Problem
I read about the GOOGLEFINANCE function with Google Sheets as a convenient way to get historical and current data for stocks. Please demonstrate a solution for passing data for a bunch of stocks from the Google Finance site to a SQL Server database using the GOOGLEFINANCE function in Google Sheets.
Solution
The GOOGLEFINANCE function inside of Google Sheets downloads historical and current data on stocks and other securities from the Google Finance site. However, the downloaded data end up in a web-based spreadsheet tool instead of residing within a database like SQL Server. This tip demonstrates a simple solution for using the GOOGLEFINANCE function in combination with T-SQL code for transferring historical data from Google Finance to a SQL Server database for data mining of stock prices and stock trading rules.
The GOOGLEFINANCE function inside of Google Sheets is attractive because it can download historical data for multiple stock tickers within a single spreadsheet. Get an introduction to this function here. After specifying a Google Sheet for a bunch of stock symbols, you can share that sheet with others. In contrast, both Google Finance and Yahoo Finance sites offer an URL with query string parameters API for specifying what stocks and time period to download data. However, the URL with query string parameters approach allows the downloading of data for just one ticker symbol at a time. Additionally, the downloaded data with the URL with query strings parameters approach does not facilitate data sharing with the same ease as Google Sheets.
This tip presents a solution for downloading historical data for 60 ticker symbols for data going back as far as January 2006 and then imports the data to SQL Server. It is very straightforward to change the ticker symbols as well as the date range for which data is downloaded. The presentation starts with an overview of the solution strategy. Later, selected features of the solution are examined to empower you to expand and modify the solution as your needs dictate. The presentation of the solution’s technology also includes an examination of selected data quality issues for historical stock prices from the Google Finance site.
An overview of the solution strategy
Ignoring installation and setup issues for Google software, there are two main parts of the solution.
- The first part handles the download of historical stock data from the Google Finance site to your computer – one file per ticker symbol
- The second part imports the downloaded files to a SQL Server table
Since the problem addressed by this tip is to download data from the Google Finance site with the GOOGLEFINANCE function within Google Sheets, you need access to Google Sheets. Furthermore, Google Drive is currently the only means of managing sheets created with Google Sheets and files derived from those sheets. The functionality provided by Google Sheets and Google Drive also requires the Google Chrome browser and a Google account to the overall Google site. Access to all of this software is available free from Google, and you can install Google Chrome as a non-default browser so that you can continue to use Internet Explorer as your default browser (if that is what you prefer).
For your convenience, the links for getting to use Google Chrome, Google Sheets, and Google Drive appear below. As you setup access to Google Sheets and Google Drive, you will receive prompts about setting up a Google account if you do not already have one.
- Google Chrome: https://www.google.com/chrome/browser/desktop/index.html
- Google Sheets: https://www.google.com/sheets/about/
- Google Drive: https://www.google.com/drive/
A demonstration on downloading the data from Google Chrome
Once you have your computer configured with the application environment referenced by the solution, you can open three Google Sheets files that download the data for this solution demonstration. The sheet names (stocks_for_mining_A2_A25, stocks_for_mining_A26_A49, and stocks_for_mining_A50_A61) and their URL links appear below.
link to share for: stocks_for_mining_A2_A25 https://docs.google.com/spreadsheets/d/1PbDZ6GGrupaCvrYXNyWlL4wuH3aCJuRaiC62wiSbpYY/edit?usp=sharing link to share for: stocks_for_mining_A26_A49 https://docs.google.com/spreadsheets/d/1xvIjjBRHbskNpdELK58Xw3O0-gQZ69hL8cmkuC2-t-s/edit?usp=sharing link to share for: stocks_for_mining_A50_A61 https://docs.google.com/spreadsheets/d/1A6M0557VhNegFh0UZuUTT8LSp2hp-_8FOaLBt-xBS70/edit?usp=sharing
Each sheet has two tabs with control information about the range of ticker symbols and dates for which to download data. The remaining tabs within each sheet contain the historical stock price data. The stocks_for_mining_A2_A25 sheet has data for ticker symbols in cells A2 through A25 within its ticker_list tab. The following screen shot shows the sheet with the ticker_list tab selected and the cells A2 through A25 highlighted.
The tab named start_and_end_dates has values of 1/1/2006 for a start date and 9/24/2006 for an end date. Historical stock price data are end-of-day data. You should add one day to the last day through which you seek to download data. Therefore, if you want end-of-day data through September 23, 2016, you should specify September 24, 2016 as your end date.
You can modify the ticker symbols on the ticker_list tab as well as the dates on the start_and_end_dates tab to change the range of dates and symbols for which historical data is downloaded in the stocks_for_mining_A2_A25 sheet. Furthermore, the other two sheets (stocks_for_mining_A26_A49 and stocks_for_mining_A50_A61) download historical data for ticker symbols in cells A26 through A49 and cells A50 through A61 of the ticker_list tab. There are 60 cells from A2 through A61, and downloaded data is for these symbols across the three sheets.
