Problem
In database management, deadlocks are a common problem that can arise when multiple transactions try to modify the same data. If not properly handled, deadlocks can cause data inconsistencies, leading to serious consequences for your applications. In this article, we will discuss deadlocks in Snowflake, how they occur, how Snowflake deals with them, and how it differs from SQL Server deadlock management.
Solution
A deadlock in Snowflake occurs when two or more transactions are waiting for each other to release a lock on a resource. The result is that both transactions are blocked and unable to progress further, leading to a deadlock scenario. This can cause your application to stop responding or processing data.
Let’s look at an example of a deadlock in Snowflake and explain how to handle it.
We will start with creating a test environment:
CREATE TABLE TESTDB.TESTSCHEMA.TableA (
ID INT,
Val CHAR(1)
);
INSERT INTO TESTDB.TESTSCHEMA.TableA (Val)
VALUES ('A'), ('B');
CREATE TABLE TESTDB.TESTSCHEMA.TableB(
ID INT IDENTITY,
Val CHAR(1)
);
INSERT INTO TESTDB.TESTSCHEMA.TableB (Val)
VALUES ('C'), ('D') ;
SELECT * FROM TESTDB.TESTSCHEMA.TableA;
SELECT * FROM TESTDB.TESTSCHEMA.TableB;
Now, consider a situation where two transactions try to update the same data in these tables simultaneously. To demonstrate this, we will copy the following two pieces of code in two separate worksheets:
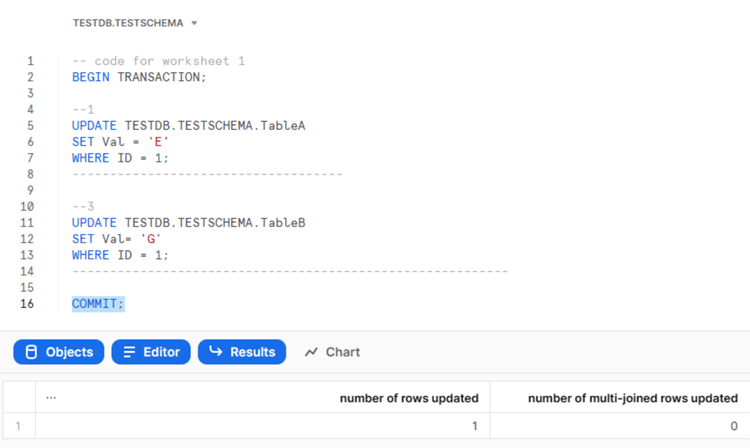
-- code for worksheet 1 BEGIN TRANSACTION; --1 UPDATE TESTDB.TESTSCHEMA.TableA SET Val = 'E' WHERE ID = 1; ------------------------------------ --3 UPDATE TESTDB.TESTSCHEMA.TableB SET Val= 'G' WHERE ID = 1; ------------------------------------------------------------- COMMIT; -- code for worksheet 2 BEGIN TRANSACTION; --2 UPDATE TESTDB.TESTSCHEMA.TableB SET Val = 'F' WHERE ID = 1; -------------------------------------- --4 UPDATE TESTDB.TESTSCHEMA.TableA SET Val = 'H' WHERE ID = 1; COMMIT;
Start by running the first step in the first transaction:

Follow this with the second step in the second transaction:
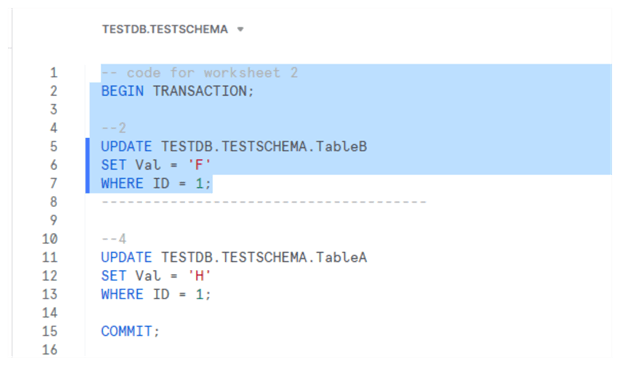
After that, run the third step in the first transaction:

Finally, run the fourth step in the second transaction:
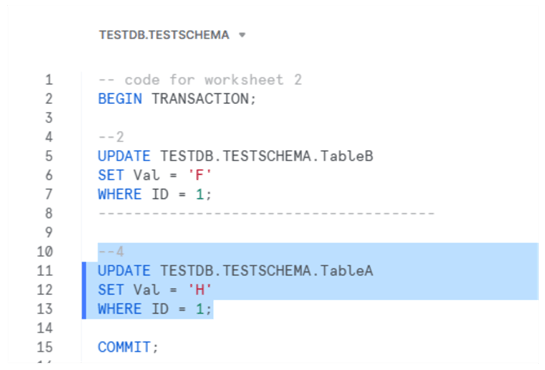
We can see that both transactions are blocked:

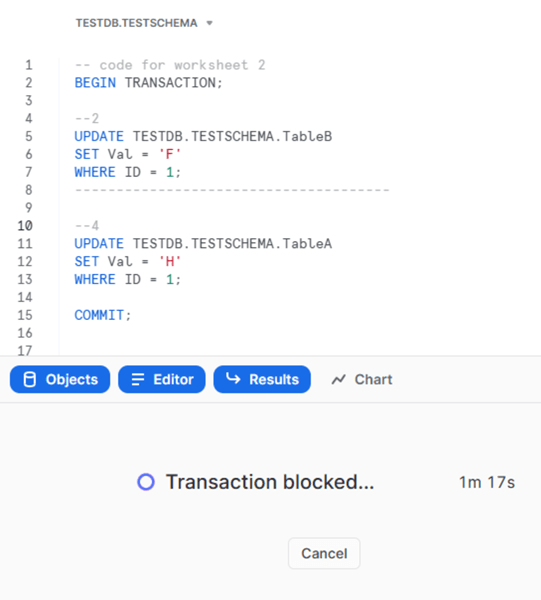
This happened because two transactions were trying to update the same rows in the table simultaneously.
Now, let’s open another worksheet and paste the following code for monitoring:
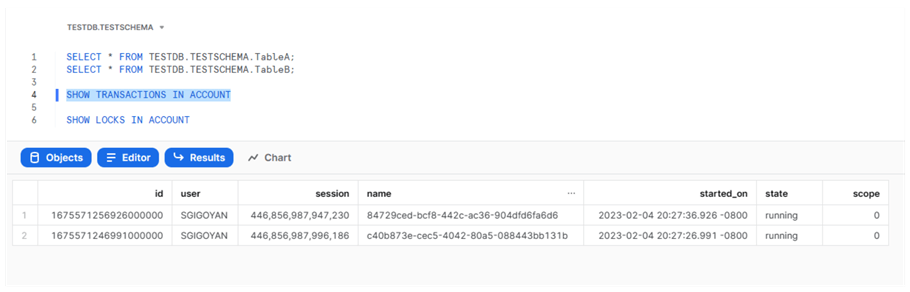
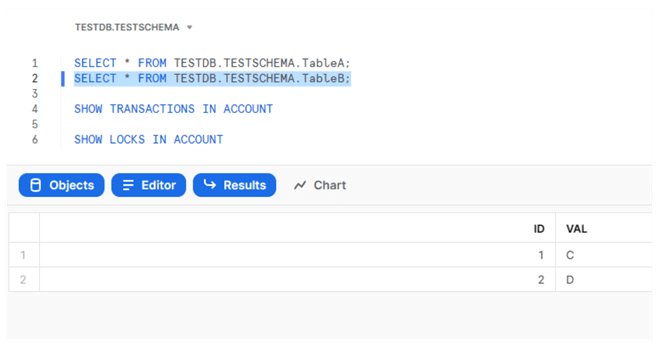
SELECT * FROM TESTDB.TESTSCHEMA.TableA; SELECT * FROM TESTDB.TESTSCHEMA.TableB; SHOW TRANSACTIONS IN ACCOUNT SHOW LOCKS IN ACCOUNT
We can see that our two transactions are running, as seen in the image below.
We can also see the locks using the SHOW LOCKS command:

The data in the tables is not changed since the Snowflake transaction isolation level is READ COMMITTED, and changes in uncommitted transactions are not visible in other sessions:

After some time (our example took 5 minutes and 4 seconds), we see the following result:
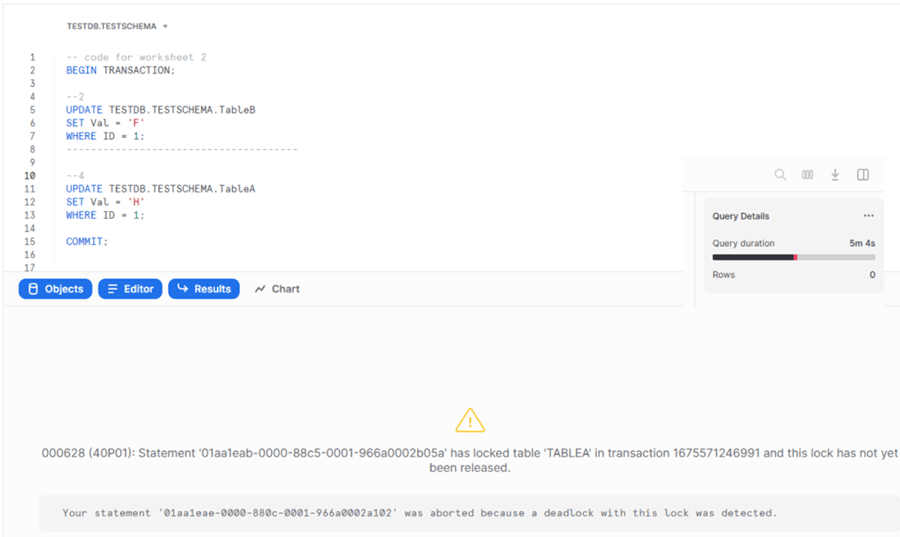
The last statement in the second transaction is aborted because of the deadlock. It was the most recent statement, a part of the deadlock, and was chosen as the deadlock victim. This is the way how Snowflake selects the victim of the deadlock. The statement itself is rolled back, but the transaction remains active. This can be checked if we query the TableB data in the second worksheet:

In this session, the first change of the second transaction is visible, but the second row is not changed as the statement is rolled back. In the worksheet for monitoring, we can still see both transactions running:

The first transaction is still blocked:

Now, let’s roll back the second transaction:

And commit the first one (which is not blocked anymore):
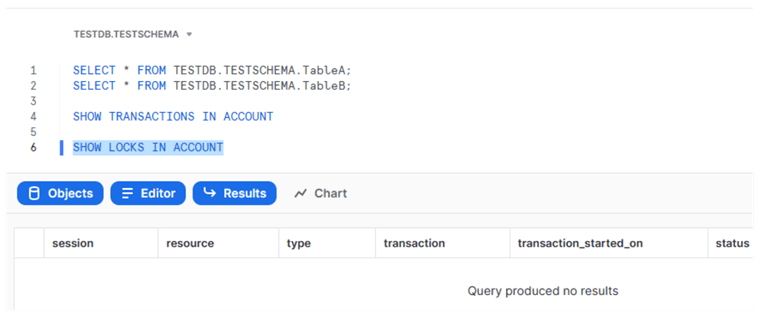
After that, we do not have active transactions:

And there are no locks:
The tables are updated only by the first transaction:


Deadlocks in SQL Server vs. Snowflake
While the idea of deadlock is the same for both systems, managing deadlocks is a bit different in each system.
In the event of a deadlock in the SQL Server, the system will pick one of the sessions as the "deadlock victim" to resolve the situation. This decision is based on the priority assigned to each session, with the session with the lower priority being chosen. If both sessions have the same priority, the system will determine which would be less costly to roll back by considering the number of log bytes written in each transaction. The selected session’s current transaction is then rolled back, releasing its locks and allowing the other session to continue.
Like in SQL Server, Snowflake automatically detects deadlocks. Unlike SQL Server, which chooses the less costly transaction to roll back, Snowflake selects the most recent statement involved in the deadlock as the victim. In Snowflake, the chosen statement is rolled back, but the entire transaction remains ongoing and must either be committed or rolled back. It’s important to note that the process of detecting deadlocks can be significantly time-consuming.
Conclusion
In conclusion, deadlocks can be a serious problem in Snowflake and cause significant delays and lost productivity. Although Snowflake provides mechanisms to detect and handle them, this process can be time-consuming. Hence, to prevent deadlocks, it is important to understand the root cause of deadlocks and take steps to avoid them by designing and managing your transactions properly.
Next Steps
For additional information, please follow the links below:
- Transactions — Snowflake Documentation
- Deadlocks – Snowflake Documentation
- SQL Deadlock Priority to Control Transaction Roll Backs
- Monitor Deadlocks in SQL Server with system_health Extended Events
- Snowflake Transactions vs SQL Server Transactions

Sergey Gigoyan (LinkedIn) is a Senior Technical Architect specializing in data and databases with more than 15 years of experience. Sergey focuses on modern data architectures, database design and development, performance tuning and optimization, high availability solutions, BI development and DW design. He has worked with SQL Server, Oracle, and PostgreSQL databases, as well as cloud-based data solutions (AWS and Azure). Sergey also has extensive experience with modern data stacks such as Snowflake and dbt.
Sergey’s experience spans various industries. He had the privilege of working with IT giants such as Oracle as a Principal Data Engineer and BlackBerry as well as innovative startups. He helped deliver complex database solutions and advanced data strategies.
Sergey is also the author of “Building a Successful Career in IT – How I Did It” where he provides actionable advice on thriving in the ever-evolving IT industry.
- MSSQLTips Awards: Champion (100+ tips) – 2024 | Author of the Year – 2020


