Problem
The Microsoft Office suite used to be physically installed on every new business laptop. Within the last decade, Microsoft has migrated from an on-premises to an in-cloud offering via Office 365. This website shows Google having the top spot in cloud applications suite with 67 percent market share. Microsoft holds the second spot with almost 18 percent of the market share. The Google sheets application supports both XLSX (Microsoft) and ODS (Open Office) formats. Therefore, it will not be uncommon for a business user to ask a big data engineer to either read or write a Microsoft Excel file. How can we work with this non-native Apache Spark file format?
Solution
The Pandas library supports read and write methods that work with Microsoft Excel. This library is not Spark aware; therefore, it will execute at the driver node. Recently, Databricks released the Pandas API for Spark. This library should be used instead of Koalas. We can use either library to work with Microsoft Excel files.
Business Problem
Our company has begun to use Azure Databricks, and our manager wants us to learn how to manage Microsoft Excel files with Apache Spark. Here is a list of tasks that we need to investigate and solve:
| Task Id | Description |
|---|---|
| 1 | Sample Data Sets |
| 2 | Configure Spark Cluster |
| 3 | Read Excel Files |
| 4 | Analyze Excel Files |
| 5 | Write Excel Files |
| 6 | Modify Excel Files |
At the end of the research, we will understand how to manage Microsoft Excel files.
Sample Data Sets
Typically, big data engineers work with file types such as CSV and PARQUET that are natively supported by the SPARK engine. Therefore, I will use my background in SQL Server to choose the AdventureWorks files used to create a database. These files are pipe delimited in nature without any headers. You can find the files and installation script for SQL Server at this Git Hub location.
I also wanted a sizable Microsoft Excel worksheet. The sunshine list is a complete list of public sector workers who make more than $100K in Ontario, Canada. This is a single file, 15 MB in size, and can be downloaded from this website.
Now that we have our datasets, how do we configure our spark cluster to work with Microsoft Excel files?
Configure Spark Cluster
When working with a library, I usually look at the documentation to see if there are any prerequisites. The image below shows four different libraries that can be called by Pandas depending upon the file extension. Today, we will work with XLSX files; therefore, we must install the openpyxl library on the Azure Databricks cluster.

Make sure to open the running cluster and edit the cluster to install a new library. The image below shows a cluster named “interactive cluster,” which has three libraries installed. Two libraries are used to work with SQL Server, and one library is used for Event Hub. Click the “install new” button to add a new library.
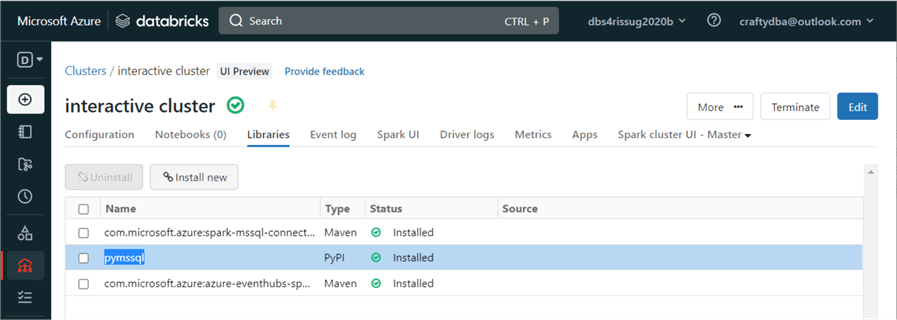
From the documentation, we know that the openpyxl library is available on PyPI. Add the package name and click Install.

After the installation, we can see the new library available on our cluster. Sometimes, the cluster needs to be restarted for the library to become available.

Now that the cluster is configured, we can read in our first Excel workbook and write it out as a file in Parquet format.
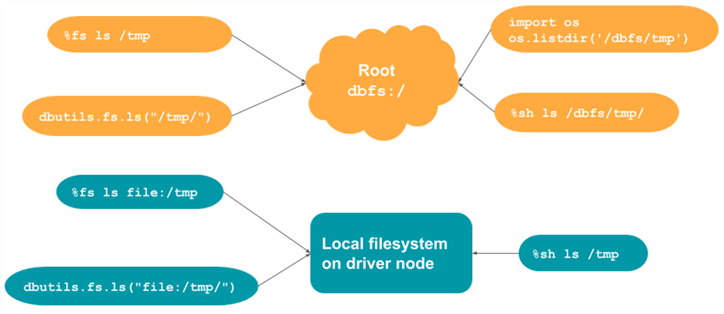
Exploring Our Data Lake
To continue, let’s assume data lake storage is in place and working. Please refer to the Microsoft documentation for details on this Databricks task. However, we want to ensure we can read from and write to storage.
The image from the Azure Portal below shows that our data lake has three quality zones: bronze, silver, and gold.