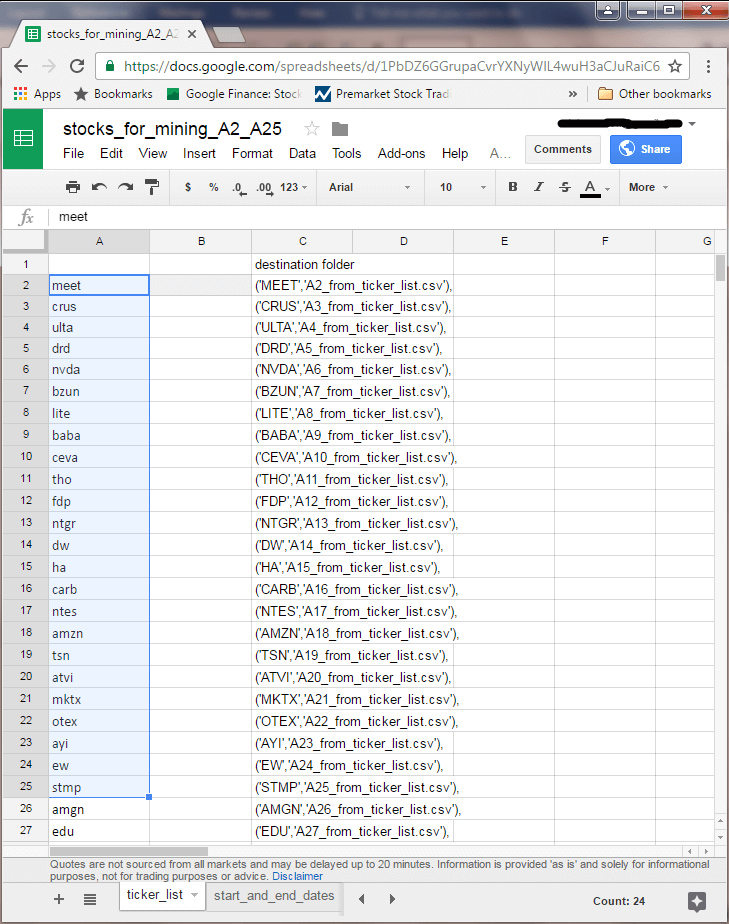
The next screen shot shows the A2_from_ticker_list tab within the stocks_for_mining_A2_A25 sheet. There are 23 additional tabs within the sheet with names like A3_from_ticker_list through A25_from_ticker_list. Notice that cell A1 is selected within the A2_from_ticker_list tab. Within the function bar (fx), you can see an instance of the GOOGLEFINANCE function syntax for recovering historical data. For the current solution, the function populates cells in columns A through F.
- The function’s first argument indicates the cell with the ticker symbol for the historical data; the cell is A2 from the ticker_list tab, which has a value of the meet stock symbol
- The all parameter in quotes for the second argument indicates that all historical data fields should be downloaded; these fields are date followed by open, high, low, and close prices as well as volume of shares traded on a date
- The start date for historical data is the first trading date on or after the start date, which is the function’s third argument; the start date is in cell B2 of the start_and_end_dates tab
- The historical data run through one day before the date specified by the fourth argument (cell B3 of the star_and_end_dates tab)
- The last argument indicates historical data is requested on a daily basis; one other legitimate value for this argument can specify the return of historical data on a weekly basis
The meet symbol is for a company named MeetMe.com, which had its initial trading date on January 21, 2011. This is also the first date in Column A. The last date in column A is one day before the end date value (September 24, 2016) in cell B3 within the start_and_end_dates tab.
The data in cell G2 is not returned by the GOOGLEFINANCE function. This cell shows the symbol value for the historical data appearing in columns A through F. The expression in cell G2 within the tab below is: =ticker_list!A$2. The T-SQL code for importing the downloaded data into SQL Server uses the value in cell G2 for associating a ticker symbol value with the historical data in a tab.
After the GOOGLEFINANCE function populates rows in a tab, select column A within the tab. Then, choose the Format, Number, Date menu item. This represents the values within column A in mm/dd/yyyy format. When the data are imported within SQL Server, this format selection from within Google Sheets simplifies the processing of the downloaded data.

