By: Koen Verbeeck
Overview
During the tutorial we've mentioned data flows a couple of times. The activities in a pipeline don't really support data transformation scenarios. The Copy Data activity can transform data from one format to another (for example, from a hierarchical JSON file to a table in a database), but that's about it. Typically, you load data from one or more sources into a destination and you do the transformations over there. E.g., you can use SQL in a database, or notebooks in Azure Databricks when the data is stored in a data lake. This makes ADF a great ELT tool (Extract -> Load -> Transform), but not so great for ETL. Data flows were introduced to remedy this. They are an abstraction layer on top of Azure Databricks. They intuitively provide you with an option to create ETL flows in ADF, without having to write any code (like you would need to do if you worked directly in Azure Databricks). There are two types of data flows:
- The data flow (which was previously called the "mapping data flow".
- Power Query (which was previously called the "wrangling data flow"
Data Flow
A data flow in ADF uses the Azure-IR integration runtime to spin up a cluster of compute behind the scenes (see the previous part about runtimes on how to configure your own). This cluster needs to be running if you want to debug or run your data flow.
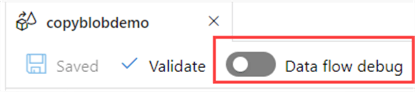
Data flows in ADF use a visual representation of the different sources, transformations, and sinks; all connected with precedence constraints. They resemble data flows in Integration Services. Here's an example from the tip What are Data Flows in Azure Data Factory?. This tip gives a step-by-step example of how to create a data flow and how to integrate it into a pipeline.
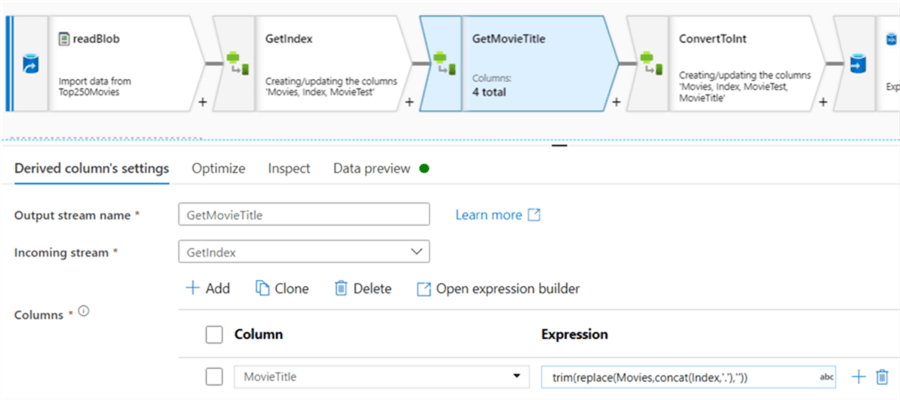
Because you need a cluster to run a pipeline, data flows are not well-suited for processing small data sets, since there's the overhead of the cluster start-up time.
Power Query
The Power Query data flow is an implementation of the Power Query engine in ADF. When you run a Power Query in ADF, the Power Query mash-up will be translated into a data flow script, which will then be run on the Azure Databricks cluster. The advantage of Power Query is that you can see the data and the results of your transformations as you're applying them. Users who have been working with Excel, Power BI Desktop or Power BI Data Flows are also already familiar with the editor.
You can find an example of a Power Query mash-up in the tip What are Data Flows in Azure Data Factory? as well.
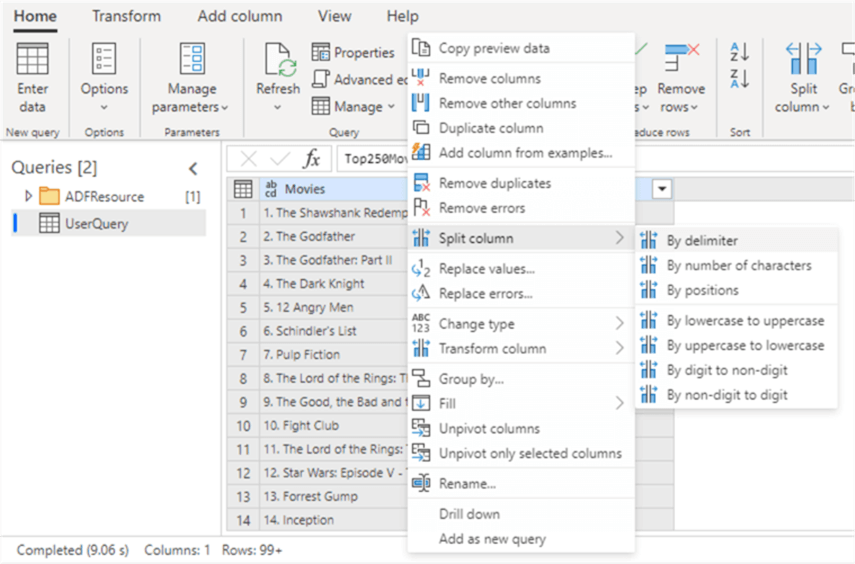
The disadvantage of Power Query is that not all functionality of the regular Power Query (as you would have in Power BI Desktop for example) is available in ADF. You can find a list of the limitations in the documentation.
Additional Information
- You can find more info on data flows in the following tips:
- The tip What is Power Query? explains what Power Query is and in which products you can find it.
- If you want another example of Power Query in ADF, check out the tip Leveraging the Power Query activity within Azure Data Factory.
