Problem
I want to read an Excel workbook stored in an Azure Blob Storage container. However, I cannot use Azure Data Factory (ADF) because I need to do some transformations on the data. Can I achieve my goal with Azure Functions instead?
Solution
There are a couple of different methods for reading Excel workbooks in the Azure cloud. The easiest options don’t require code: a Copy Data activity in ADF or an Azure Logic App. However, both copy the data to a destination.
What if we want to do some more complex transformations? Another option is dataflows in ADF (both mapping dataflows or Power Query), but these might be a bit too expensive to process small Excel files.
A solution that involves a bit more code is Azure Functions. Using C# libraries, we can read an Excel file from Azure Blob Storage into memory and then apply the transformations we want. This tip will cover a solution that reads an Excel file with multiple worksheets into a .NET DataSet.
Let’s not start from scratch. A previous tip, Retrieve File from Blob Storage with Azure, shows how to create an Azure Function that downloads a file from an Azure Blob Storage container and reads the contents in memory. It is strongly encouraged to read this tip first before proceeding with this tip.
How to Read an Excel File with an Azure Function
To recap, this is the code of the Azure Function (you can find a download link for the source code at the end of the tip):
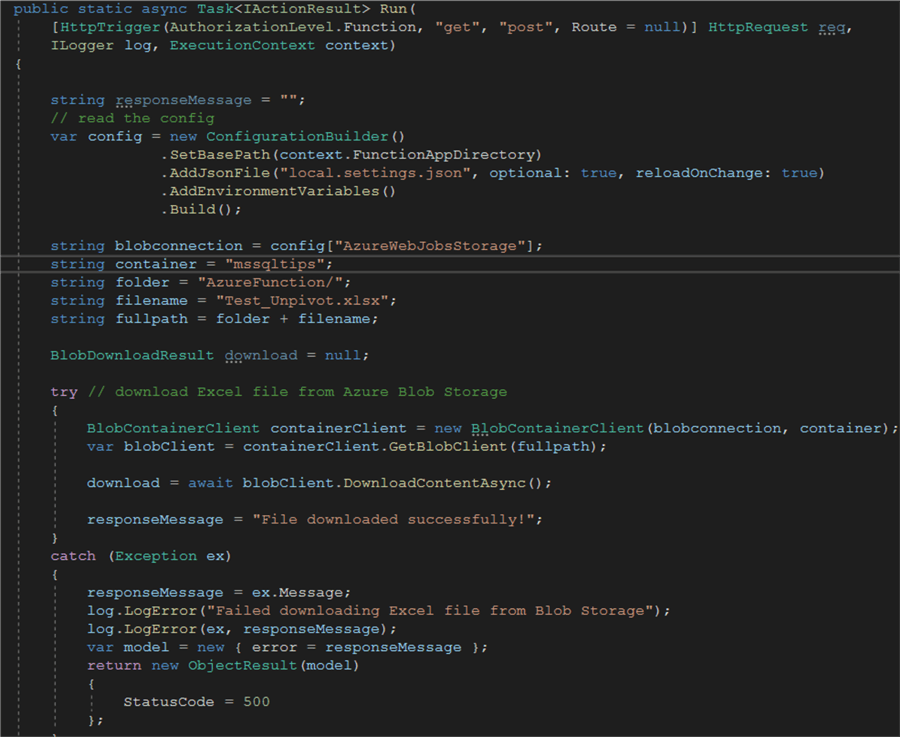
When this Azure Function is executed, it will read the Excel file from Azure Blob Storage. However, the result is still binary data, which is not particularly useful for us.

To read the contents of the Excel file, we need to install some extra packages. In the NuGet package manager, search for ExcelDataReader and install the latest version of this package and the package ExcelDataReader.DataSet.
We will read the contents of an Excel workbook, which contains two worksheets.

The second worksheet has similar data:
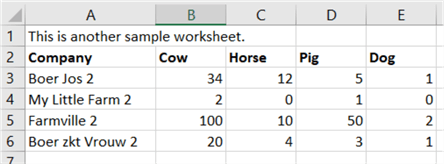
The end result is going to be stored in a .NET DataSet object. This object can store multiple DataTables, where each DataTable corresponds with a single Excel sheet.
Let’s add our first lines of code.
DataSet dataSet = new(); System.Text.Encoding.RegisterProvider(System.Text.CodePagesEncodingProvider.Instance); IExcelDataReader excelReader = null; excelReader = ExcelReaderFactory.CreateOpenXmlReader(download.Content.ToStream(), null);
The first line creates a new DataSet object to store the result. The second line is needed to ensure the code pages are registered (which might not always be the case. It’s possible the 1252 code pages are not registered by default for .NET Core, for example). In the next line, we create a new ExcelDataReader object, which reads the contents of the downloaded blob (which is converted into a stream). We use OpenXml, which is used for the .xlsx extension of Excel.
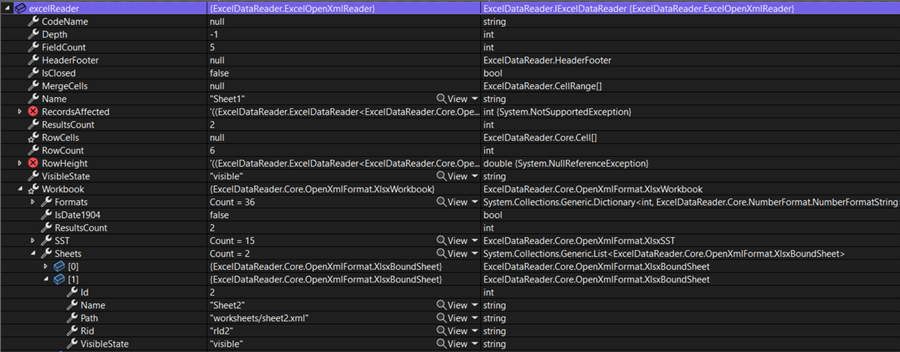
When we debug the Azure Function, we can see that both Excel sheets have been read successfully:
It’s possible to skip the first line and use the second line as a header for the columns. To do this, we need to create the following:
ExcelDataSetConfiguration dsconfig = new()
{
ConfigureDataTable = (tableReader) => new ExcelDataTableConfiguration()
{
UseHeaderRow = true, // use a header row
ReadHeaderRow = rowReader =>
{
rowReader.Read(); // skip the first row before reading the header
}
}
};
This code will tell the ExcelDataReader that we want to use a header row but skip the first row before we read it. You can find more info on the different options in the readme of the ExcelDataReader Github page.
In the final two lines of code, we save the ExcelReader as a DataSet and close the reader:
dataSet = excelReader.AsDataSet(dsconfig); excelReader.Close();
When debugging, we can inspect the contents of the DataSet and verify that the data has been read correctly (by skipping the first row and using the second row as a header):