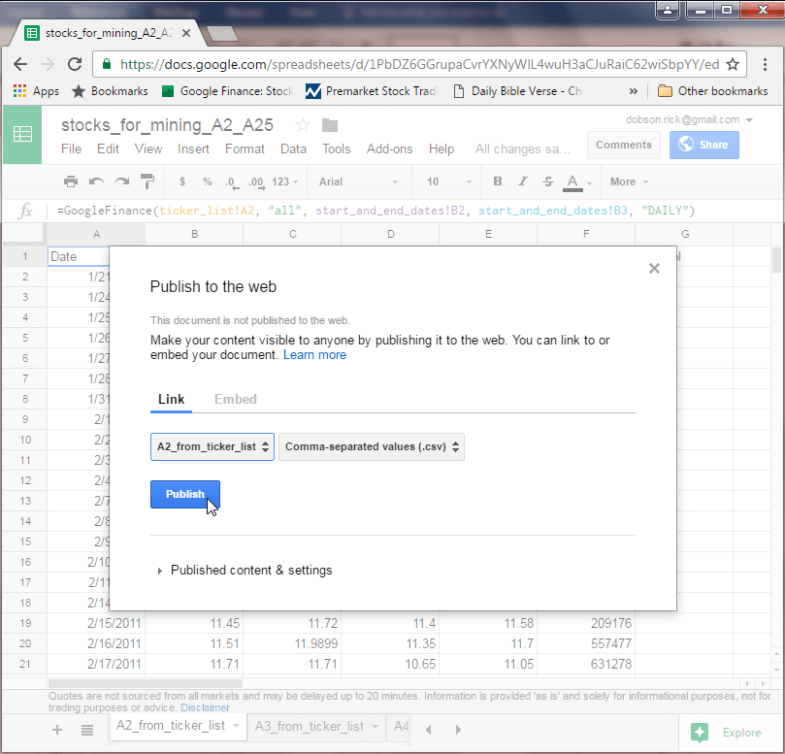
You can export the data from any tab within the stocks_for_mining_A2_A25 sheet as a csv file with the File, Publish to the web menu item. This menu selection publishes the content of a designated tab in a sheet to Google Drive. From Google Drive, you can share the published file and/or download it to your computer. The solution described by this tip uses the latter option so that the data can ultimately be imported into SQL Server.
The following screen shot shows the dialog settings for publishing to Google Drive the contents of the A2_from_ticker_list tab as a csv file. Notice that you can use selection boxes for designating both the tab name and format of the published file. Clicking the Publish button launches the process. You can use the File, Publish to the web menu command to publish successively the contents of each of the tabs in a sheet.
Because of the structure of the sheets in this tip, the csv files are not exactly like many csv files. In particular, there is a jagged right edge to the file because the ticker symbol value appears only on the initial row. Custom T-SQL code for importing the csv files downloaded from Google Drive into SQL Server can assign a ticker symbol value for each row in a ticker’s data set so that the right edge is no longer jagged within a SQL Server table.
The next screen shot displays the identifier for the A2_from_ticker_list.csv file selected in Google Drive. Right-clicking the file identifier opens a context sensitive menu for copying the file to your downloads directory on the computer you are using. By successively downloading files, you can download csv files with the contents of all the tabs in stocks_for_mining_A2_A25, stocks_for_mining_A26_A49, and stocks_for_mining_A50_A61 sheets.

You might be wondering why there are not 60 tabs for 60 ticker symbols in a single sheet. The answer is that there is an upper limit on the number of cells within a single Google sheet. For the data in this tip, this limit is reached when trying to load the 25th tab of historical stock data within a sheet. Therefore, the first two sheets (stocks_for_mining_A2_A25 and stocks_for_mining_A26_A49) each have 24 tabs with historical stock data, and the third sheet (stocks_for_mining_A50_A61) has an additional 12 tabs containing historical prices and volumes for the remaining 12 ticker symbols in a set of 60 ticker symbols.
An overview of the importing part of the solution via a T-SQL script
A T-SQL script file (import_downloaded_data_into_SQL_Server.sql) uses 4 main tables and a WHILE loop to convert the downloaded csv files for each stock ticker symbol for insertion into a single table in a SQL Server database.
- The imported_stock_prices_lines table stores the csv files as downloaded by Google Drive — namely, no parsing of the values between commas
- The imported_stock_prices table stores data rows for stocks after custom parsing for the jagged right csv files; some follow-up code to the parsing assigns a ticker symbol to each row as well, instead of just the first row as in the source Google sheet tabs, but the column values all have a varchar data type
- The stocks_symbol_ohlcv table accepts the string data from the imported_stock_prices table and implicitly assigns data types that reflect the type of data for a column, such as date, money, or bigint
- The WHILE_LOOP_FIELDS table in coordination with a WHILE loop facilitates successively processing the csv files downloaded by Google Drive for each ticker symbol; each row in the WHILE_LOOP_FIELDS table is for a unique ticker symbol
The WHILE loop sequentially passes through the rows of the WHILE_LOOP_FIELDS table and successively populates the imported_stock_prices_lines and imported_stock_prices tables. After the data are processed and ready for data typing, they are inserted into the stocks_symbol_ohlcv table. After passing through all the rows in the WHILE_LOOP_FIELDS table, the stocks_symbol_ohlcv table has data rows for all ticker symbols downloaded by Google Drive.
Walk through code for importing csv files into SQL Server
The code within import_downloaded_data_into_SQL_Server.sql script file has two main segments.
- The first segment occurs before the WHILE loop for successively processing data for each successive ticker symbol; the primary role of this initial segment is to create tables and declare variables used in the next code segment
- The second segment performs the processing for each ticker symbol up to and including populating the stocks_symbol_ohlcv table so that after the last WHILE loop concludes the table contains data rows for all ticker symbols with values that correspond to the tabs in the three source Google sheets
The beginning of the first segment creates the imported_stock_prices_lines, imported_stock_prices and stocks_symbol_ohlcv tables. The code for creating these tables appear below. Before invoking the code to create the tables, there is a USE statement for the stocks_for_mining database. You need a database to hold the solution’s tables; this presentation uses the stocks_for_mining database to fulfill that role. After populating the stocks_symbol_ohlcv table for all ticker symbols of interest, you can start data mining stock prices and/or stock trading strategies.
