Problem
I love incorporating window functions into T-SQL queries. However, they take practice to master. When I started working with them, summoning up more than one was hard. However, if you only know one inside and out, make it ROW_NUMBER(). Once you use it a few times, it will become second nature, like riding a bike or typing SELECT *. It’s critical to know how each argument comes into play. I can almost guarantee ROW_NUMBER() shows up during an interview focusing heavily on T-SQL.
Solution
This tip will look at the ROW_NUMBER() function in detail, including how to use each argument in a SELECT statement for a stored procedure or T-SQL script. When would you use ROW_NUMBER() versus other common ones such as RANK() and DENSE_RANK()? How did we get a row number before this function existed? Also, we’ll explore two use cases where it comes in extra handy. Finally, I’ll recap the key takeaways. By the end of this article, you’ll have a firm understanding of the ROW_NUMBER() function.
Defining ROW_NUMBER Function
Microsoft introduced window functions in SQL Server 2005. Often, they are broken out into three main categories (not all functions are listed for each category):
- Aggregate – SUM(), AVG() and COUNT()
- Ranking – ROW_NUMBER(), RANK() and DENSE_RANK()
- Analytical – LEAD(), LAG() and LAST_VALUE()
As noted, ROW_NUMBER() is a ranking function. Microsoft defines a ranking function as a function that returns a ranking value for each row in a partition. Depending on the function used, some rows might receive the same value as other rows.
Ranking functions are nondeterministic. The term “nondeterministic” means that the function returns different results each time it’s run. A nondeterministic function I run all the time is GETDATE(). Examples of deterministic functions include LTRIM(), RTRIM(), and LOWER().
Other RDBMS incorporate the ROW_NUMBER() function, including Oracle, DB2, and MySQL.
Review SQL ROW_NUMBER Function Syntax
What does the syntax for ROW_NUMBER() entail? There are three main elements.
OVER Clause
The OVER() clause must be included for ROW_NUMBER() to work. Think of it as the starting point for defining the partitions in your window. The following two clauses are arguments of OVER():
- PARTITION BY – This clause allows you to divide your dataset into multiple partitions in your window. The PARTITION BY argument is optional. If you don’t include it, you’ll end up with one partition or group.
- ORDER BY – The ORDER BY clause allows you to determine the order of your unique rankings. For example, if you want to rank employees based on sales, you order by the sales amount.
SELECT ROW_NUMER() OVER(ORDER BY Column1 DESC)
SELECT ROW_NUMBER() OVER(PARTITION BY Column1 ORDER BY Column2 DESC)
Some find the PARTITION BY argument in the OVER() clause confusing. Think about a window in your house or apartment with multiple panes. Each pane in a window corresponds to a partition in the OVER() clause. When using ROW_NUMBER(), you likely don't know how many partitions exist upfront. Remember: Windowing doesn't refer to the Microsoft Windows OS.
Build Your Dataset
Let’s build a small dataset with two SQL Server tables, Employee and Sales, to understand better how this works.
