Problem
As Snowflake is becoming more and more popular, many Microsoft SQL Server developers are starting to learn it in order to fit the modern and growing market needs. Hence, I have decided to start a series of tutorials aimed at helping developers with extensive SQL Server experience in learning Snowflake. I believe that for these kinds of specialists, an easier and more effective way of understanding a common conception in Snowflake can be the comparison of a concept with the corresponding concept in SQL Server. This is why in each article we will focus on a particular concept in Snowflake and shed light on it by comparing it with the corresponding technology in SQL Server. Please note that these articles are not for complete beginners in Snowflake. It is assumed that the reader already has a basic working experience with Snowflake and wants to understand the main principles in a more detailed way.
Solution
To begin with, let’s pick up one of the most common topics of the database management systems – transactions, and discuss how they are implemented in Snowflake by comparing them with the transactions in SQL Server. As transactions are quite a wide and popular topic, one article will not be enough to explore them. Thus, the first group of articles of this series will be devoted to transactions. In this article, we will discuss nested transactions, transaction isolation levels, and dirty reads.
Transaction Isolation Levels
Unlike SQL Server, which supports five transaction isolation levels – READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ, SNAPSHOT, and SERIALIZABLE, Snowflake supports only one – READ COMMITTED. This means that Snowflake does not support mechanisms for preventing non-repeatable reads and Phantom inserts (that SQL Server does), but only protects from dirty reads.
Dirty Reads
As mentioned above, the only transaction isolation level in Snowflake is READ COMMITTED. So, unlike SQL Server, there is no READ UNCOMMITTED isolation level, and, therefore, there are no dirty reads in Snowflake. Thus, as there is no way to read uncommitted data in Snowflake, there is no NOLOCK table hint in Snowflake. Moreover, it is also impossible to skip rows that are locked by other transactions. In other words, there is nothing like SQL Servers READPAST table hint.
Nested Transactions
In SQL Server, transactions can be nested. This means that it is possible to start a new transaction within an existing transaction. In contrast, it is not possible to have nested transactions in Snowflake. In SQL Server, if after the first BEGIN statement, we execute another one, that will open a new transaction and the current transaction count will be increased by one. If we do the same in Snowflake, the second BEGIN statement will just be ignored and we will still have only one transaction.
Let’s explore these differences by examples. First, we will create test environments both in SQL Server and Snowflake.
In SQL Server Management Studio (SSMS), we open a new query window and run the code below to create a sample database with a sample schema and table:
--MS SQL Server
CREATE DATABASE TESTDB
GO
USE TESTDB
GO
CREATE SCHEMA TESTSCHEMA
GO
CREATE TABLE TESTDB.TESTSCHEMA.TESTTABLE(ID INT)
GO

In Snowflake Web Interface, we open a new worksheet, and run the following code to create a similar environment in Snowflake:
--Snowflake
CREATE DATABASE TESTDB;
CREATE SCHEMA TESTDB.TESTSCHEMA;
CREATE TABLE TESTDB.TESTSCHEMA.TESTTABLE(ID INT);

In SSMS, let’s open a new query window and run code with nested transactions:
--MS SQL Server
USE TESTDB
GO
SELECT @@TRANCOUNT AS TransactionCount_BeforeFirstTransaction
BEGIN TRANSACTION
SELECT @@TRANCOUNT AS TransactionCount_AfterFirstTransaction
INSERT INTO TESTSCHEMA.TESTTABLE(ID) VALUES (1), (2)
BEGIN TRANSACTION
SELECT @@TRANCOUNT AS TransactionCount_AfterSecondTransaction
INSERT INTO TESTSCHEMA.TESTTABLE(ID) VALUES (3), (4)
COMMIT
SELECT @@TRANCOUNT AS TransactionCount_AfterFirstCommit
COMMIT
SELECT @@TRANCOUNT AS TransactionCount_AfterSecondCommit
SELECT * FROM TESTSCHEMA.TESTTABLE
As we can see, after the first BEGIN TRANSACTION statement, we have one active transaction. After the second BEGIN TRANSACTION statement, we have two active transactions. Also, we can see that each COMMIT statement reduces the transactions count by one:

Now, let’s open a new worksheet in Snowflake and paste the following code that includes nested BEGIN TRANSACTION statements:
--Snowflake
--TransactionCount_BeforeFirstTransaction
SHOW TRANSACTIONS;
BEGIN TRANSACTION;
--TransactionCount_AfterFirstTransaction
SHOW TRANSACTIONS;
INSERT INTO TESTSCHEMA.TESTTABLE(ID) VALUES (1), (2);
BEGIN TRANSACTION; --Will be ignored
--TransactionCount_AfterSecondTransaction
SHOW TRANSACTIONS;
INSERT INTO TESTSCHEMA.TESTTABLE(ID) VALUES (3), (4);
COMMIT;
--TransactionCount_AfterFirstCommit
SHOW TRANSACTIONS;
COMMIT;
--TransactionCount_AfterSecondCommit
SHOW TRANSACTIONS;
SELECT * FROM TESTSCHEMA.TESTTABLE;
We can see that we have one active transaction after the first BEGIN TRANSACTION statement:

However, unlike the SQL Server example, after the second BEGIN TRANSACTION, we still have one active transaction and from the ID it is clear that it is the same transaction. This means that the second BEGIN TRANSACTION statement changes nothing. It is just ignored:

The first COMMIT statement commits the only transaction and after that, we do not have open transactions. The second COMMIT is just ignored in this case:

It is clear, that our table is loaded and the result is the same as what happened in SQL Server. However, in this example, the table is loaded by using one transaction but in the SQL Server example two transactions are actually used:

Now, let’s see an example with the ROLLBACK statement:
--MS SQL Server
DELETE FROM TESTSCHEMA.TESTTABLE
USE TESTDB
GO
SELECT @@TRANCOUNT AS TransactionCount_BeforeFirstTransaction
BEGIN TRANSACTION
SELECT @@TRANCOUNT AS TransactionCount_AfterFirstTransaction
INSERT INTO TESTSCHEMA.TESTTABLE(ID) VALUES (1), (2)
BEGIN TRANSACTION
SELECT @@TRANCOUNT AS TransactionCount_AfterSecondTransaction
INSERT INTO TESTSCHEMA.TESTTABLE(ID) VALUES (3), (4)
ROLLBACK
SELECT @@TRANCOUNT AS TransactionCount_AfterFirstCommit
COMMIT
SELECT @@TRANCOUNT AS TransactionCount_AfterSecondCommit
SELECT * FROM TESTSCHEMA.TESTTABLE
The ROLLBACK statement rolled back all transactions and the @@TRANCOUNT became equal to 0. Thus, the COMMIT statement fails as there are no open transactions to commit:

In Snowflake also, the ROLLBACK statement will roll back the transaction (there is only one transaction in this case):
--Snowflake
DELETE FROM TESTTABLE;
--TransactionCount_BeforeFirstTransaction
SHOW TRANSACTIONS;
BEGIN TRANSACTION;
--TransactionCount_AfterFirstTransaction
SHOW TRANSACTIONS;
INSERT INTO TESTSCHEMA.TESTTABLE(ID) VALUES (1), (2);
BEGIN TRANSACTION; --Will be ignored
--TransactionCount_AfterSecondTransaction
SHOW TRANSACTIONS;
INSERT INTO TESTSCHEMA.TESTTABLE(ID) VALUES (3), (4);
ROLLBACK;
--TransactionCount_AfterFirstCommit
SHOW TRANSACTIONS;
COMMIT;
--TransactionCount_AfterSecondCommit
SHOW TRANSACTIONS;
SELECT * FROM TESTSCHEMA.TESTTABLE;
The COMMIT statement does not fail in this case as it is ignored:
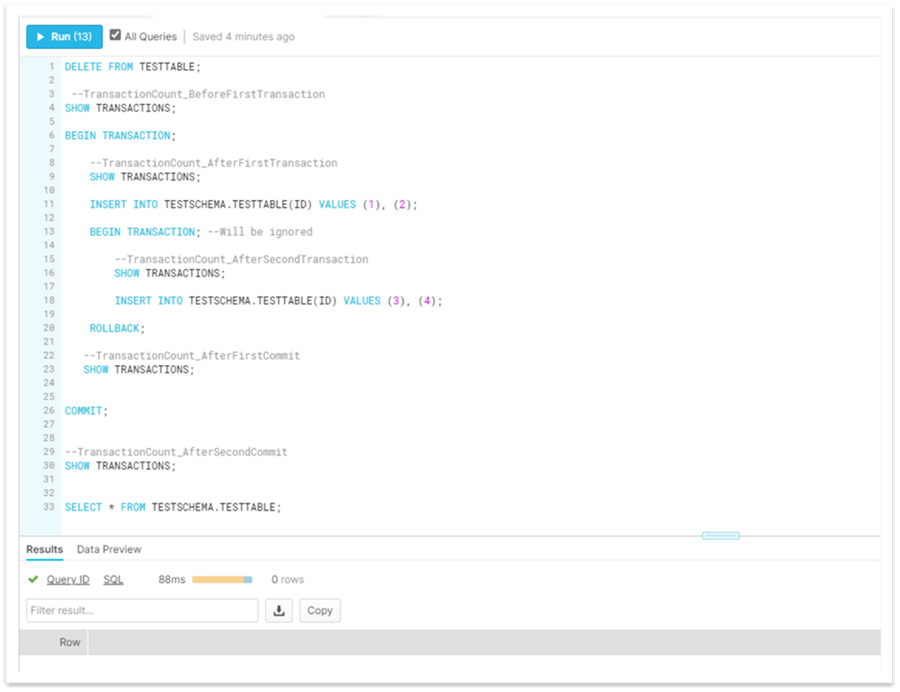
So, in both cases, we have no data in the table as the transaction(s) are rolled back.
Conclusion
While there are some similarities in transaction management mechanisms of these two database management systems, there are also lots of differences. As we can see, the transaction management system in SQL Server is much more robust compared to Snowflake. Having said that, it is worth remembering that, unlike SQL Server, Snowflake is not aimed at supporting OLTP systems, but OLAP. Therefore, it is reasonable to have a less developed transaction management system.
Next Steps
For additional information, please follow the links below:
- Snowflake Transactions reference
- Snowflake Transactions Isolation Level
- Snowflake Begin Transaction
- Snowflake Rollback Transaction
- Compare SQL Server NOLOCK and READPAST Table Hints
- DDL commands in Transactions in SQL Server versus Oracle
- Compare Repeatable Read and Serializable SQL Server Transaction Isolation Levels
- SQL Server READ_COMMITTED_SNAPSHOT Database Option and READ COMMITED Transaction Isolation Level
- Comparison of SQL Server Serializable and Snapshot isolation levels
- READ_COMMITTED_SNAPSHOT and SNAPSHOT_ISOLATION levels in SQL Server

Sergey Gigoyan (LinkedIn) is a Senior Technical Architect specializing in data and databases with more than 15 years of experience. Sergey focuses on modern data architectures, database design and development, performance tuning and optimization, high availability solutions, BI development and DW design. He has worked with SQL Server, Oracle, and PostgreSQL databases, as well as cloud-based data solutions (AWS and Azure). Sergey also has extensive experience with modern data stacks such as Snowflake and dbt.
Sergey’s experience spans various industries. He had the privilege of working with IT giants such as Oracle as a Principal Data Engineer and BlackBerry as well as innovative startups. He helped deliver complex database solutions and advanced data strategies.
Sergey is also the author of “Building a Successful Career in IT – How I Did It” where he provides actionable advice on thriving in the ever-evolving IT industry.
- MSSQLTips Awards: Champion (100+ tips) – 2024 | Author of the Year – 2020



There’s also only 1 transaction active in SQL Server. Docs might call it nested, but you can verify it by running a trace to see that even if you use BEGIN TRAN statement nested, only 1 transactionID will be in trace. So that behaves like Snowflake transactions.
Constantine Kokkinos, please find this terminology in official sources:
https://docs.microsoft.com/en-us/sql/t-sql/language-elements/begin-transaction-transact-sql?view=sql-server-ver16
SQL server transactions cannot be nested.