Problem
Under heavy contention your transactions could be the victim of a deadlock and therefore be rolled back. In this tip I will show you how to implement retry logic to re-run the failed transaction.
Solution
We all know that every RDBMS system has to guarantee the ACID principle (Atomicity, Consistency, Isolation and Durability). A transaction must be either committed or rolled back entirely (Atomicity). SQL Server cannot commit half a transaction because doing so will violate the second principle (Consistency). To keep consistency, concurrent transactions must be independent of each other (Isolation) and changes must persist (Durability).
Although this makes database systems reliable in most circumstances, following these properties is difficult and drastic measures are sometimes taken by SQL Server or any other RDBMS. That’s where deadlocks come to light.
A deadlock happens when two or more tasks block each other because each task has a lock on a resource that the other task(s) are trying to lock. Although you can set deadlock priority for each transaction by using SET DEADLOCK_PRIORITY option, one of them will be killed and you will get this error 1205: “Transaction (Process ID %d) was deadlocked on %.*ls resources with another process and has been chosen as the deadlock victim. Rerun the transaction.”
But transaction retry logic isn’t limited to correcting deadlocks; there are several other circumstances in which you may want to retry a failed transaction like server timeouts, errors due to concurrent schema modification operations and so on.
SQL Server 2014’s Memory-Optimized Tables and Transaction Retry
In SQL Server 2014, the In-Memory OLTP Engine (Hekaton) uses a lock free and latch free optimistic concurrency control and deadlocks cannot occur. But transactions in Hekaton have a validation phase that can set a transaction into a doomed state because of commit dependency failures or isolation level conflicts.
Here is a table with the error numbers you can face by using Memory-Optimized tables.
Error Number | Description |
|---|---|
41302 | The current transaction attempted to update a record that has been updated since the transaction started. |
41305 | The current transaction failed to commit due to a repeatable read validation failure. |
41325 | The current transaction failed to commit due to a serializable validation failure. |
41301 | A previous transaction that the current transaction took a dependency on has aborted, and the current transaction can no longer commit |
SQL Server Transaction Retry Logic
The approach is really simple and requires little code modification. Basically it consists of enclosing the transaction into a TRY …CATCH block. The TRY …CATCH block was made available with versions 2005 and above, so if you are still using SQL Server 2000 this is a good reason to migrate.
Without getting into much detail, a TRY …CATCH block consists of two sections: one contains the actions you want to perform (the TRY section), and the other is what to do if something goes wrong with those actions (the CATCH section). The power of TRY …CATCH blocks relies on allowing us to trap errors without aborting the batch.
At this point we have half of the problem solved: we are able to handle the exception without aborting the batch and the other half is to find a way to re-execute the batch.
In programming when we talk about repeating an action, we talk about loops. And this is the way: we set a maximum retries count, say three and then repeat our transaction either until it commits or until the maximum retry count is reached. To do so, we have two possibilities: WHILE loops or GOTO unconditional jumps.
The following image is a graphical representation of previous statements, so you can see that retry logic can be easily implemented without too much code.
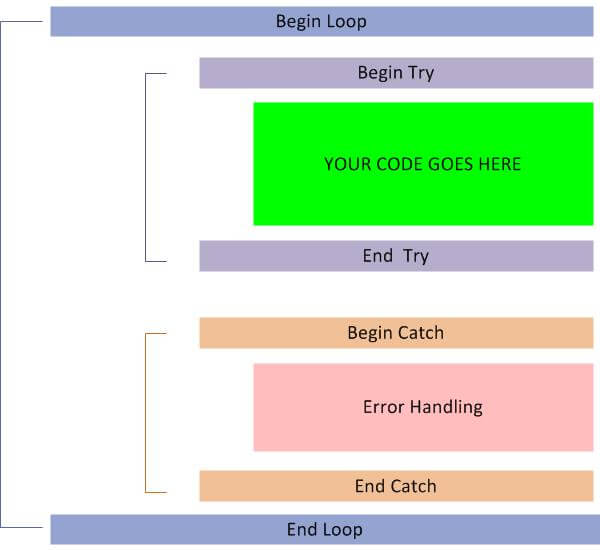
For those of you who are more into structured programming the next image represents a flow chart of our transaction retry algorithm.

