Problem
I have a two-node Failover Cluster Instance (FCI) running in the Primary data center and a DR node running in the DR data center. The primary site is completely down due to a storage failure, all the nodes running on the primary site are inaccessible, and the Always On Availability group on the DR replica is in resolving status. What are the steps to resolve this?
Solution
Technical professionals are well aware of the importance of creating and implementing a disaster recovery site. However, I believe they feel true happiness and the importance of a disaster recovery setup when they are involved in an actual disaster with the Primary site completely down and unavailable.
Real World Scenario
This scenario happened to me recently with one of my clients where I was providing SQL Server database administration services. The problem started when all the applications suddenly stopped working due to a storage failure, and unfortunately, all the primary servers were hosted on that storage.
Initially, the problem seemed insignificant, and the employees expected that routine operations would resume shortly. But the actual chaos started when senior management realized that multiple disks failed simultaneously and that their recovery would take longer than the agreed SLA with the storage vendor.
In short, after a few hours of storage failure and no sign of quick storage recovery from the storage vendor, management decided to move only critical applications and databases to the DR site. That’s where we jumped into action.
This tip will discuss all the issues we faced, including the steps to make the DR failover activity successful.
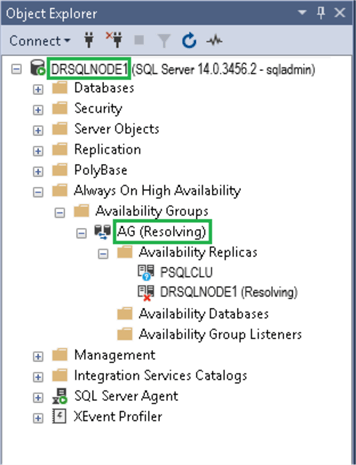
I will not share the environment setup as I need to protect my client, and all server names have been changed throughout this tip. However, the picture below depicts the status of the SQL Server environment for one of the applications after the disaster.

For more clarity, the details of the SQL Server environment are mentioned below, along with the status:
| Description | Name | Status |
|---|---|---|
| Windows Server Failover Cluster (WSFC) | PSQLCLUS01 | Down – Not Connecting |
| Primary Node 1 | PSQLNODE1 | Down |
| Primary Node 2 | PSQLNODE2 | Down |
| DR Node | DRSQLNODE1 | UP |
| Disk Witness | Quorum disk | Down – Not accessible |
| Listener role | PSQL-LSN | Down |
| Availability Group | AG | Resolving |
| Primary Instance (SQL Cluster network name) | PSQLCLU | Down |
| DR Instance | DRSQLNODE1 | UP |
| Operating System | Windows 2016 Server | |
| SQL Server version | 2017 |
Major Steps Performed to Bring WSFC Online and Fix AG Resolving Status
The significant steps performed during this disaster recovery to bring the database up and running and make it accessible to the application are mentioned below.
- Remotely connect to DR Replica, and access the SQL Server database.
- Attempt to failover the Availability group to DR.
- Bring the WSFC up and accessible.
- Remove disk witness from the cluster configuration.
- From the DR replica, attempt to failover the Availability group to the DR replica.
Step 1: Connect to DR Replica and DR Instance
Since our DR node was in a separate data center, this disaster did not affect its storage. Therefore, we were able to access the DR Server. We remotely connected to the DR Server and then connected to the SQL Server DR instance (DRSQLNODE1) using SQL Server Management Studio (SSMS). The primary site was completely down, bringing the availability group to a resolving state, as shown below.
Step 2: Attempt to Failover the AG to the DR Replica
Once connected to the DR instance, we tried to perform AG failover (with data loss) to the DR replica DRSQLNODE1 (this procedure is mentioned in Step 5), but it failed with the following error:
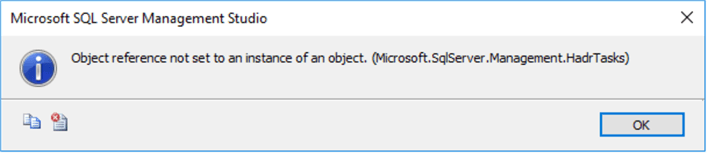
The reason for the failure of AG failover, and the above error, was that the Windows Server Failover Cluster (WSFC) was not accessible.