- The imported_stock_prices_lines table has one row for each line in the original source data for a single stock ticker symbol; all the data for each row is in a single column named line
- The imported_stock_prices table has seven columns
- Six columns are for historical data fields ( date, open, high, low, close, and volume)
- The seventh column is for ticker symbol; recall that the GOOGLEFINANCE function does not return data with a column for the ticker symbol
- All columns have a varchar data type for up to 50 characters; the data within tabs of Google sheets were formatted to conform with these constraints
- The stocks_symbol_ohlcv table also has seven columns; its design is different from the imported_stock_prices table in two respects
- Most critically, the historical data columns have data types that conform to the type of data in them, such as money for open, high, low, and close prices
- Also, the SYMBOL column is first instead of last
USE stocks_for_mining GO -- Populate stocks_symbol_ohlcv table -- with imported ohlcv data for each stock symbol -- from csv files -- execute once before WHILE LOOP for -- each row in table of stock symbols and file paths/names -- new table for receiving data from each csv stock file -- receives data as unseparated line to be parsed later IF EXISTS ( SELECT * from INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME = 'imported_stock_prices_lines' AND TABLE_SCHEMA = 'dbo' ) DROP TABLE imported_stock_prices_lines CREATE TABLE imported_stock_prices_lines( line varchar(1000) ) ON [PRIMARY] -- table for receiving data from each csv stock file after parsing IF EXISTS ( SELECT * from INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME = 'imported_stock_prices' AND TABLE_SCHEMA = 'dbo' ) DROP TABLE imported_stock_prices CREATE TABLE imported_stock_prices( [date] varchar(50) NULL, [open] varchar(50) NULL, [high] varchar(50) NULL, [low] varchar(50) NULL, [close] varchar(50) NULL, [volume] varchar(50) NULL, [SYMBOL] [varchar](50) NOT NULL ) ON [PRIMARY] -- table with consolidated ohlcv data -- for all stocks being tracked IF EXISTS ( SELECT * from INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME = 'stocks_symbol_ohlcv' AND TABLE_SCHEMA = 'dbo' ) DROP TABLE stocks_symbol_ohlcv CREATE TABLE [dbo].stocks_symbol_ohlcv( [SYMBOL] [varchar](4) NOT NULL, [date] varchar(100) NULL, --[date] NULL, [open] [money] NULL, [high] [money] NULL, [low] [money] NULL, [close] [money] NULL, [volume] [bigint] NULL ) ON [PRIMARY]
The next block of code within the first segment creates and populates the WHILE_LOOP_FIELDS table. There are three parts to this code block.
- Initially, a CREATE TABLE statement instantiates the WHILE_LOOP_FIELDS table
- Next, the SYMBOL and path_file_name values are populated with an INSERT statement
- Values for populating the SYMBOL column come from the column A of the ticker_list tab for three Google sheets that derive the initial source data with a GOOGLEFINANCE function)
- Values for the path_file_name come initially from column C of the ticker_list tab; the values in this column are the result of a sheet expression; the expression draws on the ticker symbol row number in column A, an optional file path value, and ends with a constant designating a csv file
- The values from column C in the ticker_list are copied from any of the three source sheets to the SQL code below as is; the comma in the last row is removed after copying is completed
- The solution expects ticker_list tab to be the same in all sheets
- Finally, an UPDATE statement revises values in the path_file_name to reflect the source sheet from which the data for a symbol originates
- All the downloaded csv files were manually copied from the downloads folder to C:\stocks_for_mining
- Just as the solution needs a database for storing tables, it also needs a folder for storing csv files
- The original file names pointing at tabs are updated to reflect their source sheet. For example, within the sample solution, the data for the first 24 ticker symbols are from the stocks_for_mining_A2_A25 sheet
-- table with stock symbols and csv
-- file paths and names being tracked
IF EXISTS
(
SELECT * from INFORMATION_SCHEMA.TABLES
WHERE TABLE_NAME = 'WHILE_LOOP_FIELDS' AND TABLE_SCHEMA = 'dbo'
)
DROP TABLE WHILE_LOOP_FIELDS
CREATE TABLE [dbo].WHILE_LOOP_FIELDS(
SYMBOL_ID int IDENTITY(1,1) PRIMARY KEY,