Under the sunshine folder, we have two sub-folders. Let’s use the following convention: raw – a folder that has files in a form that Spark can work with natively, and stage – a folder that has files in a form that Spark does not work with natively. We can see that the data is stored in a Microsoft Excel (XLSX) format and an Open Document Spreadsheet (ODS) format.

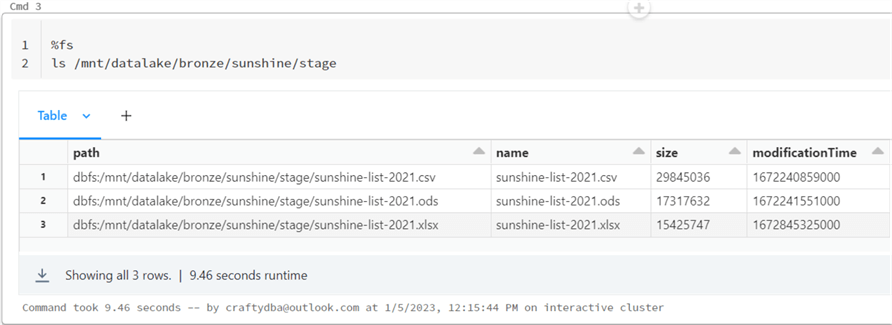
To validate that we have connectivity to the storage service, let’s use the file system magic command, which allows me to use Linux syntax to list all the sunshine list files in the stage sub-directory.
Here is a spoiler alert. All the coding for our research is complete. The image below shows six notebooks that contain Python code.

In the next section, we will cover how to read an Excel file.
Read Excel File (PySpark)
There are two libraries that support Pandas. We will review PySpark in this section. The code below reads in the Excel file into a PySpark Pandas dataframe. The sheet name can be a string – the name of the worksheet or an integer – the ordinal position of the worksheet. The header command allows us to tell the engine that the first row is a header. The schema is inferred from the worksheet.
# # R2 - Read in sunshine data file # # libraries import pyspark.pandas as pd # file path path = '/mnt/datalake/bronze/sunshine/stage/sunshine-list-2021.xlsx' # read the file pdf1 = pd.read_excel(io = path, sheet_name = 0, header = 0) # show top 10 rows pdf1.head(10)
The output below shows the dataset.

The type function can be used to validate the object type of our variable named pdf1. This means we need to use the to_spark function to cast this variable to a Spark dataframe before writing it to disk.

The code below depends on the toolbox notebook for supporting functions. The magic command can load these functions into the current Spark context.
%run "./nb-tool-box-code"
The code below writes the Pandas dataframe to a Parquet file. We will repartition the dataframe so that only one parquet partition is written to a temporary directory underneath the raw folder. The unwanted_file_cleanup function finds the single file (partition) by pattern in a temporary subdirectory and saves it as a final file in the raw directory. This function is very handy since Spark creates several other files that are not of interest to the end user.
#
# R3 - Write out sunshine data file
#
# output path
path = '/mnt/datalake/bronze/sunshine/raw/temp'
# save as one file
pdf1.to_spark().repartition(1).write.parquet(path)
# create single file
unwanted_file_cleanup("/mnt/datalake/bronze/sunshine/raw/temp", "/mnt/datalake/bronze/sunshine/raw/sunshine-list-v001.parquet", "parquet")
As a big data engineer, we know that reading files with a schema usually execute quicker than not using a schema. How can we get a schema from the Pandas dataframe we just read in?
# show the column names pdf1.columns
The columns method of the dataframe returns an index that contains all the column names.

We can cast the index to a list and use a lambda expression to create a final string. I assumed all columns were using a string data type.
# create a sample schema
cols = list(pdf1.columns)
lst = ['%s string' % (str(col).replace(" ", ""),) for col in cols]
schema1 = ', '.join(lst)
print(schema1)
The ability to create schema definitions quickly is important.

