By: Koen Verbeeck
Overview
In this tutorial we have been executing pipelines to get data from a certain source and write it to another destination. The Copy Data activity for example provides us with a auto-scalable source of compute that will execute this data transfer for us. But what is this compute exactly? Where does it reside? The answer is: integration runtimes. These runtimes provide us with the necessary computing power to execute all the different kind of activities in a pipeline. There are 3 types of integration runtimes (IR), which we'll discuss in the following sections.
The Azure-IR
The most important integration runtime is the one we've been using all this time: the Azure-IR. Every installation of ADF has a default IR: the AutoResolveIntegrationRuntime. You can find it when you go to the Manage section of ADF and then click on Integration Runtimes.
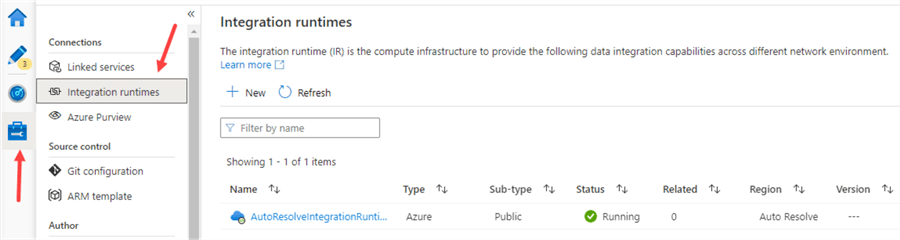
It's called auto resolve, because it will try to automatically resolve the geographic region the compute will need to run. This is determined for example by the data store of the sink in a Copy Data activity. If the sink is located in West Europe, it will try to run the compute in the West Europe region as well.
The Azure-IR is a fully managed, serverless compute service. You don't have to do anything to manage, except pay for the duration it has been running compute. You can always use the default Azure-IR, but you can also create a new one. Click on New to create one.
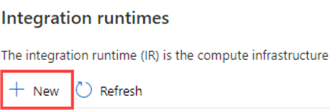
In the new window, choose the option with "Azure, Self-Hosted".
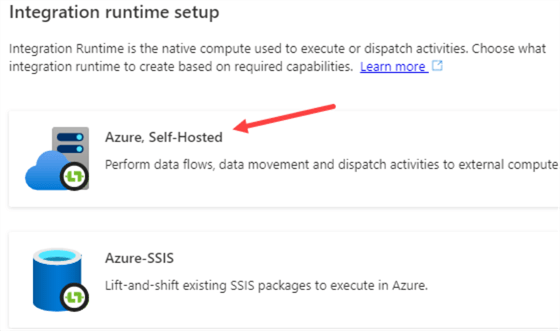
In the next step, choose Azure again.
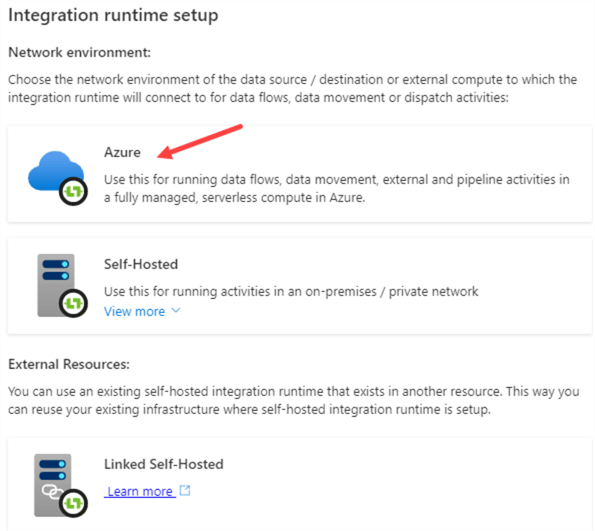
In the following screen, enter a name for the new IR. Also choose your closest region.
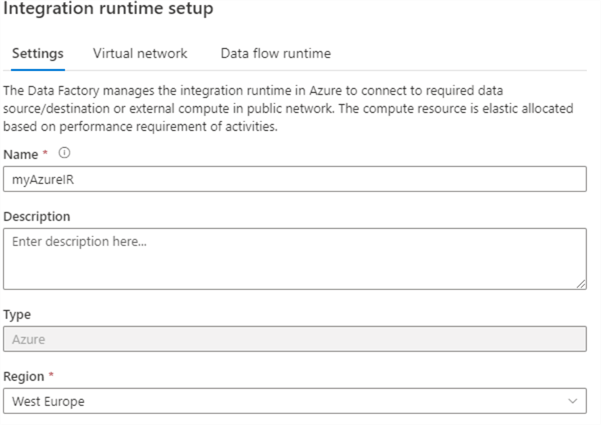
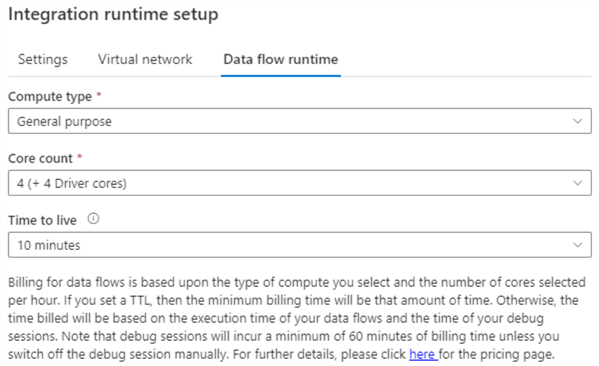
You can also configure the IR to use a Virtual Network, but this is an advanced setting that is not covered in the tutorial. Keep in mind that billing for pipeline durations is several magnitudes higher when you're using a virtual network. In the third pane, we can configure the compute power for data flows. Data flows are discussed in the next section of the tutorial.