SYMBOL [varchar](4) NOT NULL,
path_file_name [varchar](100) NOT NULL
) ON [PRIMARY]
INSERT INTO [WHILE_LOOP_FIELDS]
VALUES
('MEET','A2_from_ticker_list.csv'),
('CRUS','A3_from_ticker_list.csv'),
('ULTA','A4_from_ticker_list.csv'),
('DRD','A5_from_ticker_list.csv'),
('NVDA','A6_from_ticker_list.csv'),
('BZUN','A7_from_ticker_list.csv'),
('LITE','A8_from_ticker_list.csv'),
('BABA','A9_from_ticker_list.csv'),
('CEVA','A10_from_ticker_list.csv'),
('THO','A11_from_ticker_list.csv'),
('FDP','A12_from_ticker_list.csv'),
('NTGR','A13_from_ticker_list.csv'),
('DW','A14_from_ticker_list.csv'),
('HA','A15_from_ticker_list.csv'),
('CARB','A16_from_ticker_list.csv'),
('NTES','A17_from_ticker_list.csv'),
('AMZN','A18_from_ticker_list.csv'),
('TSN','A19_from_ticker_list.csv'),
('ATVI','A20_from_ticker_list.csv'),
('MKTX','A21_from_ticker_list.csv'),
('OTEX','A22_from_ticker_list.csv'),
('AYI','A23_from_ticker_list.csv'),
('EW','A24_from_ticker_list.csv'),
('STMP','A25_from_ticker_list.csv'),
('AMGN','A26_from_ticker_list.csv'),
('EDU','A27_from_ticker_list.csv'),
('ORLY','A28_from_ticker_list.csv'),
('ROST','A29_from_ticker_list.csv'),
('TTC','A30_from_ticker_list.csv'),
('REX','A31_from_ticker_list.csv'),
('JKHY','A32_from_ticker_list.csv'),
('ACN','A33_from_ticker_list.csv'),
('CCF','A34_from_ticker_list.csv'),
('HRL','A35_from_ticker_list.csv'),
('JNJ','A36_from_ticker_list.csv'),
('HCSG','A37_from_ticker_list.csv'),
('NKE','A38_from_ticker_list.csv'),
('ATR','A39_from_ticker_list.csv'),
('SHW','A40_from_ticker_list.csv'),
('LNTH','A41_from_ticker_list.csv'),
('YRD','A42_from_ticker_list.csv'),
('LEE','A43_from_ticker_list.csv'),
('TRN','A44_from_ticker_list.csv'),
('TJX','A45_from_ticker_list.csv'),
('CHD','A46_from_ticker_list.csv'),
('SBGL','A47_from_ticker_list.csv'),
('PSA','A48_from_ticker_list.csv'),
('DHR','A49_from_ticker_list.csv'),
('MKC','A50_from_ticker_list.csv'),
('EXPO','A51_from_ticker_list.csv'),
('IGXT','A52_from_ticker_list.csv'),
('GRC','A53_from_ticker_list.csv'),
('KTOS','A54_from_ticker_list.csv'),
('LPLA','A55_from_ticker_list.csv'),
('MKSI','A56_from_ticker_list.csv'),
('EQIX','A57_from_ticker_list.csv'),
('TILE','A58_from_ticker_list.csv'),
('SORL','A59_from_ticker_list.csv'),
('HIFR','A60_from_ticker_list.csv'),
('SNCR','A61_from_ticker_list.csv')
-- SYMBOL_ID values <= 24 values are from C:\stocks_for_mining\stocks_for_mining_A2_A25
-- SYMBOL_ID values > 24 AND <= 48 values are from C:\stocks_for_mining\stocks_for_mining_A26_A49
-- SYMBOL_ID values > 48 values are from C:\stocks_for_mining\stocks_for_mining_A50_A61
UPDATE WHILE_LOOP_FIELDS
SET path_file_name = for_update.new_path_file_name
FROM WHILE_LOOP_FIELDS
INNER JOIN
(
SELECT
[SYMBOL_ID]
,
CASE
WHEN SYMBOL_ID <= 24
THEN 'C:\stocks_for_mining\stocks_for_mining_A2_A25 - ' + path_file_name
WHEN SYMBOL_ID <= 48
THEN 'C:\stocks_for_mining\stocks_for_mining_A26_A49 - ' + path_file_name
WHEN SYMBOL_ID > 48
THEN 'C:\stocks_for_mining\stocks_for_mining_A50_A61 - ' + path_file_name
END new_path_file_name
FROM WHILE_LOOP_FIELDS
) for_update
ON WHILE_LOOP_FIELDS.SYMBOL_ID = for_update.SYMBOL_ID
The last code block before the WHILE loop performs two functions.
- It creates a temp table (#T) and some variables to facilitate passing successively through the rows of the WHILE_LOOP_FIELDS table
- Also, it creates two additional variables:
- @path_file_name is for the path and field name for each pass through the WHILE loop; these values are derived from successive rows of the WHILE_LOOP_FIELDS table
- @sql is for holding a dynamic SQL statement that performs a BULK INSERT of the appropriate csv file for the current pass through the WHILE loop
-- create temporary sequence in #T with identity #s
-- for each row in WHILE_LOOP_FIELDS
if OBJECT_id('tempdb..#T') IS NOT NULL
DROP TABLE #T
SELECT Identity(int, 1,1) AS PK
Into #T
FROM WHILE_LOOP_FIELDS
-- set variables for importing each data file
-- and adding symbols to consolidated table
Declare @maxPK int;Select @maxPK = MAX(PK) From #T
Declare @pk int;Set @pk = 1
DECLARE @SYMBOL varchar(4), @path_file_name varchar(100)
DECLARE @sql varchar(1000)
Here’s the T-SQL code to manage the operation of the WHILE loop with comments inside of the WHILE loop to indicate key operations within the loop. The code for the operations inside the loop will be covered subsequently. You can see that the code for managing the loop is very straightforward.