To recap, we showed how to read data using PySpark Pandas and write to a file in Parquet format. In the next section, we will cover the older library called pandas.
Read Excel File (Pandas)
There are two libraries that support Pandas. We will review the original library that was made for data science in this section. Can we speed up the reading of the Excel file? How do we use the openpyxl library to read in the Excel file?
# # R4 - Read in excel workbook and worksheet, save as pandas data frame # # libraries import pandas as pd from openpyxl import load_workbook # path to file path = '/dbfs/mnt/datalake/bronze/sunshine/stage/sunshine-list-2021.xlsx' # open work book wb = load_workbook(filename=path, read_only=True) # choose worksheet ws = wb['tbs-pssd-compendium-salary-disc'] # convert to data frame pdf1 = pd.DataFrame(ws.values) # close workbook wb.close()
The above code reads a given worksheet using the read-only option. This should increase the performance a little. The values of the worksheet are then casted to a Pandas dataframe. Just like files, close the workbook at the end of each operation.
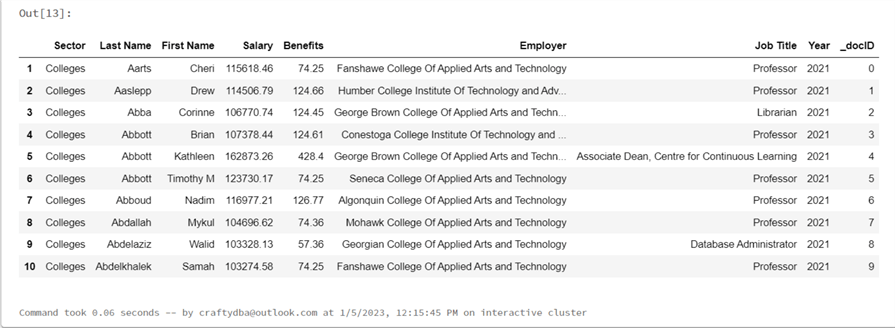
# # R5 - header is on the first row # pdf1.head(5)
The above code shows the first five rows of the dataframe. However, the first row in the image below has not been promoted to a header.

The code below creates a copy of the original dataframe, pdf1. In this copy – pdf2, we promote the first row to become a header using the dataframe methods.
# # R6 - make copy, fix dataframe # pdf2 = pdf1 pdf2.columns = pdf2.iloc[0] pdf2 = pdf2[1:] pdf2.head(10)
The image shows the dataframe with the correct header, using descriptions, not numbers.
The code below uses the schema we defined above when casting the Pandas dataframe to a Spark dataframe.
# # R7 - convert pandas to spark df # # define the schema schema = "Sector string, LastName string, FirstName string, Salary string, Benefits string, Employer string, JobTitle string, YearNo String, DocId String" # create the dataframe sdf1 = spark.createDataFrame(data = pdf2, schema = schema, verifySchema = False) # show the data display(sdf1)
We can see that Databricks tries to optimize the conversion using Arrow. It fails in the conversion but succeeds when not using Arrow.

This is a typical problem that you might encounter when casting. You can try playing around with the data types defined in the schema or cast everything to a string data type. Once it is in a Spark dataframe, we can eliminate any bad data and cast to the correct type.
The code below uses Spark dataframe methods to change salary and benefits to double precision data types.
#
# R8 - change column data types
#
from pyspark.sql.functions import *
sdf1 = sdf1.withColumn("Salary", col("Salary").cast('double'))
sdf1 = sdf1.withColumn("Benefits", col("Benefits").cast('double'))
display(sdf1)
The image below shows the first thousand rows of data in the dataframe.
The last task is to write the file to disk in a Parquet format.