Step 3: Start and Connect to Windows Server Failover Cluster (WSFC)
When we checked the WSFC, we found that the Windows cluster was not stable, and the cluster service was in the state of “starting” on DRSQLNODE1. As we know, the SQL Server Always On Availability Group and SQL FCI depend on the WSFC. If the WSFC is not running properly, it will impact the Availability Group and failover cluster instance. So now, our first priority was to bring the WSFC UP and running and then attempt to perform AG failover to the DR instance (DRSQLNODE1).
We opened the failover cluster manager from the DR replica (DRSQLNODE1). The cluster status was down, and we could not connect to the WSFC, as shown in the screenshot below.
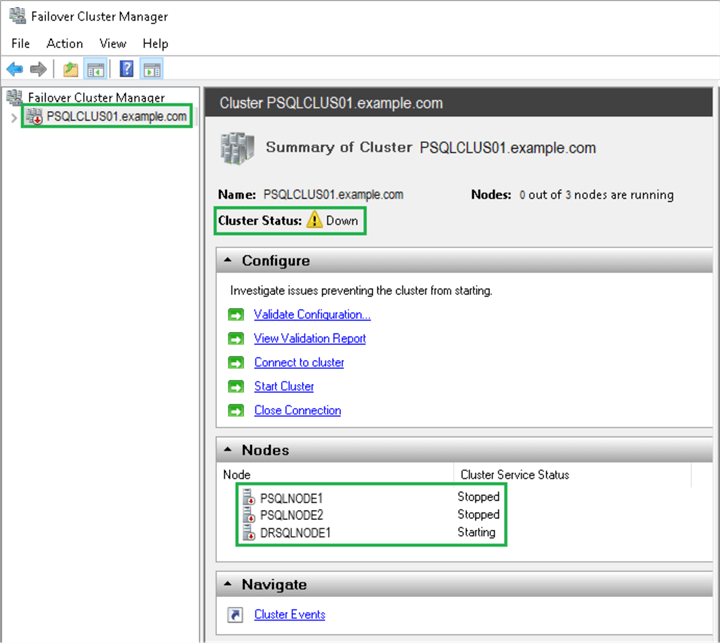
Since the primary nodes (PSQLNODE1 and PSQLNODE2) were down, the cluster service was not running on those nodes. The cluster service on the DR node (DRSQLNODE1) was in a “Starting” state. We must first start the cluster service.
There are multiple ways to bring the WSFC cluster service up and running. In our scenario, we tried the following in sequence.
3.1 Start the Windows Cluster Service through the Services App
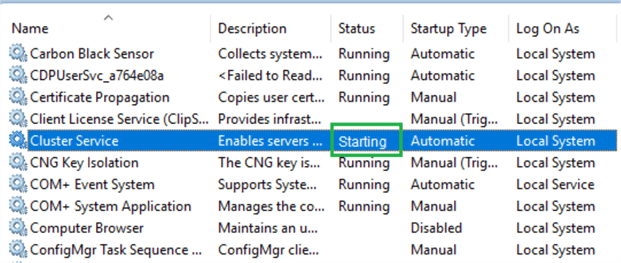
We first attempted to start/restart the cluster service from the Windows services app on the DR Server DRSQLNODE1, using the following steps to start the Cluster Service:
- Open the Run app, type Services.msc, and press Enter.
- All the services of the DRSQLNODE1 server will be visible. Look for the service named Cluster Service.
- Right-click on Cluster Service and click Start.
In my case, the Cluster Service did not start and remained in the Starting state, as shown below. We were still unable to connect to the WSFC.