Sample SQL Server Transaction Retry Code
Now it’s time to do our coding. I will guide you through all the steps.
1 – First we create our sample database
USE [master]
GO
CREATE DATABASE TestDB
ON PRIMARY
( NAME = N’TestDB’, FILENAME = N’E:\MSSQL\TestDB.mdf’ , SIZE = 10240KB , MAXSIZE = UNLIMITED,
FILEGROWTH = 1024KB )
LOG ON
( NAME = N’TestDB_log’, FILENAME = N’E:\MSSQL\TestDB_log.ldf’ , SIZE = 1024KB , MAXSIZE = UNLIMITED ,
FILEGROWTH = 1024KB)
GO
2 – This will be our test table
USE TestDB
GO
IF OBJECT_ID(‘dbo.Customers’,’U’) IS NOT NULL
DROP TABLE dbo.Customers
GO
CREATE TABLE dbo.Customers(
CustomerId INT NOT NULL IDENTITY(1,1),
CustomerCode NVARCHAR(10) NOT NULL,
CustomerName NVARCHAR(50) NOT NULL,
CustomerAddress NVARCHAR(50) NOT NULL,
LastModified DATETIME NOT NULL DEFAULT GETDATE()
PRIMARY KEY CLUSTERED (CustomerId)
)
GO
3 – Simulating our deadlock
I am making it very simple: a single transaction consisting of an INSERT to Customers table followed by a delay of ten seconds and then a SELECT to the same table.
You must paste this code in two separate windows and run it simultaneously.
USE TestDB
GO
BEGIN TRANSACTION
INSERT INTO dbo.Customers ( CustomerCode ,
CustomerName ,
CustomerAddress
)
VALUES ( N’A15C6E’ ,
N’John Doe’ ,
N’Evergreen 1234′
)
WAITFOR DELAY ’00:00:10′
SELECT * FROM dbo.Customers
COMMIT TRANSACTION
Here is a screen capture with the execution of the previous code from two different query windows (session 56 and session 58).


As you can see only one window successfully committed and the other one failed to commit due to Error 1205 which is Transaction was deadlocked and has been chosen as the deadlock victim.
4 – To keep our testing clean let’s truncate our sample table
USE TestDB
GO
TRUNCATE TABLE dbo.Customers
5 – Sample Retry Logic Implementation
At first this code may be scary by its length, but keep in mind that I added more steps than needed in order to explain how it works.
As before, you must paste this code in two separate windows and run it simultaneously.
USE TestDB
GO
DECLARE @RetryCount INT
DECLARE @Success BIT
SELECT @RetryCount = 1, @Success = 0
WHILE @RetryCount < = 3 AND @Success = 0
BEGIN
BEGIN TRY
BEGIN TRANSACTION
— This line is to show you on which execution
— we successfully commit.
SELECT CAST (@RetryCount AS VARCHAR(5)) + ‘st. Attempt’INSERT INTO dbo.Customers
( CustomerCode ,
CustomerName ,
CustomerAddress
)
VALUES ( N’A15C6E’ ,
N’John Doe’ ,
N’Evergreen 1234′
)— This Delay is set in order to simulate failure
— DO NOT USE IN REAL CODE!
WAITFOR DELAY ’00:00:05′SELECT * FROM dbo.Customers
COMMIT TRANSACTION
SELECT ‘Success!’
SELECT @Success = 1 — To exit the loop
END TRYBEGIN CATCH
ROLLBACK TRANSACTIONSELECT ERROR_NUMBER() AS [Error Number],
ERROR_MESSAGE() AS [ErrorMessage];— Now we check the error number to
— only use retry logic on the errors we
— are able to handle.
—
— You can set different handlers for different
— errors
IF ERROR_NUMBER() IN ( 1204, — SqlOutOfLocks
1205, — SqlDeadlockVictim
1222 — SqlLockRequestTimeout
)
BEGIN
SET @RetryCount = @RetryCount + 1
— This delay is to give the blocking
— transaction time to finish.
— So you need to tune according to your
— environment
WAITFOR DELAY ’00:00:02′
END
ELSE
BEGIN
— If we don’t have a handler for current error
— then we throw an exception and abort the loop
THROW;
END
END CATCH
END
The next two images speak for themselves. We have successfully committed both transactions without errors or warnings.


Next Steps
- Here is an introduction to SQL Server 2005 Try and Catch Exception Handling.
- For more information on THROW statement take a look at SQL Server 2012 Throw Statement Introduction.
- Also check out Error Handling Tips Category.
- In this tip you will learn how to use delays in your code for testing: Create delays in SQL Server processes to mimic user input.

Daniel Farina was born in Buenos Aires, Argentina. Self-educated, since childhood he showed a passion for learning. He studied at Universidad de Buenos Aires. Daniel started working as a programmer at a young age. Over the years he specialized in databases, particularly SQL Server and Oracle. Now with 30 years of age, his work experience includes working with various technologies like VB, C, .NET, web development, Windows and Linux systems. He likes to read about science, psychology, philosophy and many other things. In his spare time, he trains powerlifting aiming to compete.
- MSSQLTips Awards: Author of the Year – 2018 | Champion (100+ tips) – 2018 | Author Contender – 2015-2017, 2019