The code below is similar to section R3. The only difference is the library used to read the Excel file. The openpyxl library is important since it opens up the advanced operations that can be done in Excel with the Python language.
#
# R9 - Write out sunshine data file
#
# output path
path = '/mnt/datalake/bronze/sunshine/raw/temp'
# save as one file
sdf1.repartition(1).write.parquet(path)
# create single file
unwanted_file_cleanup("/mnt/datalake/bronze/sunshine/raw/temp", "/mnt/datalake/bronze/sunshine/raw/sunshine-list-v002.parquet", "parquet")
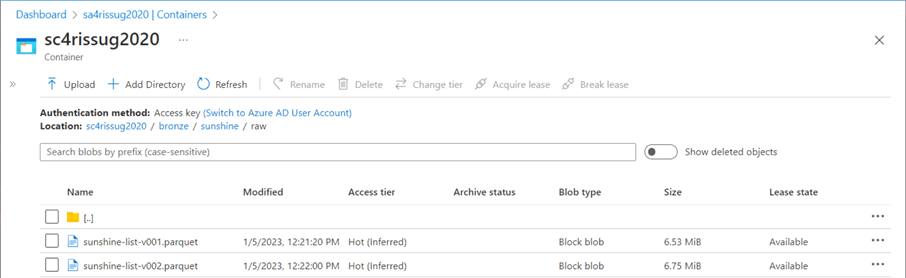
The image below shows the same data stored in two different files. Each file was created using a different method.
In the next section, we will talk about analyzing existing Excel workbooks.
Analyzing Excel Files
One problem that you might encounter when working with Excel files is schema drift. Excel files are usually created by humans. Each column’s name and position must be consistent for a program to read them into the delta lake. How can I look at a bunch of workbooks (files) and get details of each worksheet? I choose three sample data sets (files) from Kaggle. The combined file contains all three data sets. The image below shows the location of the files in terms of Databricks File System (DBFS).

One of the functions in the toolbox returns a list of file names given a directory path. Please see the code below.
#
# Define function to find matching files
#
# import libraries
import fnmatch
# define function
def get_file_list(path_txt, pattern_txt):
# list of file info objects
fs_lst = dbutils.fs.ls(path_txt)
# create list of file names
dir_lst = list()
for f in fs_lst:
dir_lst.append(f[1])
# filter file names by pattern
files_lst = fnmatch.filter(dir_lst, pattern_txt)
# return list
return(files_lst)
We will use the openpyxl library to create a function to open each Excel workbook and grab the row/column counts by worksheet name. The code below returns an array of dictionaries.
#
# A2 - get_xlsx_rowcnt() - given a work book and work sheet, count the rows
#
# libraries
import pandas as pd
from openpyxl import load_workbook
# define function
def get_xlsx_rowcnt(book):
# empty list
ret = []
# open work book
wb = load_workbook(filename=book, read_only=True)
# for each sheet
for sheet in wb.sheetnames:
# get current worksheet
ws = wb[sheet]
# get counts
rc = ws.max_row
cc = ws.max_column
# append dict to list
ret.append({'sheet': sheet, 'row_cnt': rc, 'col_cnt': cc})
# close workbook
wb.close()
# return a count
return(ret)
The code below returns all the Excel workbooks in the various sub-directory.
# # A3 - get a list of files for a given path and pattern # # path + pattern file_path = '/mnt/datalake/bronze/various/' file_pattern = '*.xlsx' # get + show list file_lst = get_file_list(file_path, file_pattern) print(file_lst)
The image below shows us the four Excel files in the various directory. This is just the first step in getting the properties of each worksheet.

The code below completes the task by calling the get_xlsx_rowcnt function on each file.
#
# A4 - get detailed info
#
file_path = '/mnt/datalake/bronze/various/'
for file in file_lst:
book = '/dbfs' + file_path + file
msg = "ws = {}".format(book)
print (msg)
info = get_xlsx_rowcnt(book)
msg = "info = {}".format(info)
print (msg)
print("")
The output shows the details of each Excel workbook.

Writing Excel Files (Part 1)
In this section, we will work with the delimited files that create the AdventureWorks database. This sample data can be found on this Git Hub repo. The image below shows that these files have been saved in the raw sub-directory.

There are many different encoding formats for flat files. Internally, the file uses a delimited format with the pipe character defined as the delimiter. Externally, the file is being saved using a UTF-16 LE BOM encoding. This is important information that we need to read in the data files correctly. See the image below, which depicts the data dimension file being loaded in Notepad++.