3.2 Start the Cluster Forcefully without Quorum
Next, we attempted to start the Cluster Service using Net.exe. The WSFC cluster lost the disk witness quorum and multiple nodes, so the cluster would not start normally in this case. We had to force the Cluster to start without a quorum. Since we know that the Cluster Service was already in the “Starting” state and the Start command did not work, we attempted to stop it completely and then start it. For this purpose, we executed the following commands in a Command prompt or Windows PowerShell (as Administrator).
C:\windows\System32> net.exe stop clussvc C:\windows\System32> net.exe start clussvc /forcequorum
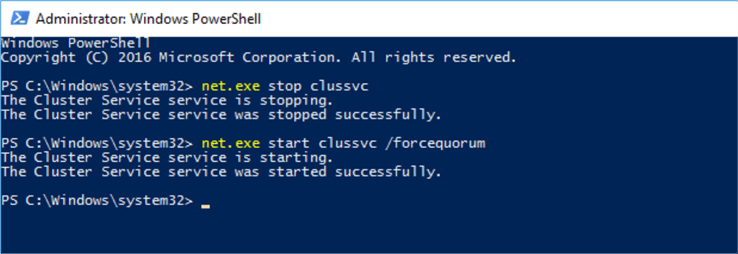
After executing the above commands successfully, we connected to the WSFC through the failover cluster manager, as shown in the screenshot below.
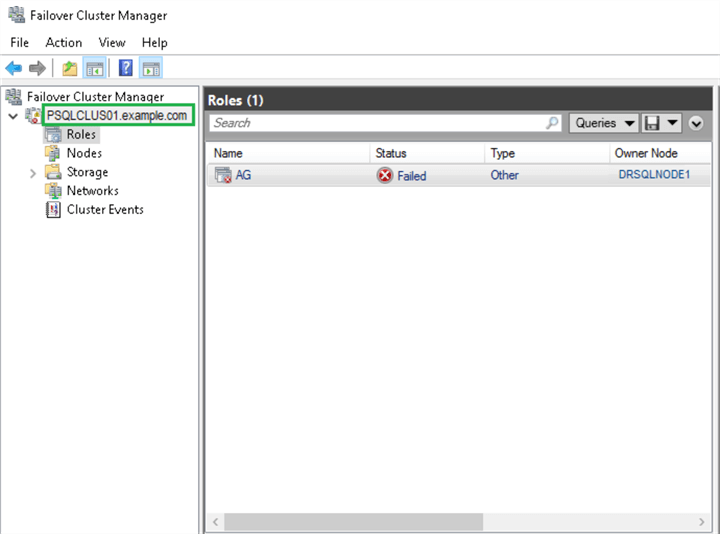
We were able to connect to the WSFC, but the AG remained in a failed state because the Primary Servers were still down. Since we knew that the Primary Servers and the disk witness were inaccessible at the moment, it was better to remove the disk witness from the quorum configuration and revoke the permissions from the Primary Servers to participate in the cluster voting. This way, we would not need to execute the commands to forcefully start the cluster each time we wanted to connect with the WSFC through the failover cluster manager.
Step 4: Remove Disk Witness from the Quorum
To remove the disk witness from the cluster quorum configuration and revoke voting membership permission from the Primary Servers, we performed the following steps:
Right-click on the cluster name, select More Actions, then click on Configure Cluster Quorum Settings...
