By: Koen Verbeeck
Overview
We've defined linked services and datasets, so now we can work on pipelines. A pipeline is a container that will execute one or more activities.
The Purpose of Activities
An activity inside a pipeline corresponds with a single task. If we want to compare this with Integration Services (SSIS), an activity in ADF is like a task on the control flow. If you create a pipeline, you can find the list of activities in the left menu bar.
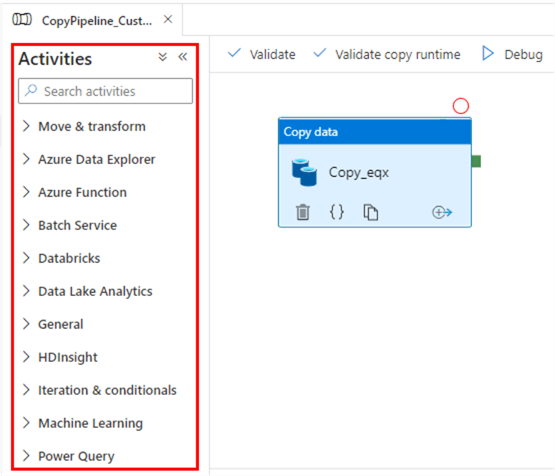
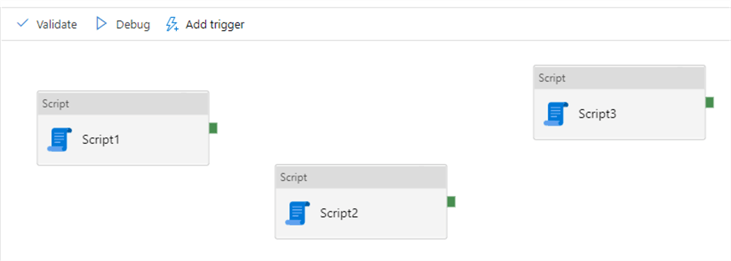
If you want to add an activity, you can drag it from the menu onto the canvas. If you have multiple activities on a pipeline, they will all be executed in parallel unless they are connected with a dependency. For example, in the following pipeline, all three pipelines will be executed at the same time:
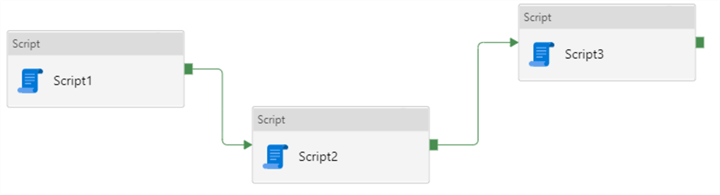
When you click on the little green box at the right an activity, you can draw an arrow from the activity to another activity. This is how we define dependencies. In the following pipeline, Script1 will be executed first. If it is successful, Script2 will be executed. If that one is successful as well, Script3 will be executed.
Dependencies are very similar to precedence constraints in SSIS, but not as flexible. In SSIS you can define expressions on a constraint so it can be evaluated conditionally. This is not possible in ADF. In the following example, Script3 depends on Script1 and Script2 with an AND constraint.
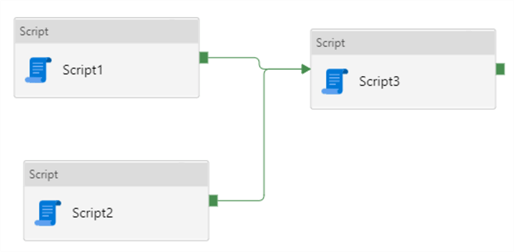
This means Script1 and Script2 will execute in parallel. Script3 will only be executed if both succeed. There's currently no possibility to define an OR constraint, meaning Script3 will execute if Script1 or Script2 succeeds. This is possible in SSIS.
When you right-click on a dependency, you can change its type.
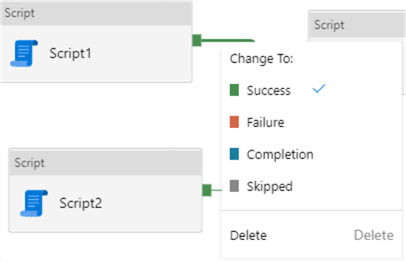
- Success is the default dependency. Another task will only start if the previous task completed successfully.
- Failure is the opposite. The task will only start if the previous task has failed. This is useful for error handling and monitoring.
- Completion means a task will start when the previous task has completed. It doesn't matter if that task was successful or not.
- Skipped is probably not used that much. A task will execute if the previous task has been skipped. For example, in the following pipeline, Script3 will only execute if Script2 is skipped (meaning never executed). This can happen when Script1 fails.

Which Types of Activities are there?
There are three types of activities:
- Data movement activities. This is basically only the Copy Activity. This activity was used by the Copy Data tool in the earlier parts of the tutorial.
- Data transformation activities. Most of these are external activities, meaning the actual computation doesn't happen at ADF itself but rather at another data store. A bit of an exception are data flows, which we will cover later in the tutorial. Examples of transformation activities are the stored procedure (executed on the database), Script (also executed on the database, which is a fairly new addition to ADF), Azure Function, Hive/Pig/MapReduce/Spark (all on HDInsight) and Databricks Notebook/JAR/Python (these are executed on an Azure Databricks Cluster).
- Control Flow
activities. These activities are almost all native to ADF, meaning
the computation is done in ADF itself. You have activities for different purposes:
- to deal with variables (Append Variable, Set Variable and Filter)
- looping (ForEach and Until)
- branching (the If Condition activity)
- executing other pipelines with Execute Pipeline activity, or SSIS packages with Execute SSIS Package activity.
- Handling metadata or reference data with the Get Metadata activity or the Lookup activity.
- You can do web calls with the Web and Webhook activities.
- You can validate other pipelines with the Validation activity. The Wait activity is used when you need to wait for a specific amount of time.
With all these different activities, you can build intricate data pipelines that will support many different use cases.
Activity Best Practices
- Give an activity a proper name, so if someone else opens your pipeline, they can easily understand what the purpose of each activity is.
- Have a modular design. A pipeline should have only one purpose. For example, load data from a data lake to SQL Server. If you for example need to do other steps, such as loading dimension and fact tables, these should be done in another pipeline.
- You can have only maximum 40 activities in a pipeline. If you need more, you'll need to create child pipelines and call them using the Execute Pipeline activity. If you have too many activities, maybe you violated the previous best practice.
- Try to minimize the number of activities needed. For every started activity, ADF incurs the cost of at least one minute and they round up. For example, if an activity runs for 65 seconds, you will pay for two full minutes. If a pipeline has 5 activities, you will pay for at least 5 full minutes, even if the total execution time of the pipeline is way below 5 minutes.
- Ideally pipelines are idempotent, meaning that if you execute one repeatedly, the result should be the same. If a pipeline fails, you should be able to restart it without doing manual cleanup. If there's any cleanup needed, it should be taken care off by the pipeline itself.
Additional Information
- You can find an overview of the control flow activities in the tip Azure Data Factory Control Flow Activities Overview.
- The tip Build Azure Data Factory Pipeline Dependencies gives another example of how to use dependencies in a pipeline.
- You can find a good overview of all the activities in the official documentation.