- The looping continues so long as @pk is less than or equal to @maxPK
- Both @pk and @maxPK are populated in the code immediately before the WHILE statement
- @pk is initialized to 1
- @maxPK is the maximum identity value for rows within the WHILE_LOOP_FIELDS table
- The BEGIN…END code block right after the WHILE statement contains seven code blocks that are invoked on each pass through the WHILE_LOOP_FIELDS table
- The first six code blocks within the BEGIN…END statement are represented just by comments, but the seventh nested code block shows code because it contributes to the operation of the loop
- The seventh code block increments the value of @pk by 1 after all the other processing for a row in the WHILE_LOOP_FIELDS table completes
- The DROP TABLE statement after the END marker in the BEGIN…END block closes a temp table to facilitate passing through the rows of the WHILE_LOOP_FIELDS table
-- Loop through rows with stock symbols and
-- data file paths and names
WHILE @pk <= @maxPK
BEGIN
-- Get a row from WHILE_LOOP_FIELDS
-- Clear a couple of tables for processing the next new file
-- Use path_file_name column value on the row to bulk insert
-- csv file for stock symbol to imported_stock_prices_lines table
-- start from csv file row after one with column headers
-- populate imported_stock_prices with
-- parsed values from imported_stock_prices_lines
-- propagate SYMBOL column value of row with the earliest date
-- to all subsequent rows in imported_stock_prices
-- CASE...END statement omits trailing carriage return
-- code in raw symbol data, which marks end of line
-- Populate table with consolidated ohlcv data
-- for all stock symbols in WHILE_LOOP_FIELDS
-- update @pk value for next row
-- from WHILE_LOOP_FIELDS
Select @pk = @pk + 1
END
DROP TABLE #T
The first code block within the WHILE loop assigns the SYMBOL and path_file_name column values from the WHILE_LOOP_FIELDS table for the row being processed to the @SYMBOL and @path_file_name variables.
-- Get a row from WHILE_LOOP_FIELDS Select @SYMBOL = [SYMBOL], @path_file_name = [path_file_name] From WHILE_LOOP_FIELDS Where SYMBOL_ID = @pk
Next, the imported_stock_prices_lines and imported_stock_prices tables are truncated. These two tables are freshly populated for each WHILE_LOOP_FIELDS table row.
-- Clear tables for new file TRUNCATE TABLE imported_stock_prices_lines TRUNCATE TABLE imported_stock_prices
Then, some dynamic SQL performs a BULK INSERT statement to populate the imported_stock_prices_lines table based on the file pointed at by the @path_file_name variable.
-- Use path_file_name column value on the row to bulk insert
-- csv file for stock symbol to imported_stock_prices_lines table
-- start from csv file row after one with column headers
SET @sql = 'BULK INSERT imported_stock_prices_lines '
+ 'FROM ''' + @path_file_name + ''' '
+ 'WITH '
+ '('
+ 'FIRSTROW = 2, FIELDTERMINATOR = '','', ROWTERMINATOR = ''0x0a'''
+ ');'
EXEC (@sql)
After that, the column values are extracted from between the commas in the imported_stock_prices_lines table and inserted into the imported_stock_prices table. The custom code uses CHARINDEX functions, nested within one another as required, to extract the comma delimited values in each row within the imported_stock_prices_lines table. A couple of factors require this special coding for extracting commas separated values within rows of the imported_stock_prices_lines table to individual column values within the imported_stock_prices table.
- The rows have a jagged right edge with the edge for the first row extending beyond the other rows because the ticker symbol value is only on the first row
- The csv file generated by the Google Sheets results in the last row being omitted for selected ticker symbols; the custom code fixes this issue
- Also, notice the TRY_PARSE function with an “as money” specification for [open], [high], and [low] column values; this function returns a NULL value when the value between commas will not convert to a SQL Server money data type; without this function the processing of rows can fail for bad data
-- populate imported_stock_prices with
-- parsed values from imported_stock_prices_lines
INSERT INTO [dbo].[imported_stock_prices]
SELECT
-- extract date value from chars before first comma
CAST(SUBSTRING(LINE,1,CHARINDEX(',',line)-1) as date) [date]