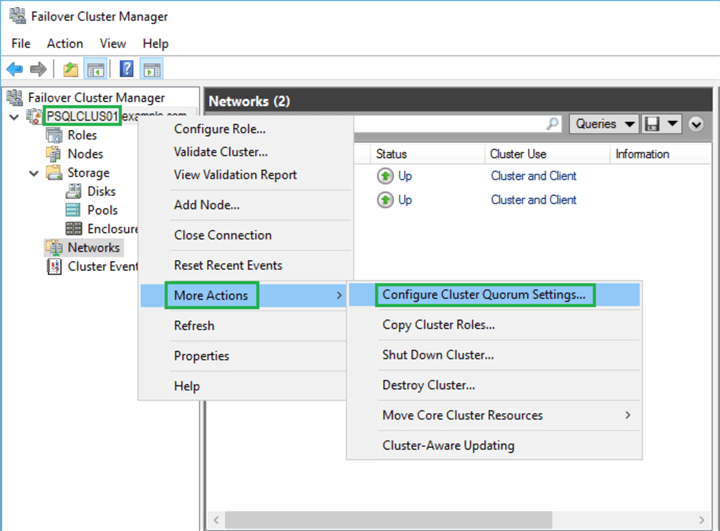
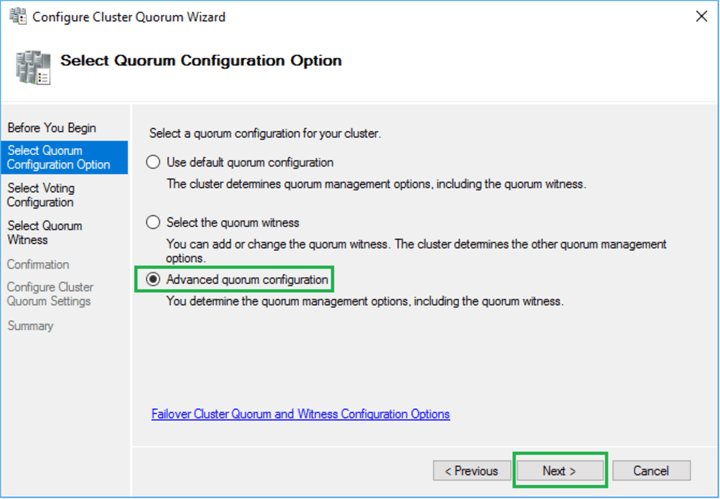
The Configure Cluster Quorum wizard will appear. Click Next. Select the Advanced quorum configuration option, and click Next, as shown in the below screenshot.
On the Select Voting Configuration page, uncheck the votes for the Primary Servers (down) and click on the checkbox for the DRSQLNODE1 node. Click Next.
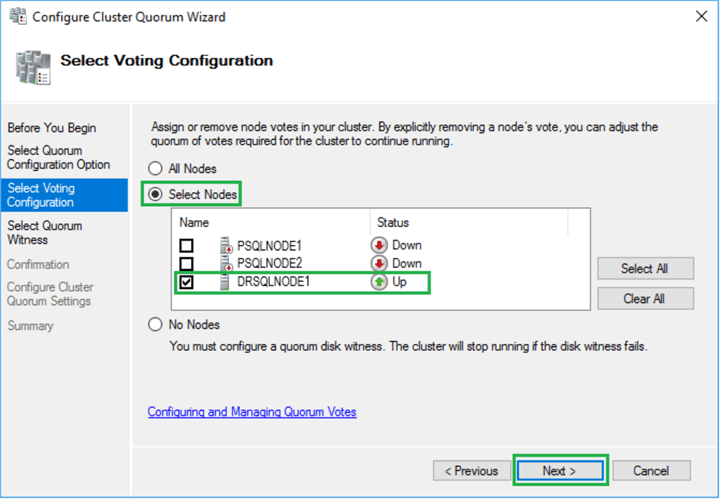
Choose the Do not configure a quorum witness option. Click Next to proceed to the confirmation page.
