Problem
In a previous tip, you have learned to setup AlwaysOn in SQL Server 2012. After a successful setup and everything seems to be in the right place, you are preparing to test your AlwaysOn to failover to your secondary replica for the first time. The first test is successful, but after testing to swing back again to your primary replica, you find out that automatic failover works only the first time. How come?
Solution
This scenario, where in your automatic failover testing works only on the first time is an expected behavior and there is no cause for alarm.
One important setting that you need to check in this scenario is the setting of “Maximum Failures in the specified period.” This value can be found in the Application property of your failover cluster settings. From your Server Manager console, go to Features > Failover Cluster Manager > Your Cluster > Services and Applications > Your Application > right click and select “Properties.” You should be in the same menu as shown below.
In the property window, click on failover tab. You should see the following in the Failover part;
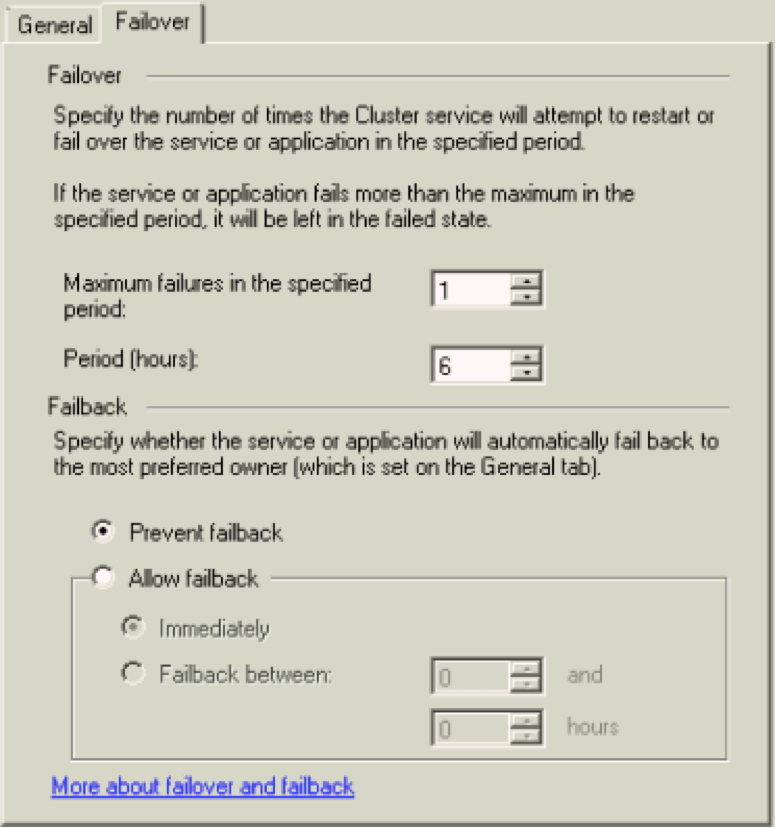
By default the failover property settings for the resource group is:
- Maximum Failures in the specified period is set to (n-1), where n is the number of nodes participating in your cluster. If the number of nodes that you have is 2, subtracted by 1 is equal 1. So your automatic failover will work only the first time after your setup.
- Period (measured in hours) is set to 6.
With these default values, this means that if a failover happens and the resources does not come online, the cluster services tries to get the resources online only once and in 6 hours. These values you can play around during your testing only. When you go Live or roll out to production, these values must reflect your organization’s RTO and RPO documented policies.
As for the failback settings, see bottom part of the image above, you can play around with the 2 options depending on the preferred owner for your cluster. In my case, in the General tab I had the 2 replicas selected as preferred owner, and I opted for the Allow failback with a specified time option.
Generally, these settings are also called the failover threshold. It determines if you have reached the limit of how many failovers you can have in a span of, in the setting above, 6 hours.
Other way that you can verify if this is really what is happening to your testing is to view the cluster logs. A quick way to view the cluster logs is open it in your Failover Cluster Manager > Your cluster > expand this and go to Cluster Events, right click and go to Query. Enter the query you want to filter (the failover that happened) and click OK.
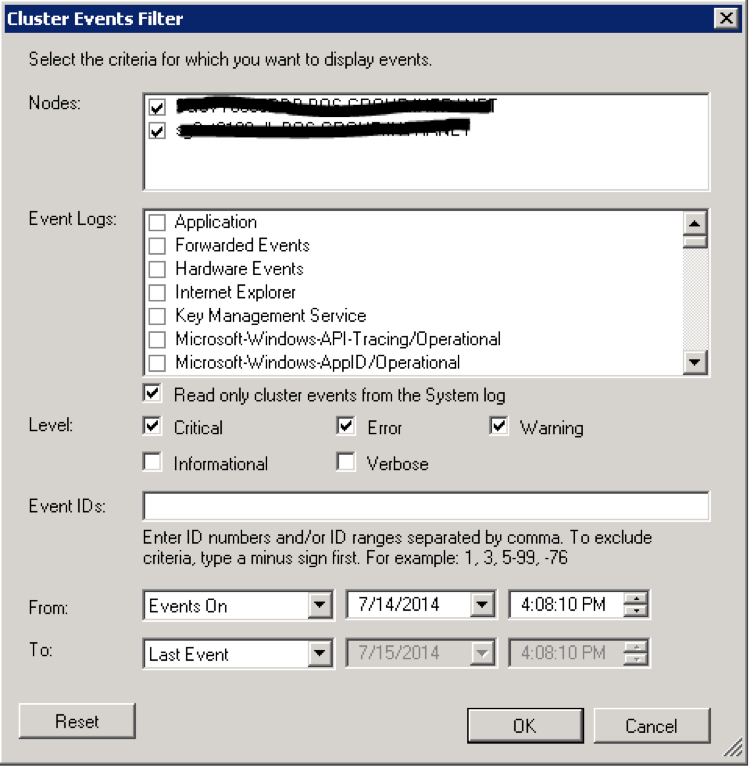
To summarize, what happened in your initial failover test is that you have reached the threshold setting. This threshold setting is to prevent the ping pong scenario of your cluster failing back and forth frequently. If it does happen too frequent for you, then it should be investigated deeply as there could be a more serious cause as to why is this happening. For my case, it was a hardware problem and I had to call the vendor again. It is a good thing that you are still in the testing stage.
Next Steps
- If you are still having issues with your automatic failover testing, you might want to double check if your WSFC is configured correctly. For more help on WSFC configuration, you may click here
- For more tips about AlwaysOn and Availability Groups, click here.

Carla Abanes is a certified Microsoft SQL Server Database Administrator with extensive experience in data architecture and supporting mission critical databases in production environments. She is based in Manila and wears 2 hats at work as a SQL Server Technical Lead and as a Cloud Architect.
She holds a certification in AWS Solutions Architect – Professional and Azure Administration. I am passionate about conceptualizing proof-of-concepts, turning ideas into real applications and overcoming challenges that come with the execution and delivery of solutions.