The Python code snippet below defines a function called get_utf16_csv_file. It takes a file path, schema, and parameters and returns a Spark dataframe. The schema is required since no header information is in the file. Passing a schema is a preferred way to read files since the engine does not need to infer data types. This will save you execution time in the long run.
#
# C1 - get_utf16_csv_file() - read utf-16 csv file with schema, return data frame
#
# define function
def get_utf16_csv_file(file_path, file_schmea):
# create data frame
df = (spark.read
.format("csv")
.option("header", "false")
.option("delimiter", "|")
.option("quote", "")
.option('multiline', 'true')
.option("encoding", "UTF-16LE")
.schema(file_schema)
.load(file_path)
)
return(df)
To call the function above, we need to define the file path and file schema. The code below loads the account dimension data file into a dataframe.
# # W1 - Read in [DimAccount] csv file # # path to file file_path = "dbfs:/mnt/datalake/bronze/adventureworks/raw/DimAccount.csv" # file layout file_schema = """ AccountKey INT, ParentAccountKey INT, AccountCodeAlternateKey INT, ParentAccountCodeAlternateKey INT, AccountDescription STRING, AccountType STRING, Operator STRING, CustomMembers STRING, ValueType STRING, CustomMemberOptions STRING """ # read csv into df df1 = get_utf16_csv_file(file_path, file_schema) # show df display(df1)
The image below shows the output from displaying the Spark dataframe containing the account data.

Now that we have a Spark dataframe, one would think converting the dataframe to Pandas would allow us to write the file to Excel. The code below, in theory, should work.
# # W3 - Write single-sheet workbook # # include library import pandas as pd #file_path = "/dbfs/mnt/datalake/bronze/adventureworks/stage/advwrks.xlsx" df1.toPandas().to_excel(file_path, sheet_name = 'dim_account', index=False)
However, we get the following error:

This error is unexpected. However, if you look at the documentation, it only supplies the file name, not the path. This error is because the Hadoop file system (HDFS), on which DBFS is based, does not support random I/O. See this stack overflow post for details. To get the above code to work, set the file path to “advwrks.xls.”

So, where did the file get saved after we executed the cell? Databricks has updated its documentation for the support of the local driver node. If we look in that directory, we will see our file.
I did try using dbuitls.fs.ls with this new mount point, but I found it was problematic. It might be my environment. However, the shell command seemed to work fine. The code snippet below uses a Linux command to search for a file.
%sh ls /databricks/driver/advwrks.xlsx
The last task is to copy the file from this location to our mounted storage.
%sh mv --force /databricks/driver/advwrks.xlsx /dbfs/mnt/datalake/bronze/adventureworks/stage/advwrks-w100.xlsx
If we download the Excel file from Data Lake Storage and open it in Excel, we can see the following information:

If we run this code for the next delimited file, it will create a brand-new workbook and worksheet.
The following section will investigate writing multiple worksheets to the same workbook.
Writing Excel Files (Part 2)
The goal of this section is to write all the files for the AdventureWorks datasets as worksheets in one workbook. Because we have many files to load into datasets, we will want to use a parameter driven design approach.
The code below uses a control list or an array to add dictionaries for each data file. We need to know the input data lake path, the input data lake file, the output worksheet name, and the input file schema. The code below is just for the accounts file. Look at the notebook named nb-write-excel-file-v2 for a complete list of dictionaries.
# empty array
ctrl_list = []
#
# M3.1 - account file
#
parms = {
"id": 1,
"datalake_path": "dbfs:/mnt/datalake/bronze/adventureworks/raw/",
"datalake_file": "DimAccount.csv",
"worksheet_name": "dim_account",
"file_schema": "AccountKey INT, ParentAccountKey INT, AccountCodeAlternateKey INT, ParentAccountCodeAlternateKey INT, AccountDescription STRING, AccountType STRING, Operator STRING, CustomMembers STRING, ValueType STRING, CustomMemberOptions STRING"
}
ctrl_list.append(parms)
If you are curious, a print of the control list is a lot of information.