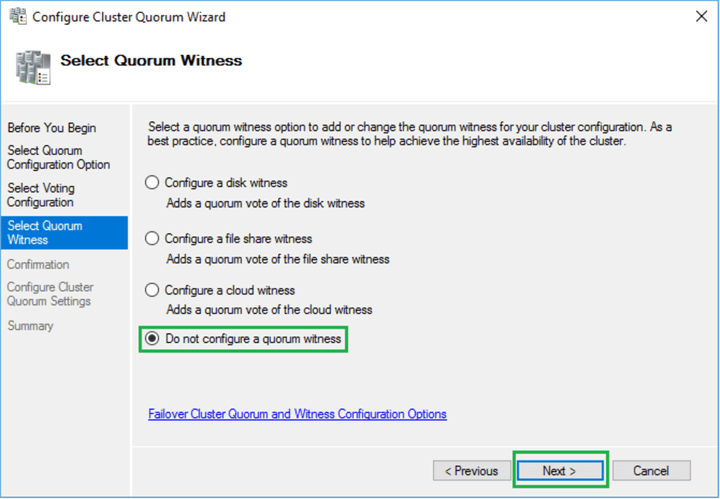
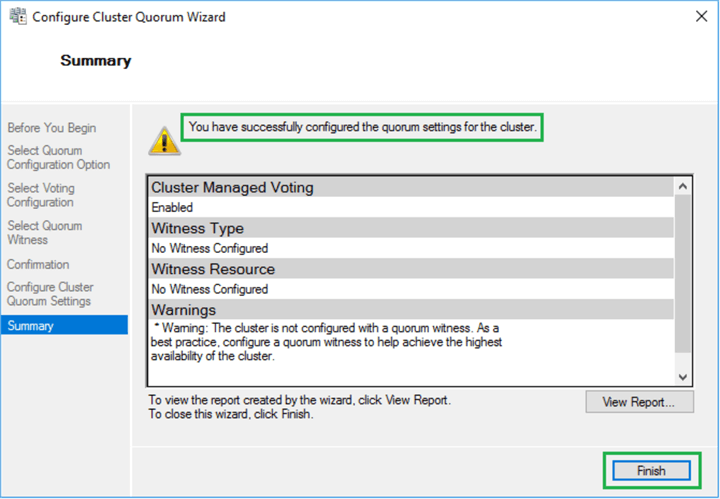
Then click Next on the confirmation page and the Summary page below will appear. Click Finish to apply the new quorum settings.
Step 5: AG Failover to DR Replica (DRSQLNODE1)
At this point, the WSFC was now stable, and we could connect to it. We needed to attempt to failover the Availability Group to the DR Replica. As mentioned earlier, the Availability Group is in a (Resolving) state after the primary site went down.
To do the failover of the Availability Group, we performed the following steps.
Connect to the DR SQL Instance (DRSQLNODE1). Expand the Availability Groups. Right-click on AG (Resolving), and click Failover…
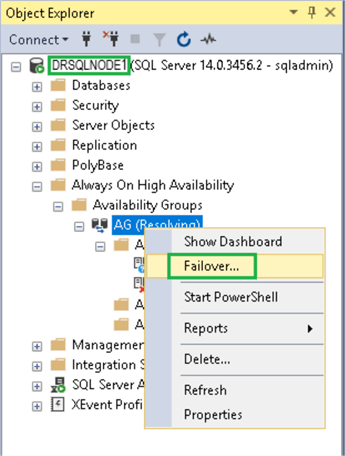
The Fail Over Availability Group: AG wizard will appear (below). Click Next to proceed to the next step.
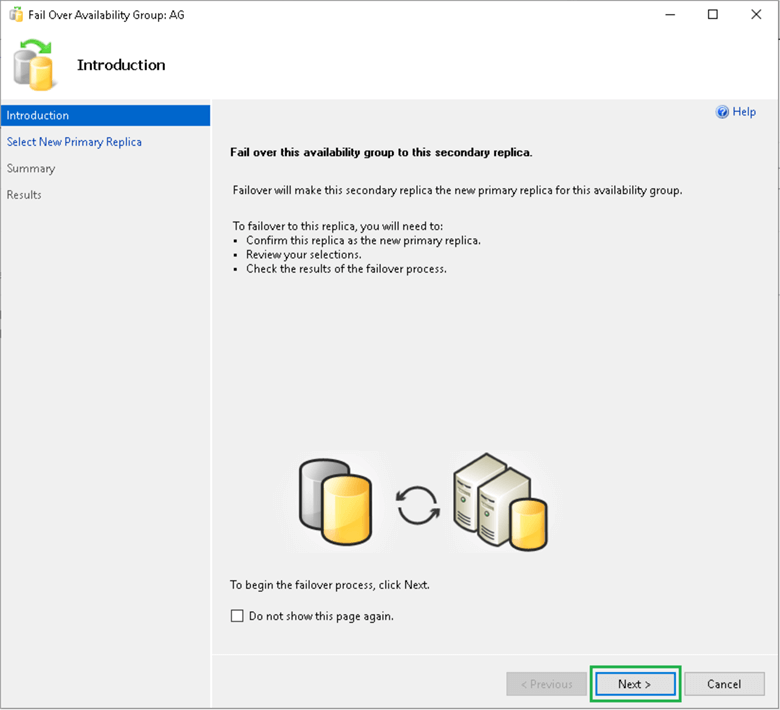
On the Select New Primary Replica page, select the checkbox next to the instance where you want to do AG failover. In this case, it is DRSQLNODE1. Click Next.