USE [master];
GO
IF DATABASEPROPERTYEX('RowNumberDemo', 'Version') IS NOT NULL
BEGIN
ALTER DATABASE RowNumberDemo SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE RowNumberDemo;
END;
GO
CREATE DATABASE RowNumberDemo;
GO
ALTER DATABASE RowNumberDemo SET RECOVERY SIMPLE;
GO
USE RowNumberDemo;
GO
CREATE TABLE dbo.Employee
(
EmployeeId CHAR(12) NOT NULL,
FirstName NVARCHAR(100) NOT NULL,
LastName NVARCHAR(100) NOT NULL,
Department NVARCHAR(50) NOT NULL,
HireDate DATE NOT NULL
);
INSERT INTO dbo.Employee
(
EmployeeId,
FirstName,
LastName,
Department,
HireDate
)
VALUES
('E-0000000001', 'Clark', 'Kent', 'DC', '04-18-1938'),
('E-0000000002', 'Bruce', 'Wayne', 'DC', '03-30-1939'),
('E-0000000003', 'Selina', 'Kyle', 'DC', '04-25-1940'),
('E-0000000004', 'Bruce', 'Banner', 'Marvel', '05-01-1962'),
('E-0000000005', 'Peter', 'Parker', 'Marvel', '06-05-1962'),
('E-0000000006', 'Scott', 'Summers', 'Marvel', '09-01-1963'),
('E-0000000007', 'Natasha', 'Romanoff', 'Marvel', '04-01-1964'),
('E-0000000008', 'Diana', 'Prince', 'DC', '01-01-1942'),
('E-0000000009', 'Eric', 'Brooks', 'DC', '04-01-1973'),
('E-0000000010', 'Frank', 'Castle', 'Marvel', '02-01-1974'),
('E-0000000011', 'Scott', 'Summers', 'Marvel', '09-01-1964');
CREATE TABLE dbo.Sales
(
EmployeeId CHAR(12) NOT NULL,
Amount DECIMAL(10, 2) NULL,
SalesDate DATE NOT NULL
);
INSERT INTO dbo.Sales
(
EmployeeId,
Amount,
SalesDate
)
VALUES
('E-0000000001', 465, '01-01-2023'),
('E-0000000001', 655, '01-05-2023'),
('E-0000000003', 876, '01-21-2023'),
('E-0000000003', 234, '01-14-2023'),
('E-0000000003', 456, '01-03-2023'),
('E-0000000007', 543, '01-15-2023'),
('E-0000000007', 123, '01-12-2023'),
('E-0000000010', 1200, '01-06-2023'),
('E-0000000010', 1111, '01-12-2023');
GO
Let’s use the ROW_NUMBER() function to return a unique value for each row in the Employee table. ROW_NUMBER() only returns distinct values for each partition.
SELECT ROW_NUMBER() OVER (ORDER BY Hiredate ASC) AS RowNumber,
FirstName,
LastName,
Department,
Hiredate
FROM dbo.Employee;
Here are the query results:

Note: I skipped PARTITION BY in the code above. As mentioned, it's optional, but you're limited on what you can do without it.
Rank the Rows
A common requirement is ranking rows by a specific value. In the example below, we will rank the Employees by their department.
SELECT ROW_NUMBER() OVER (PARTITION BY Department ORDER BY HireDate ASC) AS RowNumber,
FirstName,
LastName,
Department,
HireDate
FROM dbo.Employee;
Here are the query results:
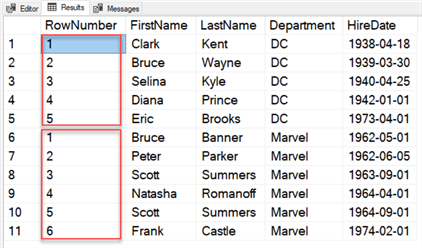
Notice how the ORDER BY clause is vital to establishing the rank. How many partitions make up our window? There are two in this example. You likely don’t know how many partitions ROW_NUMBER() creates on a larger dataset out of the gate. In our example, the row number starts over when SQL encounters a new department.
Now, if you wanted to have the rankings repeat or skip, that’s when the RANK() or DENSE_RANK() functions would come into play.
Once you understand PARTITION BY and ORDER BY, you’re well on your way to mastering ROW_NUMBER().
Ranking Before ROW_NUMBER
How did ranking work before ROW_NUMBER()? I’m glad you asked. I’ve done it in the past with a correlated subquery and counting the rows. Rick Dobson describes a correlated subquery as a special kind of temporary data store in which the result set for an inner query depends on the current row of its outer query. In case you’re curious, I included the code below.