The code below uses a similar technique. For each file, we will call our utility function called get_utf16_csv_file, which returns a dataframe. Each dataframe will be added to an array.
# # M4 - read in all files # df_list = [] for ctrl in ctrl_list: file_path = ctrl["datalake_path"] + ctrl["datalake_file"] file_schema = ctrl["file_schema"] df = get_utf16_csv_file(file_path, file_schema) df_list.append(df)
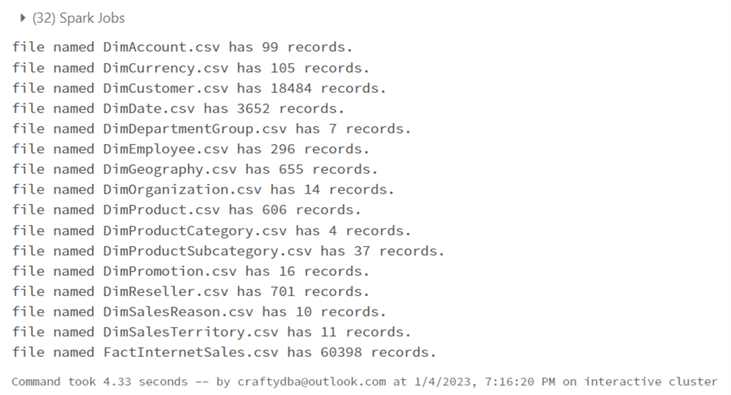
The best way to check data engineering is to get before and after counts. We can investigate the array of datasets to get record counts.
#
# M5 - get dataframe counts
#
values = range(16)
for i in values:
print("file named {} has {} records.".format( ctrl_list[i]["datalake_file"], df_list[i].count() ))
The below image shows the output from executing this snippet of code.
The code below uses the Excel Writer object class in Pandas to keep the connection to the workbook open and write multiple worksheets. The range function comes in handy if you want to create a simple for loop in Python. This code block is so small since it is all metadata driven.
#
# M6 - Write multi-sheet workbook
#
# include library
import pandas as pd
# file name (must be local file)
file_path = "advwrks.xlsx"
# use excel writer for multiple sheets
with pd.ExcelWriter(file_path, engine='openpyxl') as writer:
values = range(16)
for i in values:
df_list[i].toPandas().to_excel(writer, sheet_name = ctrl_list[i]["worksheet_name"], index=False)
Well, that is a lot of detail. But the results should be easily seen. We now have a workbook for AdventureWorks with a worksheet for each table.
Modify Excel Files
To modify an existing Excel file, we need to move the file to the driver sub-directory. I copied over the sun-shine-list.xlsx file as sanbox-001.xlsx. The code below should be familiar to you. The only change is that the final Spark Dataframe has been saved as a temporary view named tmp_sunshine_list. We will use this view to aggregate the list and save the updated file.
#
# C4.1 - Read in excel workbook and worksheet, save as pandas data frame
#
# libraries
import pandas as pd
from openpyxl import load_workbook
# path to file
path = '/databricks/driver/sandbox-001.xlsx'
# open work book
wb = load_workbook(filename=path, read_only=True)
# choose worksheet
ws = wb['tbs-pssd-compendium-salary-disc']
# convert to data frame
pdf1 = pd.DataFrame(ws.values)
# close workbook
wb.close()
#
# C4.2 - Promote first line to header
#
pdf2 = pdf1
pdf2.columns = pdf2.iloc[0]
pdf2 = pdf2[1:]
pdf2.head(5)
#
# C4.3 - convert pandas to spark df
#
# define the schema
schema = "Sector string, LastName string, FirstName string, Salary float, Benefits float, Employer string, JobTitle string, YearNo int, DocId int"
# create the dataframe
sdf1 = spark.createDataFrame(data = pdf2, schema = schema, verifySchema = False)
# make temp hive view
sdf1.createOrReplaceTempView("tmp_sunshine_list")
For a given sector, we want to get the count of employees plus statistics about the salary. The code below creates a new Spark dataframe.
#
# C4.4 - summarize using spark sql
#
stmt = """
select
sector,
count(*) as n,
round(min(salary), 2) as min_sal,
round(max(salary), 2) as max_sal,
round(avg(salary), 2) as avg_sal
from
tmp_sunshine_list
where
sector is not null
group by
sector
"""
sdf2 = spark.sql(stmt)
The image below shows the summarized information in the new dataframe.