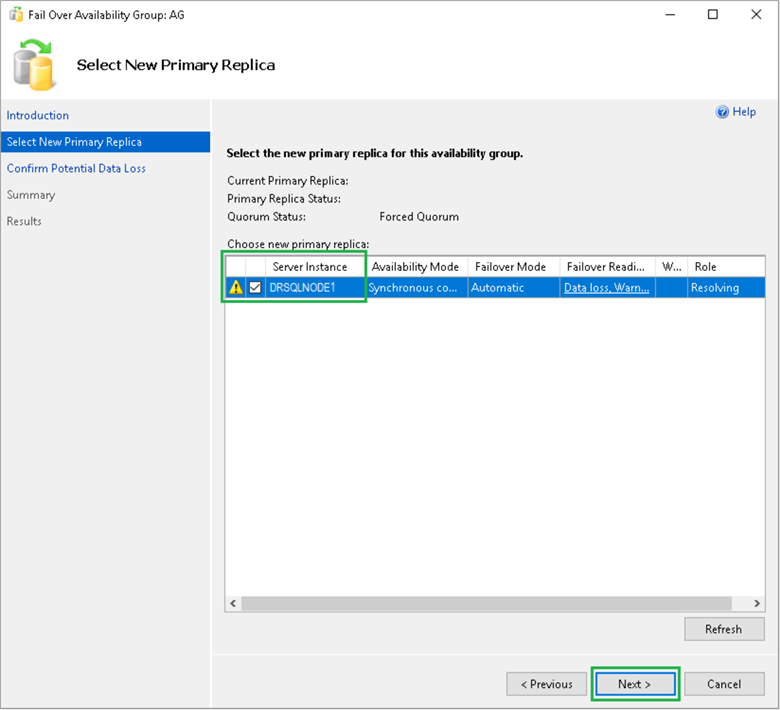
The next page shows a warning concerning data loss if this procedure is performed. Select the checkbox next to “Click here to confirm failover with potential data loss“, and click Next, as shown below.
AG Failover to DR
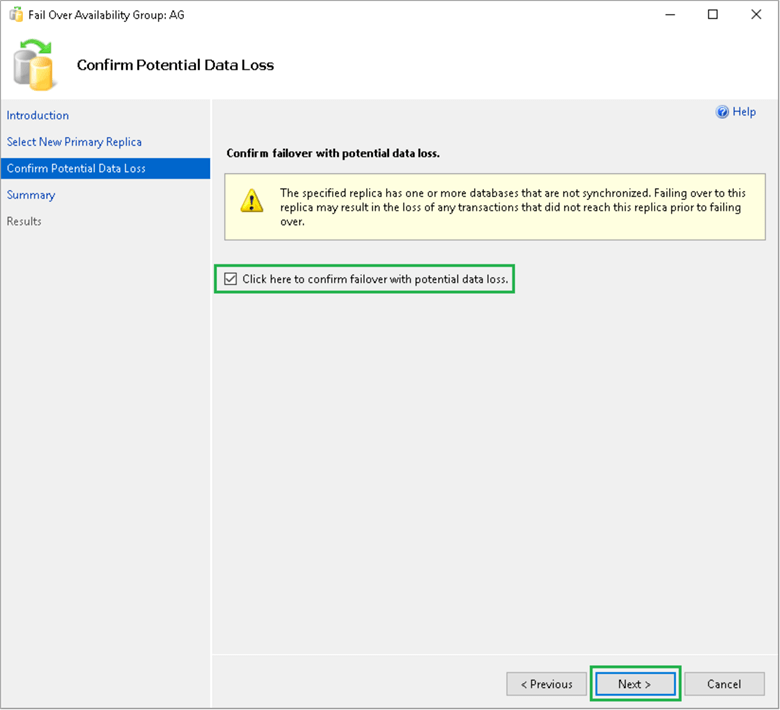
On the Summary page, review the synopsis of the failover actions. Confirm the changes and click Finish to start the AG failover.