-- get the value between the first and second commas
,
TRY_PARSE(
SUBSTRING
(
LINE
,CHARINDEX(',',LINE)+1
,CHARINDEX(',',LINE
,CHARINDEX(',',LINE)+1)
- CHARINDEX(',',LINE) -1
)
as money
) [open]
-- get the value between the second and third commas
,TRY_PARSE(
SUBSTRING
(
LINE
,CHARINDEX(',',LINE
,CHARINDEX(',',LINE)+1)+1
,CHARINDEX(',',LINE
,CHARINDEX(',',LINE
,CHARINDEX(',',LINE)+1)+1)
- CHARINDEX(',',LINE,CHARINDEX(',',LINE)+1) -1
)
as money
) [high]
-- get the value between the third and fourth commas
,TRY_PARSE(
SUBSTRING
(
LINE
,CHARINDEX(',',LINE
,CHARINDEX(',',LINE
,CHARINDEX(',',LINE)+1)+1)+1
,CHARINDEX(',',LINE
,CHARINDEX(',',LINE
,CHARINDEX(',',LINE
,CHARINDEX(',',LINE)+1)+1)+1)
- CHARINDEX(',',LINE,CHARINDEX(',',LINE,CHARINDEX(',',LINE)+1)+1) -1
)
as money
) [low]
-- get the value between the fourth and fifth commas
,CAST(
SUBSTRING
(
LINE
,CHARINDEX(',',LINE
,CHARINDEX(',',LINE
,CHARINDEX(',',LINE
,CHARINDEX(',',LINE)+1)+1)+1)+1
,CHARINDEX(',',LINE
,CHARINDEX(',',LINE
,CHARINDEX(',',LINE
,CHARINDEX(',',LINE
,CHARINDEX(',',LINE)+1)+1)+1)+1)
- CHARINDEX(',',LINE,CHARINDEX(',',LINE,CHARINDEX(',',LINE,CHARINDEX(',',LINE)+1)+1)+1) -1
)
as money
) [close]
-- get the value between the fifth and sixth commas
,CAST(
SUBSTRING
(
LINE
,CHARINDEX(',',LINE
,CHARINDEX(',',LINE
,CHARINDEX(',',LINE
,CHARINDEX(',',LINE
,CHARINDEX(',',LINE)+1)+1)+1)+1)+1
,CHARINDEX(',',LINE
,CHARINDEX(',',LINE
,CHARINDEX(',',LINE
,CHARINDEX(',',LINE
,CHARINDEX(',',LINE
,CHARINDEX(',',LINE)+1)+1)+1)+1)+1)
- CHARINDEX(',',LINE,CHARINDEX(',',LINE,CHARINDEX(',',LINE,CHARINDEX(',',LINE,CHARINDEX(',',LINE)+1)+1)+1)+1) -1
)
as bigint
) [volume]
,
-- get the string after the sixth comma
-- including carriage return code for end of line
RTRIM(SUBSTRING(
LINE
,CHARINDEX(',',LINE
,CHARINDEX(',',LINE
,CHARINDEX(',',LINE
,CHARINDEX(',',LINE
,CHARINDEX(',',LINE
,CHARINDEX(',',LINE)+1)+1)+1)+1)+1)+1,
4
)) SYMBOL
FROM [dbo].[imported_stock_prices_lines]
After the imported_stock_prices table is initially populated based on the csv file for a source tab inside a Google sheet, the processing moves on to populating the SYMBOL column for all rows in the table (up to this point, there is only a SYMBOL column value for the first row).
- ASCII codes 97 through 122 denote the lower case letters from a through z
- Legitimate SYMBOL column values for this tip can consist of 1 through 4 lower case letters from a through z
- Legitimate ticker symbol values from the first row in the imported_stock_prices table are used to update the SYMBOL column values of all rows in the imported_stock_prices table
-- propagate SYMBOL column value of row with the earliest date -- to all subsequent rows in imported_stock_prices -- CASE...END statement omits trailing carriage return -- code in raw symbol data, which marks end of line SET @SYMBOL = ( SELECT TOP 1 CASE WHEN ASCII(SUBSTRING(SYMBOL,4,1)) >= 97 AND ASCII(SUBSTRING(SYMBOL,4,1)) <= 122 THEN SYMBOL WHEN ASCII(SUBSTRING(SYMBOL,3,1)) >= 97 AND ASCII(SUBSTRING(SYMBOL,3,1)) <= 122 THEN LEFT(SYMBOL,3) WHEN ASCII(SUBSTRING(SYMBOL,2,1)) >= 97 AND ASCII(SUBSTRING(SYMBOL,2,1)) <= 122 THEN LEFT(SYMBOL,2) WHEN ASCII(SUBSTRING(SYMBOL,1,1)) >= 97 AND ASCII(SUBSTRING(SYMBOL,1,1)) <= 122 THEN LEFT(SYMBOL,1) ELSE NULL END FROM dbo.imported_stock_prices ) UPDATE dbo.imported_stock_prices SET SYMBOL = @SYMBOL
Processing for a row in the WHILE_LOOP_FIELDS table completes when the character values in columns of the imported_stock_prices table are inserted into the stocks_symbol_ohlcv table. This final processing step:
- Assigns appropriate data types to the string values that reside in the source imported_stock_prices table
- Collects the transformed data from across all the original Google sheet tabs within a single SQL Server table (stocks_symbol_ohlcv)
-- Populate table with consolidated ohlcv data -- for all stock symbols in WHILE_LOOP_FIELDS INSERT INTO stocks_symbol_ohlcv ( [SYMBOL], [date], [open], [high], [low] , [close], [volume] ) SELECT [SYMBOL], [date], [open], [high], [low] , [close], [volume] FROM imported_stock_prices;
Data Issues with Google Finance and Historical Data
Reviewing a couple of data issues can give you a feel for the quality of historical data that you get from Google Finance as well as how validly this tip maps source data from Google sheets to a SQL Server table.