There are two main reasons to create your own Azure-IR:
- You want to specify a specific region for your compute. For example, if regulations specify your data can never leave a certain reason, you need to create your own Azure-IR located in that region.
- You want to specify a data flow runtime with different settings than the default one. Especially the Time To Live setting is something that is worth changing (shorter if you want to save on costs, longer if you don't want to restart you cluster too often during development/debugging).
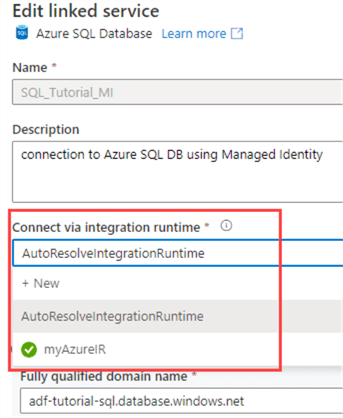
Click on Create to finish the setup of the new Azure-IR. But how do we use this IR? If we go for example to the linked service connecting to our Azure SQL database, we can specify a different IR:
The Self-hosted IR
Suppose you have data on-premises that you need to access from ADF. How can ADF reach this data store when it is in the Azure cloud? The self-hosted IR provides us with a solution. You install the self-hosted IR on one of your local machines. This IR will then act as a gateway through which ADF can reach the on-premises data.
Another use case for the self-hosted IR is when you want to run compute on your own machines instead of in the Azure cloud. This might be an option if you want to save costs (the billing for pipeline durations is lower on the self-hosted IR than one the Azure-IR) or if you want to control everything yourself. ADF will then act as an orchestrator, while all of the compute is running on your own local servers.
It's possible to install multiple self-hosted IRs on your local network to scale out resources. You can also share a self-hosted IR between multiple ADF environments. This can be useful if you want only one self-hosted IR for both development and production.
The following tips give more detail about this type of IR:
- Connect to On-premises Data in Azure Data Factory with the Self-hosted Integration Runtime - Part 1 and Part 2.
- Transfer Data to the Cloud Using Azure Data Factory
- Build Azure Data Factory Pipelines with On-Premises Data Sources
The Azure-SSIS IR
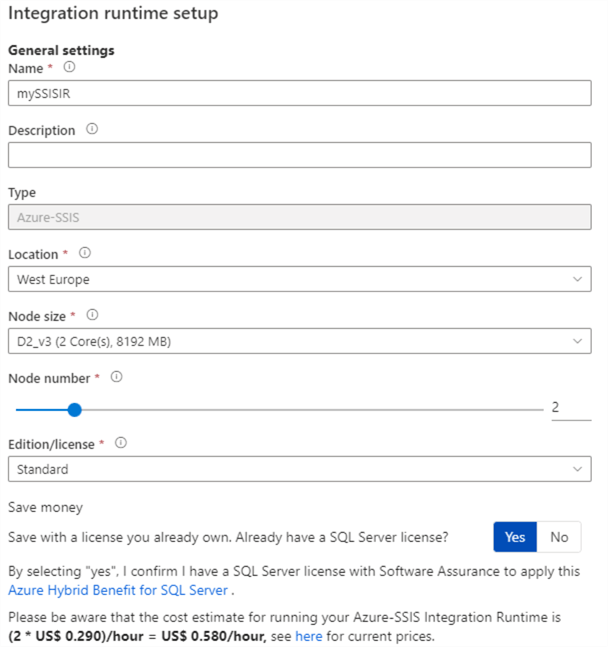
ADF provides us with the opportunity to run Integration Services packages inside the ADF environment. This can be useful if you want to quickly migrate SSIS project to the Azure cloud, without a complete rewrite of your projects. The Azure-SSIS IR provides us with a scale-out cluster of virtual machines that can run SSIS packages. You create an SSIS catalog in either Azure SQL database or in Azure SQL Server Managed Instance.
As usual, Azure deals with the infrastructure. You only need to specify how powerful the Azure-SSIS IR is by configuring the size of a compute node and how many nodes there need to be. You are billed for the duration the IR is running. You can pause the IR to save on costs.
The following tips give you more information on the Azure-SSIS IR:
- Configure an Azure SQL Server Integration Services Integration Runtime
- Customized Setup for the Azure-SSIS Integration Runtime
- Execute SSIS Package in Azure-SSIS Integration Runtime
- Parallel package execution in Azure-SSIS Runtime
- SSIS Catalog Maintenance in the Azure Cloud
Additional Information
- The tip Migrate a Package Deployment Integration Services Project to Azure details how you can migrate an SSIS project using the package deployment model to ADF.
- You can find a comparison between ADF and SSIS in the tip Choosing Between SQL Server Integration Services and Azure Data Factory.
- There's an on-demand webinar you can watch about lifting and shifting your SSIS projects to ADF: Migrating SQL Server Integration Services to the Cloud.
