Problem
There may come a time when you need to do a manual failover of your SQL Server AlwaysOn Availability Groups. Sometimes the replicas are not synchronized and you have to perform a forced failover. In this tip we cover the steps you need to follow.
Solution
For this tip, consider a scenario with the AlwaysOn Availability Group configuration that consists of a primary site that hosts synchronous-commit availability replicas and a secondary site that hosts asynchronous-commit secondary replicas. The following figure illustrates this scenario:
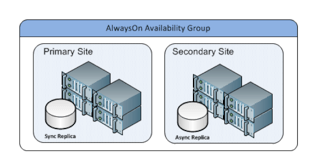
Now suppose we cross out the primary site from the diagram above due to an unforeseen issue and the Availability Group fails over to the secondary site. When this happens, the secondary site will assume the role of the primary site. After you are able to bring up the primary site, you will need to perform a forced failover from the secondary site. You need to bring back the primary site to its primary role and the secondary site back to its secondary role.
A forced failover is a form of manual failover that is intended strictly for disaster recovery. If you force failover to an unsynchronized secondary replica, you need to consider that data loss is possible. It is strongly recommended that you force failover only if you must restore service immediately to the Availability Group and the possibility of data loss is acceptable.
Steps to Perform Force Failover for SQL Server AlwaysOn Availability Groups
The recovery plan should have these three steps:
- Take into consideration the possibility of data loss and communicate this to the application support team.
- Perform a forced failover on the secondary replica.
- Resume data movement.
Step 1 – Check for Potential Data Loss
From step 1, you need to consider that there is a possibility of data loss. This should be communicated with the development and application support teams. To verify potential data loss in your secondary replica at the time of failure or disaster, check the column is_failover_ready from the SQL Server DMV dm_hadr_database_replica_cluster_states.
Execute the code below:
USE master; GO SELECT is_failover_ready, * FROM sys.dm_hadr_database_replica_cluster_states WHERE replica_id = (SELECT replica_id FROM sys.availability_replicas WHERE replica_server_name = 'yourreplicanamehere') GO
If is_failover_ready = 1 on a database for a given secondary replica, you can execute the ALTER AVAILABILITY GROUP with the option FORCE_FAILOVER_ALLOW_DATA_LOSS without data loss on this secondary replica. Otherwise, if the value is 0 and if you force the failover to your secondary replica, data loss is possible.
Step 2 – Perform Failover
After considering the possibility of data loss, the next step is to perform a manual failover to the secondary site. The manual failover transitions the secondary replica to the primary role and suspends the secondary databases. Also note that at this point, data movement from the primary site to secondary site is suspended.
To do a manual failover, you may execute the code below:
USE master; GO ALTER AVAILABILITY GROUP 'youragnamehere' FAILOVER GO
Alternatively, to force the failover with possible data loss, based on your checking for data loss from step 1, you can execute the following code:
USE master; GO ALTER AVAILABILITY GROUP 'youragnamehere' FORCE_FAILOVER_ALLOW_DATA_LOSS GO
The above statements requires ALTER AVAILABILITY permission or CONTROL SERVER permission.
Alternatively, the manual failover can be also done via SQL Server Management Studio. From Object Explorer, expand Availability Groups > right click on the Availability Group to failover and select Failover. This will launch the Failover Wizard window.
After you have considered the possibility of data loss and you have completed the failover with the correct option, go to step 3 from the recovery plan described above.
Step 3 – Resume Data Movement
To resume data movement from the primary to secondary replica, execute the following statement on the secondary replica:
USE master; GO ALTER DATABASE 'yourdatabasenamehere' SET HADR RESUME GO
If for some reason, the database is still in a resolving state, consider the option of setting it offline and then set it back online again. To do this execute the statements below:
USE master; GO ALTER DATABASE 'yourdatabasenamehere' SET OFFLINE WITH ROLLBACK IMMEDIATE ALTER DATABASE 'yourdatabasenamehere' SET ONLINE RESTORE DATABASE 'yourdatabasenamehere' WITH RECOVERY
The code above may be used also for other scenarios, not only for databases participating in an SQL Server Availability Group.
At this point, we have covered all the steps in our recovery plan. To verify that everything is in place, view the dashboard of your Availability Group in SQL Server Management Studio. All servers should be green and your primary and secondary replica should have the correct roles. Also the database has resumed its data movement. All your databases in the primary replica should display as “Synchronized” and all your databases in the secondary replica should display as “Synchronizing”.
Next Steps
- After a successful recovery, you need to perform a routine health check on your primary and secondary replicas together with your application team.
- Prepare documentation of your recovery process and procedures for all your Availability Groups in the event of failover or disaster recovery. Include the steps performed in this tip.
- For more information on the Failover Availability Group Wizard.
- For more information on AlwaysOn Availability Groups.

Carla Abanes is a certified Microsoft SQL Server Database Administrator with extensive experience in data architecture and supporting mission critical databases in production environments. She is based in Manila and wears 2 hats at work as a SQL Server Technical Lead and as a Cloud Architect.
She holds a certification in AWS Solutions Architect – Professional and Azure Administration. I am passionate about conceptualizing proof-of-concepts, turning ideas into real applications and overcoming challenges that come with the execution and delivery of solutions.