You will see either the success or failure message on the last page. As shown below, the Availability Group successfully completed the failover to the DR replica DRSQLNODE1. Click Close to exit the wizard.
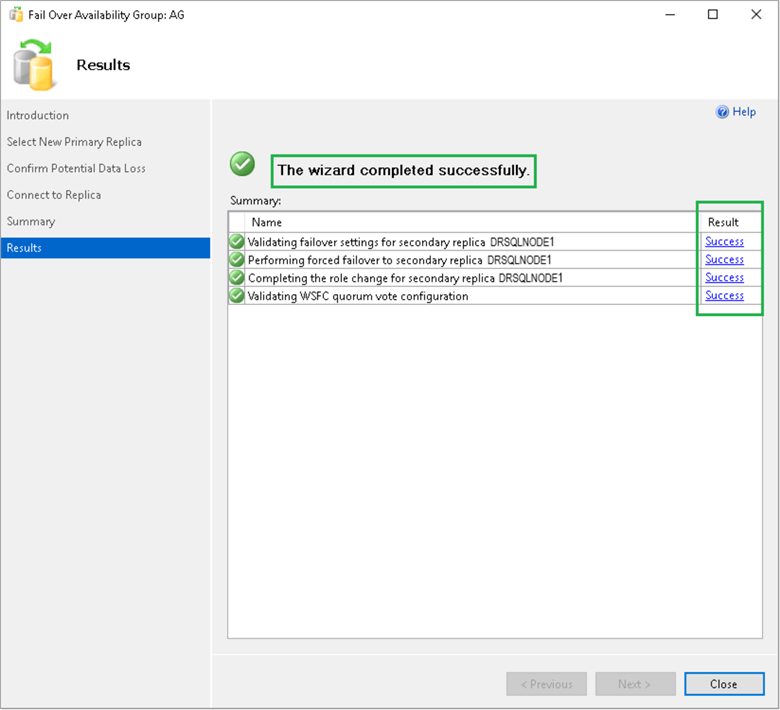
The next step is to connect to the DR SQL Instance (DRSQLNODE1) and confirm that the AG failover was successful.
As shown in the screenshot below, the AG failover was successful, and the DR instance DRSQLNODE1 is the new primary now. So, all the applications using the listener connection string will be directed to the new Primary instance (DRSQLNODE1).