SELECT
(
SELECT COUNT(*)FROM dbo.Employee e2 WHERE e1.EmployeeId <= e2.EmployeeId
) AS RowNumber,
e1.FirstName,
e1.LastName,
e1.Department,
e1.HireDate
FROM dbo.Employee e1
ORDER BY RowNumber;
Looking at the code above brings back bad memories. This approach also requires having a unique value; of course, you can concatenate columns together. In the same way, you hopefully don’t use a dial-up modem. Please don’t use a correlated subquery for ranking.
Find Duplicate Rows
ROW_NUMBER() is frequently used for finding duplicate rows. Duplicate rows have plagued developers since the inception of databases. I’m a massive fan of using Common Table Expressions or CTEs for this activity, but they’re not required.
There is a duplicate row in our original dataset. To fix it, you must consider what qualifies as a duplicate row. In our dataset, a duplicate is any employee listed more than once. We also need to know which of the two rows qualifies as the duplicate. Here we’ll say the non-duplicate has the oldest value for HireDate. The code below captures our requirements.
</pre> <p>Since you've determined that a duplicate row exists, you may want to delete it. The code below will get the job done.</p> <pre>
<code class="language-sql line-numbers">;WITH MainData
AS (SELECT ROW_NUMBER() OVER (PARTITION BY FirstName, LastName, Department ORDER BY HireDate ASC) AS RowNumber,
FirstName,
LastName,
Department,
HireDate
FROM dbo.Employee)
DELETE FROM MainData
WHERE RowNumber > 1;
Return the TOP N Rows
Something you may run into is needing to return the TOP n rows from a different result set. A common way developers approach this challenge is with an OUTER or CROSS APPLY. Arshad Ali writes that the APPLY operator allows you to join two table expressions; the right table expression is processed every time for each row from the left table expression.
I’ve found that using ROW_NUMBER() can provide slightly better performance over specific datasets.
Let’s imagine the business needs to see the top two sales for each employee. The code below works if you want to accomplish this via an OUTER APPLY. I’m using an OUTER APPLY to know who has not been making sales.
SELECT e.FirstName,
e.LastName,
e.Department,
e.HireDate,
s.Amount
FROM dbo.Employee e
OUTER APPLY
(
SELECT TOP (2)
s.Amount
FROM dbo.Sales s
WHERE s.EmployeeId = e. EmployeeId
ORDER BY s.Amount DESC
) s;
Here are the query results:

To get these same results using ROW_NUMBER(), the code below works.
We're working with a small dataset, so the queries execute quickly. Try both methods and see which provides the best performance on your data. Please let me know your experiences with both methods in the comments below.
Key Points
- Microsoft introduced ROW_NUMBER() in SQL 2005. It returns a unique BIGINT value over a specified partition.
- The PARTITION BY clause is optional, but you must include ORDER BY. Excluding PARTITION BY produces a single partition over the dataset.
- Think of the PARTITION BY in the same fashion as the panes in a window. If you PARTITION BY a column that contains four unique values, you'll end up with four partitions.
- Consider using ROW_NUMBER() the next time you need to find duplicate values in a table.
- ROW_NUMBER() is an excellent alternative to a CROSS or OUTER APPLY when returning the TOP N rows.
Next Steps
- For an informative overview of windowing functions, please check out the tutorial from Koen Verbeeck. One of my favorite sections is the gaps and island problems.
- In this article, Eric Blinn looks at some of the performance benefits of using windowing functions.
- Kathi Kellenberger hosted an engaging YouTube video for GroupBy. She talks about all the performance benefits of using windowing functions, especially improvements with SQL Server 2019. This video is well worth the time investment.

Jared Westover is a SQL Server specialist with two decades of industry experience covering T-SQL development, performance tuning, administration and Microsoft Fabric. He is currently a software architect at Crowe, an author at Pluralsight and primary contributor at sqlhabits.com. On MSSQLTips.com, Jared is a respected award-winning author for his clever T-SQL solutions and bringing to light new real-world solutions to age-old development problems.
- MSSQLTips Awards
- Achiever Award (75+ tips) – 2026
- Author of the Year – 2023
- Author Contender – 2024/2025