The following screen shot shows the top 3 and bottom 3 rows for the drd symbol from the stocks_symbol_ohlcv table along with the path_file_name column to identify its source tab in an underlying Google sheet. The next pair of screen shots shows the corresponding rows from the A5_from_ticker_list tab in the stocks_for_mining_A2_A25 Google sheet. Here are some data quality issues that merit your attention.
- The historical values map as specified between the loaded data in SQL Server and the source data in the Google Sheet tab; recall that bad data, such as #N/A for a money data type value, in a Google sheet map to a NULL value in SQL Server. This outcome for row 1 of the result set for the top three rows confirms the validity of the approach for loading data from Google Finance to a SQL Server database
- The very first row in the result set for the top three rows had bad data for at least 3 columns (open, high, and low); these bad values were converted to NULL values when loaded to SQL Server. Also, the volume column value was curious because it showed a value of 0 shares traded for the day.
- These findings suggest there may be Google Finance data issues that can benefit from fixes for selected dates and symbols combinations



Here’s a query for count of rows loaded by ticker symbol with the first 18 rows of the result set showing in the screen shot.
- For the acn and eqix symbols (compare row 1 in the result set versus row 18 in the screen shot below), the number of rows loaded are different by hundreds although both symbols start their data series on the same date; again, the source data from the Google Sheet tabs perfectly match the loaded data in SQL Server
- Aside from eqix, 41 of the 60 stock symbols started their data series on January 3, 2006, but the number of rows returned by Google Finance was different by 1 for about half the symbols
- 23 of the 41 symbols returned 2701 rows
- 18 of the 41 symbols returned 2700 rows
- For the 18 symbols with a missing row, the date was always April 1, 2010

Some top line conclusions from reviewing data quality issues are the following.
- The process described in this tip loads data into SQL Server that perfectly match the source data from Google Finance
- The Google Finance site has occasional data quality issues. The review from this tip confirms these issues are relatively rare
- Data quality lapses can be repaired by referring to alternate sources, such as Yahoo Finance or other data providers of historical data
- There was no detailed data quality analysis of stock history data for alternative providers so we can say whether Google has more data quality issues than any other. However, it was possible to verify that repairs could be made to data from Google Finance based on data from Yahoo Finance
- Neither Yahoo Finance nor other providers of free historical stock data have a function comparable to the GOOGLEFINANCE in Google Sheets, which may make Google Finance a preferred choice for downloading historical stock data for a bunch of ticker symbols
Next Steps
This tip demonstrates how to download data for a set of 60 stock ticker symbols with the help of the GOOGLEFINANCE function in Google Sheets. The tip also covers how to copy the downloaded stock history data from Google Sheets to Google Drive and ultimately to SQL Server.
Here are some suggested next steps depending on your needs and interests.
- You can configure accounts for using Google Sheets and Google Drive, copy the import_downloaded_data_into_SQL_Server.sql script file from the resource file for this tip, and confirm that you can get the tip to work on your computer
- You can use the historical data for the 60 symbols to test and explore stock trading strategies using a framework demonstrated in a prior MSSQLTips tip (SQL Server Data Mining Strategies for Stock Buy and Sell Recommendations). The prior tip examined trading strategies for just 10 stock symbols
- Another next step is to examine ways of easily expanding the number of stock symbols for which you can easily download data. For example, you can save in a backup table the stock history data for the 60 ticker symbols in this tip, and then re-run the solution for a different set of 60 ticker symbols. This simple step will double the number of stock symbols available for stock data mining and trading strategy evaluations
- Finally, you can explore ways of automating selected manual steps within the process described within this tip. There is a scripting language for Google Sheets that can facilitate this objective
The resource files folder for this tip includes the import_downloaded_data_into_SQL_Server.sql file, which contains the script for automating the importing of csv files from Google Drive to SQL Server. The resource files folder also contains a couple of other scripts used to highlight the validity of the data loaded into SQL Server as well as data issues with historical stock data from Google Finance. There are other miscellaneous files in the resource files folder that are likely to simplify any next steps that you may pursue with this tip. Therefore, please be sure and review the readme.txt file in the resource files folder before trying to reproduce any results in this tip.
Finally, I close by indicating that this tip is not recommending any particular stocks, including the 60 stocks used in this demonstration. Actually, the Google Sheets for this tip, which you can find by following links presented towards the top of this tip, include more than 60 stock symbols. You may find the additional stock symbols useful for augmenting the base set that you can download from the sheets as they are. At the time that I submitted this tip to MSSQLTips.com, I or other immediate family members, held positions in a handful of stocks among those in the sheets.

Rick Dobson is a SQL Server professional with decades of T-SQL experience that includes authoring books, running a national seminar practice, working for businesses on finance and healthcare development projects, and serving as a regular contributor to MSSQLTips.com. He has been a practicing Python developer for more than the past half decade – with a special emphasis for data visualization and ETL tasks with JSON and CSV files. His most recent professional passions include financial time series data and analyses, AI models, and statistics. If you are interested in growing your skills in any of these areas especially as they relate to financial securities, consider visiting his blog at https://securitytradinganalytics.blogspot.com/2023/12/.
- MSSQLTips Awards: Leadership (200+ tips) – 2025 | Author of the Year Contender – 2017-2024