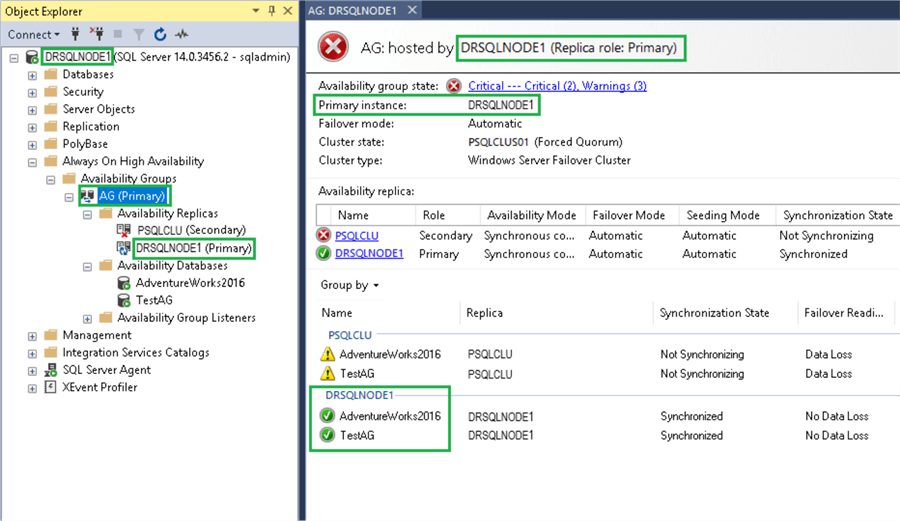
Since the previous primary site (SQL Cluster PSQLCLU) is still down, the databases using the cluster network name “PSQLCLU” for PSQLNODE and PSQLNODE2 are still showing a “Not Synchronizing” state. Once the PSQLNODE1 and PSQLNODE2 are up and SQL is accessible through PSQLCLU, the data synchronization will start with the new secondary FCI (PSQLCLU) (assuming that all the logs required will be available for syncing). The status for all the databases in the AG will change from “Not Synchronizing” to “Synchronized“.
In our SQL environment, as soon as the new secondary replicas were Up, the synching started between the Primary and Secondary replicas, and the Availability Group status became healthy, as shown below.

The Always On Availability Group became healthy after the new secondary servers were up, and we took a deep breath of peace and happiness. I wish good luck to all those who find themselves in the same situation.
Conclusion
In this tip, I shared my experience facing a disaster in a production environment. I shared all the issues we faced during the storage failure on the primary data center and the steps we performed to fix those issues.
Next Steps
- This tip covers the necessary steps to recover from a disaster on the Primary site. Still, it is also useful for people facing only an AG issue (AG in resolving state) OR facing an unstable WSFC, as both these situations are discussed and fixed.
- More topics will be covered on Always On Availability Group and SQL clustering in upcoming tips.

Muhammad Kamran is a Senior SQL DBA with more than 11 years of experience in SQL Server database administration and consultation. He is a Microsoft Certified System Engineer (Data Management & Analytics). He has a Master’s degree in Advance Computer System Development. Currently, he provides services for government clients in Saudi Arabia. Although he covers SQL services in many different areas, his key interest is SQL high availability, disaster recovery, troubleshooting, upgrades and performance tuning. Check out his blog.

Enjoyed the article but some questions.
1. You have accepted Data Loss in the Failover to DR. How did you get the data synchronised when Primary Site nodes came up? If there was data loss during failover would that not stop the synchronization back to primary or would it overwrite what was there?
2. I presumed you added the nodes back into the Quorum?
If there are no communication between the primary and the DR site and we forcefully bring the AG up and make the DR primary how will the old Primary know that the DR server is the new primary when the old primary server comes back.
Once the Old primary and the secondary comes back wont that form a quorum and try to bring the cluster services causing split brain scenario since it does not know whats going on at the DR site
@Farhan
For Any AG environment, you must use the listener to access the database.
Keeping the above point in mind, once forced failover to the DR replica is done, your DR replica becomes your primary replica and any new connection request using the listener will go to the primary replica (which was DR replica earlier).
So there will be no split brain scenario, as the listener will take you to the primary replica only.
Once, your primary site (previously Primary and now Secondary replica) is UP, then it will sync automatically with the new primary replica if no data loss occured at the time of disaster which happened in our case.
I will greatly appreciate if you can explain what happens after you forced failover to the DR site and suddenly the Primary site comes up with all the nodes together but there is no communication between the Primary and the DR site. Now there will be split brain scenario with two writable databases …Will appreciate if you can provide the steps in this scenario,
Hello, I am looking for a procedure to follow in order to be able to modify the IP addresses of SQL Server servers in the case of a cluster without having to stop service (Skype for Business solution) Please help. Thanks