Using the table dropdown in the top right, we can also view the second sheet:

Unpivoting the Data
An example of the transformations we can do once the data is loaded into memory, we’re going to unpivot the data. Right now, there’s a column for each type of animal on a farm. If another species is added, another column is added to the Excel worksheets. Not every ETL tool can deal with this type of change, called schema drift. By unpivoting the data, we end up with a key-value pair: one column that describes the type of animal and another column that holds the count. If a new species is added, this adds more rows to the data set, but the columns stay the same.
In our example, we will unpivot the data residing in multiple worksheets and store it in one single DataTable.
DataTable dtResult = new();
dtResult.Columns.Add("Company", typeof(string));
dtResult.Columns.Add("Animal", typeof(string));
dtResult.Columns.Add("Count", typeof(int));
The column “Company” is our pivot column. This means it stays as-is in the final result set, so we add it directly to the DataTable. We’re also adding this column to a list (using the HashSet type).
HashSet<string> pivotcols = new() { "Company" };
If more passthrough columns are added later, they can also be added to this HashSet. Furthermore, we add a column Animal and a column Count to the DataTable. These are our respective key and value columns.
Next, we’re iterating over all the tables in the DataSet (see the previous section). For each table, we iterate over all its rows. For each row, we iterate over its columns. If the value found in a cell is empty, it is ignored (and thus not added to our key-value table). If the column name is found in the HashSet, it is also ignored since it’s a passthrough column. In all other cases, a new row is created, the value for the company is added to this row, the current column name (the type of animal), and the value found in the current cell (the count of said animal). The new row is then added to the result table. This results in the following code:
//unpivot the data
//each worksheet is added to the final result table
foreach (DataTable dt in dataSet.Tables)
{
foreach (DataRow dr in dt.Rows)
{
foreach (DataColumn col in dt.Columns)
{
var value = dr[col.ColumnName]?.ToString();
if (!string.IsNullOrWhiteSpace(value) && !pivotcols.Contains(col.ColumnName))
{
DataRow newrow = dtResult.NewRow();
newrow["Company"] = dr["Company"];
newrow["Animal"] = col.ColumnName;
newrow["Count"] = value;
//log.LogInformation("Column Name = " + col.ColumnName + ", value = " + value);
dtResult.Rows.Add(newrow);
}
}
}
}
responseMessage = "Downloaded and unpivoted the Excel file!";
return new OkObjectResult(responseMessage);
When we run the Azure Function, we get the following data returned:
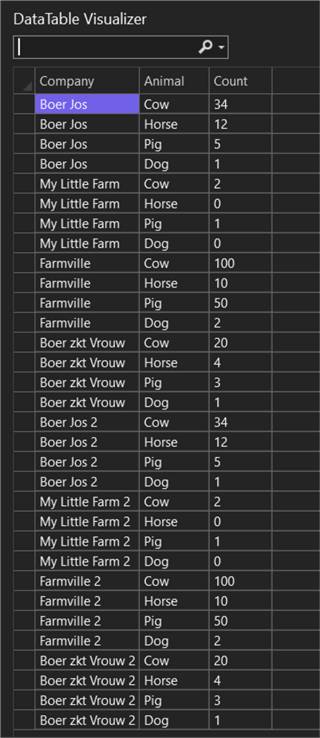
Next Steps
- You can download the following resources for this tip:
- As an exercise, you can try to write some additional lines of code that write the final DataTable to a SQL Server table.
- You can find more Azure tips in this overview.
- If you want to learn how to integrate an Azure Function into an Azure Data Factory pipeline, check out Integrate Azure Function into Azure Data Factory Pipeline.

Koen Verbeeck is a seasoned business intelligence consultant with over a decade of experience with the Microsoft Data Platform. He holds several certifications, including Azure Data Engineer. He’s a prolific writer, with over 375 articles on technologies such as Microsoft Fabric, SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at various events such as PASS, SQLBits, dataMinds Connect and many others. He frequently delivers educational webinars on MSSQLTips.com. For his efforts, Koen has been awarded the Microsoft MVP data platform award for many years.
- MSSQLTips Awards:
- Leadership Award (200+ Tips) – 2021
- Author of the Year – 2014/2020/2022
- Author Contender – 2024/2025