The last step is to write out a new Excel file that has the original spreadsheet and this summary information. The create_sheet, dataframe_to_rows, append, and save methods are all from the openpyxl library.
#
# C4.4 - convert pandas to spark df
#
# used libraries
from openpyxl.utils.dataframe import dataframe_to_rows
from openpyxl import load_workbook
# path to file
path = '/databricks/driver/sandbox-001.xlsx'
# open work book
wb = load_workbook(filename=path)
# add new work sheet
wb.create_sheet('summary')
# select work sheet
ws = wb['summary']
# get pandas worksheet
df = sdf2.toPandas()
# append rows
for r in dataframe_to_rows(df, index=True, header=True):
ws.append(r)
# save update
wb.save("sandbox-002.xlsx")
# close workbook
wb.close()
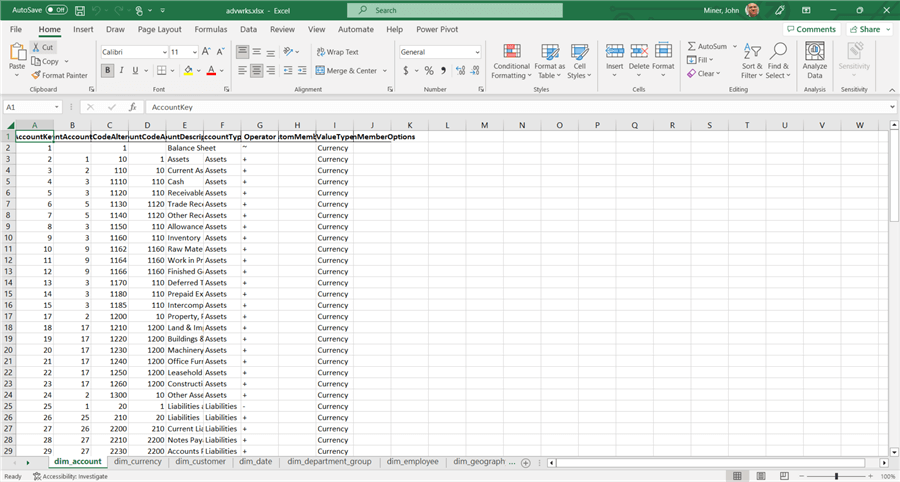
I chose to save the combined results to a new file name. Just remember to copy the final result file back to our mount point. In our case, the correct quality zone and folder are in the data lake. The image below shows the fruits of our labor. Column A is the by-product of the index being added by Pandas. We can remove that by code. I do not understand row 2. It seems to be a blank row between the header and the data.

Next Steps
Using Apache Spark to read and write data files can be done. Please note that one of four libraries will be used by Pandas, given the data file extension. When reading an Excel file into a dataframe, one must look for type conversion errors. Reading everything in as string data and fixing errors after loading is the best approach. Watch out for schema drift when loading a bunch of Excel files. Today, we created a function that can be used to scan files for worksheet names, row counts, and column counts. This code can be used as a first level test for schema drift. Because of the limitations of HDFS and random I/O, all writing of files must be done at the driver node. When writing multiple worksheets, use the Excel Writer object. Finally, we can do many operations on Excel files using the base libraries. The openpyxl library was used with our custom code to create a summary worksheet for the employee data.
Is Microsoft Excel an efficient file format to use with Apache Spark? The answer is no. For instance, all write operations involve file copies from mounts to driver nodes. The Excel file cannot be partitioned over multiple files. As a big data developer, will you be asked to work with an Excel file? The answer is yes. Given the number of Google and Microsoft Office users, you will likely be asked to use this file format.
Enclosed are the zip files that contain the following information:

John Miner is a Senior Data Architect at Insight Digital Innovation helping corporations solve their business needs with various data platform solutions.
He has over thirty years of data processing experience, and his architecture expertise encompasses all phases of the software project life cycle, including design, development, implementation, and maintenance of systems.
His credentials include undergraduate and graduate degrees in Computer Science from the University of Rhode Island. Also, he has earned certificates from Microsoft for Database Administration (MCDBA), System Administration (MCSA), Data Management & Analytics (MCSE), Data Science (MPP), Databricks Certified, and Fabric Certified.
John has been recognized with the Microsoft MVP award nine times for his outstanding contributions to the Data Platform community.
When he is not busy talking to local user groups or writing blog entries on new technology, he spends time with his wife and daughter enjoying outdoor activities. Some of John’s hobbies include wood working projects, crafting a good beer and playing a game of chess.
- MSSQLTips Awards: Author of the Year – 2019, 2022, 2023 | Champion (100+tips) – 2023