short-term mitigations. One way is to change the behavior slightly, so that searches default to recent data. If most users are looking at recently added data, then as long as a supporting index helps to define "recent," you can impose a predicate on user queries (say, using a view) so that they only perform a partial range scan. Even if there isn't a supporting index, you can simulate your own using a technique I describe in "Improve Performance for Large Log Table Queries using a Goal Posts Table": Users can intentionally choose to bypass this predicate and search the whole table, but the default behavior would return newer information. Admittedly, this is easiest to accomplish when users or applications use stored procedures.
Part of your planning should include the discovery of formal retention policies. Keeping data "until it doesn't fit on the disk"—a policy I've seen in place more than once—is quite a precarious goal to try to meet. Different parts of your business may need to keep data longer than others; think about legal and compliance-related ramifications in addition to the daily needs of end users. It may be the case that you need to keep data cold and offline for years longer than it needs to remain hot and active for current users. Even in this case, though, keep in mind that you may need to bring it online temporarily in order to fulfill erasure requests (e.g., GDPR). Getting all departments to agree on a data retention policy might not be a cakewalk, but it's a crucial step that shouldn't be avoided or delayed.
Once you know how long you need to retain data, you can start planning. I'll review two approaches: 1) partitioning (for Enterprise Edition customers) and 2) separate tables. To keep the numbers low and any diagrams simple, let's say you need to keep data online for a year and offline for three years.
Partitioning
Whenever I suggest partitioning an existing table, the reactions range from laughter to cowering in fear. This is not that scary! And you don't have to partition all the old data to start. You'll need to buy or allocate more disk, which you were going to do anyway; ideally, making the new disk(s) big enough to store at least an entire retention period, plus a buffer for any increase in volume. You create a new filegroup and a new partitioned table there, partitioned by month, then create a view that bridges that with the old, unpartitioned table. (Remember not to create too many partitions in advance because they aren't free.) Change your application or stored procedures to insert data into the new table and select data from the view.
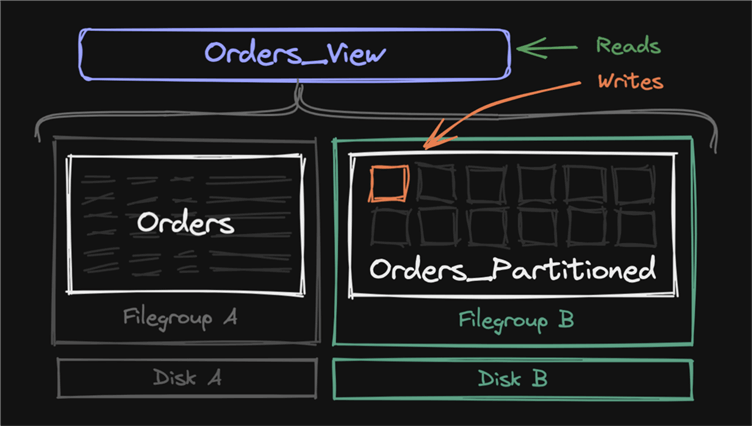
If you have to update old data, it can be done with an INSTEAD OF UPDATE trigger on the view. Technically, the inserts and deletes could go there too, but eventually, you can remove the layer of abstraction once all the data is partitioned.
The plan is to leave all the old data intact until an entire retention period is on the new disks, then take a final backup to store that data for offline retention. Then you can truncate (and ultimately drop) the old table, and now partitions are easy to switch out or truncate as the table becomes a traditional sliding window. You can switch out old partitions to an archive table (metadata-only if on the same filegroup) or drop the partitions as they fall out of retention (a backup for offline). Switching to an archive table would provide the added benefit of keeping deeper search data online but logically separate from the active table. Of course, this comes at the cost of additional disk space.
As you start creeping into the next year of retention, you can create a new filegroup on the old disk (which is now empty), set the next partition to use that filegroup, and then repeat the process when you return the following year of retention. (If the existing disk is not large enough to retain a full retention period, you may have to think about that now and make the second disk much larger or add multiple disks up front.)
Separate Tables
I realize we're not all on Enterprise Edition, so partitioning isn't necessarily an option. And not all workloads lend themselves to using filtered indexes, which I discussed in Partitioning on a Budget. Another way to simulate partitioning without going broke is to perform the same bridge mechanism as above, but instead of monthly partitions, create a table per month.
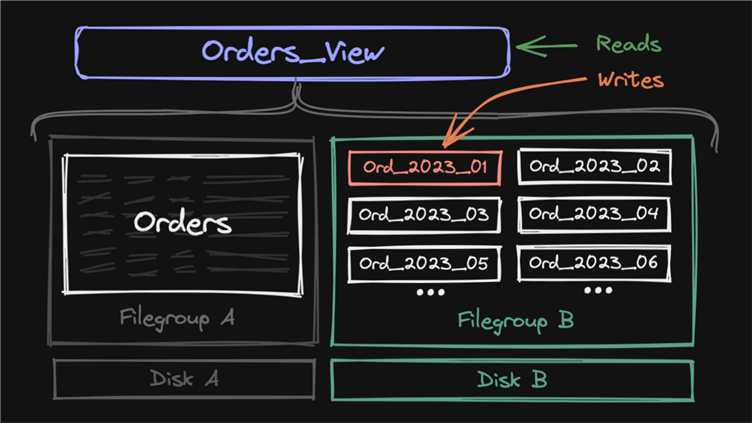
The view is slightly more complicated and needs to be updated as you slide your window. This may be a better case for just pushing writes to the view and a permanent INSTEAD OF trigger because the set of underlying tables will shift every month. So you will always have additional maintenance, which you can automate (to be addressed in a future tip).
Other Benefits
In both cases, abstracting the underlying tables behind views can provide more flexibility and the latitude to "move" data without actually moving it. And when the data ages out, we can switch out or truncate the older partitions or drop or truncate the older tables. At Stack Overflow, we use the latter approach, where we have a log table per month. There is a view that unions together all the tables within the current retention period; this allows queries to reference the views and not care about today's date or how long our retention period is right now. Pseudo-code for the view:
CREATE VIEW dbo.Log_Current
AS
SELECT <columns> FROM dbo.<Oldest_Table_In_Retention_Period>
UNION ALL
… all the tables in the middle …
UNION ALL
SELECT <columns> FROM dbo.<Table_For_Current_Month>;
There are also views that cover other timeframes, including the current month, the last two months, and the last two days. Updating these views is all handled through automation, which will be provided in a future tip.
Next Steps
- Start planning for an ever-growing transactional table.
- I used terrible naming conventions in my diagrams for simplicity and illustration; please don't follow my example that accurately.
- See these tips and other resources:






About the author
 Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.
Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2022-11-16
