By: Koen Verbeeck
Overview
Once you've defined a linked service, ADF knows how to connect and authenticate with a specific data store, but it still doesn't know how the data looks like. In this section we explore what datasets are and how they are used.
The Purpose of Datasets
Datasets are created for that purpose: they specify how the data looks like. In the case of a flat file for example, they will specify which delimiters are used, if there are text qualifiers or escape symbols used, if the first row is a header and so on. In the case of a JSON file, a dataset can specify the location of the file, and which compression or encoding used. Or if the dataset is used for a SQL Server table, it will just specify the schema and the name of the table. What all types of datasets have in common is that they can specify a schema (not to be mistaken with a database schema like "dbo"), which is the columns and their data types that are included in the dataset.
Datasets are found in the Author section of ADF Studio (the pencil icon). There you can find the two datasets that were created in a previous part of the tutorial with the Copy Data tool.
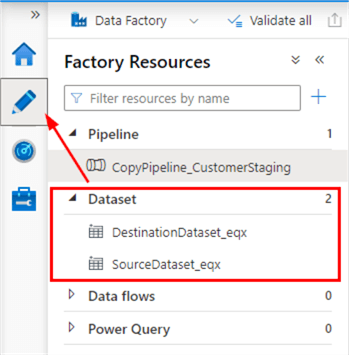
Which Types of Datasets are there?
For most linked services, a dataset type typically maps 1-to-1 to the linked service (see the previous part for a list of linked service types). For example, if the linked service is SQL Server (or any other relational database), the dataset will be a table. If you choose some type of file storage (e.g. Azure Blob Storage, Azure Data Lake, Amazon S3 etc.), you can choose between a list of supported file types:

Keep in mind some datasets type can be supported as a source, but not a sink. An example of this scenario is the Excel format. Or some types of datasets can be used in certain activities in a pipeline, but not in other activities. For a good overview of what is possible for which type of datasets, check out the official documentation.
Creating a Dataset Manually
We're going to create a dataset that reads in an Excel file (with the exact same customer data as in the previous parts). You can download the Excel file here. Upload it to the same blob container we used before.
In the Author section, expand the datasets section, hover with your mouse over the ellipsis and choose New dataset in the popup.
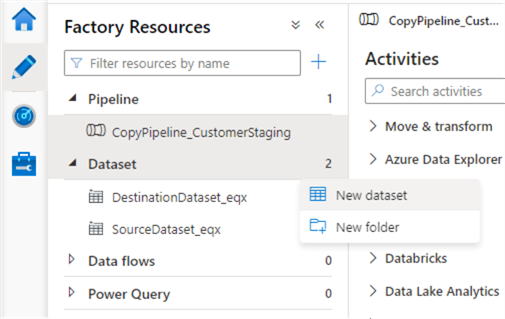
For the data store, choose Azure Blob Storage.
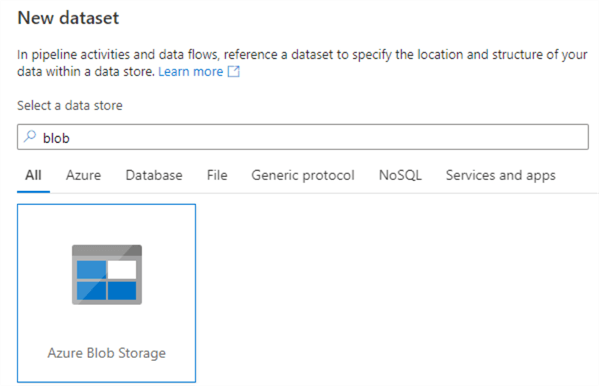
In the next screen, choose Excel as the file format.

In the properties window, give the dataset a name, choose the blob linked service we created in the previous parts and browse to the Excel file in the blob container. Choose the Customers worksheet, set the first row as header and choose to import the schema from the connection.
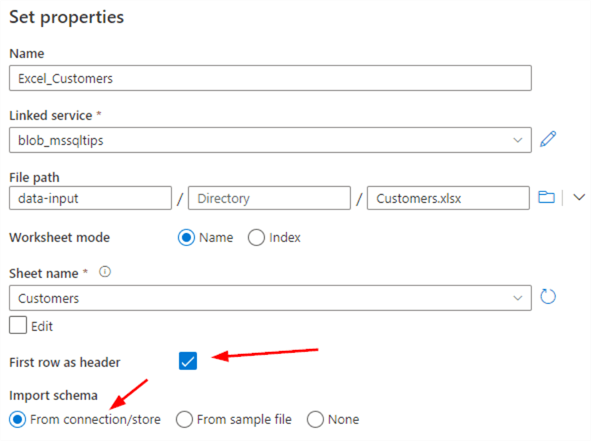
Click OK to create the dataset. In the Connection tab, we can see the properties we just configured, but now we can also preview the data.
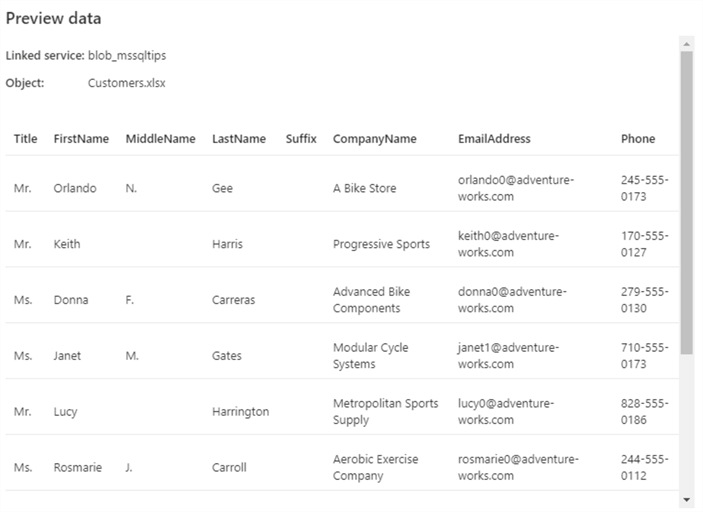
If all went well, the preview should look like this:
In the Schema tab, we can view the different columns of the Excel worksheet and their datatypes.
Click on Publish to persist the dataset to the ADF environment.
Dataset Best Practices
Like linked services, there are a couple of best practices that you can use:
- Use a naming convention. For example, prefix datasets that describe a table in SQL server with SQL_. For file types you can use for example CSV_, EXCEL_, AVRO_ and so on. This will make it easier for you to keep apart the different types of datasets.
- Like with linked services, if you have multiple environments use the same name for a dataset in all environments.
- You can create folders to organize your datasets. This is helpful if you have a large environment with dozens of datasets. You can organize them by source or by file type for example. You can also create subfolders.
Additional Information
- The tip Supporting multiple data lake file formats with Azure Data Factory talks about the different file formats supported in blob storage.
- A dataset of the format Web Table is used in the tip Azure Data Factory for Web Scraping.
- Not all linked services need a dataset. A good example is the Azure Function.
