Problem
As a SQL Server database developer or database DevOps engineer my development team has been tasked to include reference data with the database(s) so that deploying the database should populate the reference tables on any target environment which can help maintain the reference data throughout the database lifecycle management (DLM).
This step of adding reference data should also be included in the database continuous integration (CI) pipeline.
Solution
The solution is to use post-deployment scripts which points to reference data scripts to populate reference tables using SQL Server Data Tools (SSDT) with Visual Studio Team Services (VSTS).
During the database continuous integration, DACPAC artifacts are produced as a result of a successful automated build. This includes reference data along with database structure. The reference data is vital in testing as well.
Let’s go through some of the key concepts of reference data.
What is Reference Data?
Reference data is a reference table or set of reference tables which has supporting information for other tables in the database.
In most of the cases, reference tables’ columns are passed as foreign key(s) to main transactional tables of the database.
For example, if we have a country table which contains list of all the countries then this is considered as a reference table and its (primary) key column (CountryId) can be passed as a foreign key in another table such as Address.
We can also have custom reference types such as customer type table which is also a reference table.

How Reference Data is obtained
Next thing that comes to mind is how reference data is obtained or in other words how do reference tables get populated.
Initially reference tables may already exist in your Production database so keeping in mind that you comply with GDPR (General Data Protection Regulation which is to be effective soon) reference tables with data can be obtained from a Production database as long as the data does not directly contain personally identifiable information or business sensitive information.
Another way is to create reference tables from scratch based on the requirements such as if you are getting feedback (FeedbackId, CustomerName, RatingId, etc.) from customers in the form of a table, then it is worth considering having a rating reference table (RatingId, RatingName, RatingDetail) which can help you in data analysis and reporting.
Often reference tables are created as a result of business requirements or rules.
How Reference Data is maintained
Reference tables in the context of SQL Server Data Tools (SSDT) are part of database project and are created just like other tables with the exception of their data scripts which run in a batch in a post-deployment script.
Debugging the database project creates a debug database first and deploys changes afterwards which is followed by a post-deployment script that populates reference tables in the debug database.
Please go through my tip about test-drive development using tSQLt to see an example of how reference data is used in a project from stage to stage.
Adding Reference Data in Digital Services Database Continuous Integration (CI) Workflow
This tip assumes that you have run through all steps in my tip about Basic Database Continuous Integration and Delivery (CI/CD) using Visual Studio Team Services (VSTS).
Now that you have created “Digital Services Database” and enabled database continuous integration for your database, it is time to add some reference data in the database CI/CD pipeline.
Let’s first reload the database project to have a look:

Adding Client Type Reference Table
Let’s create a table to hold reference data for client types as follows:
CREATE TABLE [dbo].[ClientType]
(
[ClientTypeId] INT NOT NULL IDENTITY(1,1),
[Name] VARCHAR(40) NOT NULL,
[Detail] VARCHAR(200) NULL,
CONSTRAINT [PK_ClientType] PRIMARY KEY ([ClientTypeId])
)

Adding Reference Data for Client Type Table
Reference data for ClientType table can be added in two ways:
- Create an insert data script directly
- Debug the project and add data to the table in the debug database and then script out the inserted data
Let’s debug the project to deploy new changes (ClientType table) to the debug database.

Now right click on ClientType table and then click on “View Data” and start entering values as follows:
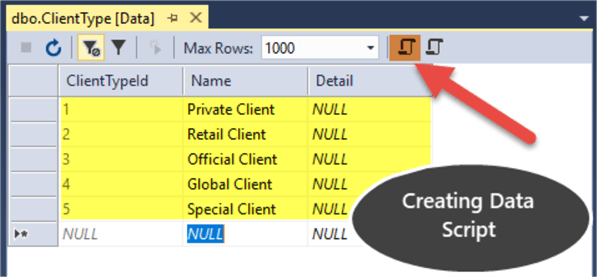
Next click on the top left script icon to create data script as shown below:
SET IDENTITY_INSERT [dbo].[ClientType] ON
INSERT INTO [dbo].[ClientType] ([ClientTypeId], [Name], [Detail]) VALUES (1, N'Private Client', NULL)
INSERT INTO [dbo].[ClientType] ([ClientTypeId], [Name], [Detail]) VALUES (2, N'Retail Client', NULL)
INSERT INTO [dbo].[ClientType] ([ClientTypeId], [Name], [Detail]) VALUES (3, N'Official Client', NULL)
INSERT INTO [dbo].[ClientType] ([ClientTypeId], [Name], [Detail]) VALUES (4, N'Global Client', NULL)
INSERT INTO [dbo].[ClientType] ([ClientTypeId], [Name], [Detail]) VALUES (5, N'Special Client', NULL)
SET IDENTITY_INSERT [dbo].[ClientType] OFF
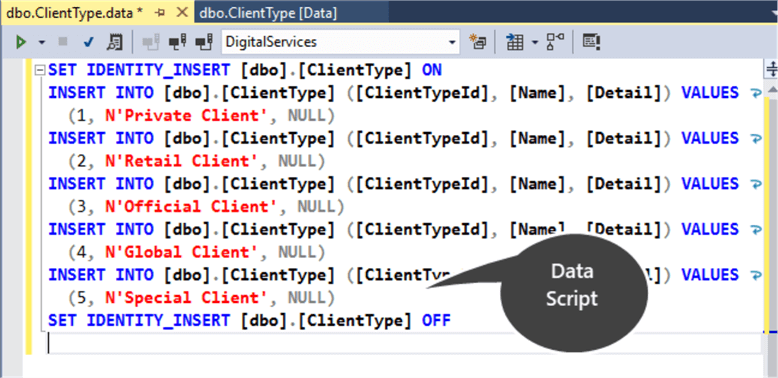
Creating Reference Data Script
Create a “Reference Data” folder in the database project and add a script named “ClientType.data” under it as follows:

Copy the script in dbo.ClientType.data and paste it in the ClientType.data script.

Next add a post-deployment script and refer to the ClientType.data script as follows (also make sure SQLCMD is enabled):

Debug Database Setup
Please make sure the “Always re-create database” deployment option is checked under Debug Menu as follows:

The “Always re-create database” option can help us to populate reference tables as many times as possible since the debug database is going to be created from scratch each time the project is debugged which is going to delete the existing reference table data and repopulate the table from the script without causing conflicts.
Considering we are working in Local Dev environment so “Always re-create database” option is fine, however, for other environments the approach may differ depending on the requirements.
At this point, please close without saving the dbo.ClientType.data window as we have created the ClientType.data script from it. Now, save the project from the File menu or pressing Ctlr+Shift+S keys.
Quick Data Script Check
Now right click on ClientType table in the debug database and delete it.
Then debug the project to see if Client Type table is back and populated.
The ClientType table must be back with reference data rows in it if you have followed all the instructions so far.
Update Client Table to Add ClientTypeId as Foreign Key Constraint
Let’s now logically connect the Client table with the ClientType table by introducing a ClientTypeId Foreign Key in the Client table.
Open the client table from the DigitalServices database project and replace the existing code with the following:
-- Creating Client table with ClientTypeId Foreign Key
CREATE TABLE [dbo].[Client]
(
[ClientId] INT NOT NULL IDENTITY(1,1) ,
[ClientTypeId] INT NOT NULL,
[Company] VARCHAR(40) NOT NULL,
[Email] VARCHAR(320) NOT NULL,
[Phone] VARCHAR(50) NULL,
[RegistrationDate] DATETIME2,
[Status] bit,
CONSTRAINT [PK_Client] PRIMARY KEY ([ClientId]),
CONSTRAINT [FK_Client_ClientType] FOREIGN KEY ([ClientTypeId]) REFERENCES [ClientType]([ClientTypeId])
);
Update Clients View to Add ClientTypeId
The view we created in my previous tip about Basic Database Continuous Integration and Delivery (CI/CD) using Visual Studio Team Services (VSTS) needs to be updated to reflect the new changes as follows:
-- View to see clients information
CREATE VIEW dbo.Clients
AS
SELECT
c.ClientId,
ct.Name,
c.Company,
c.Email,
c.Phone,
c.RegistrationDate,
c.Status
FROM Client c
INNER JOIN ClientType ct
ON c.ClientTypeId = ct.ClientTypeId
Check the Code into Source Control (Git)
Next check the changes into source control to see an automated Build getting kicked off as a result of database continuous integration.

Check the web portal to see that the automated Build begins because database objects and data scripts were put under source control:

In a couple of minutes, the Build should succeed as shown below:

Let’s now look at the Build details and click on the Artifacts Tab as shown below:
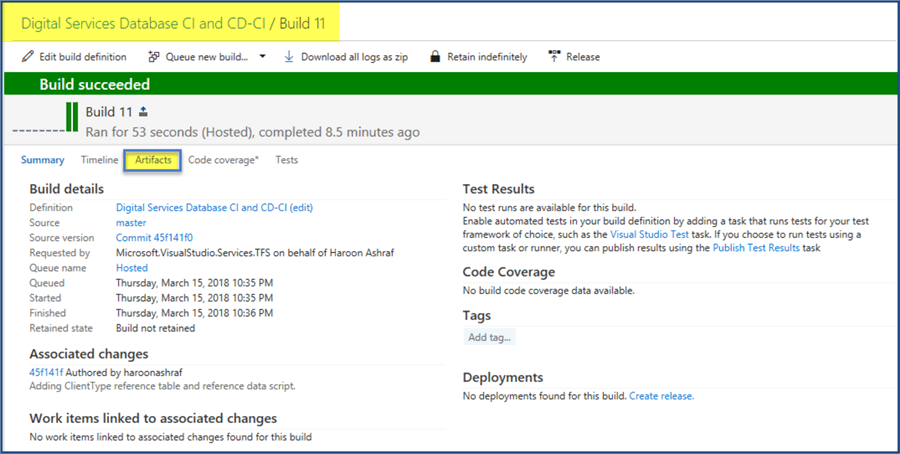
Download DACPAC Artifact
Next click on the Artifacts tab under the Build details page and download DACPAC locally on your dev machine.

You can download the DACPAC file I created.
Publish New Database using DACPAC
Next open another instance of Visual Studio and open SQL Server Object Explorer (SSOX).
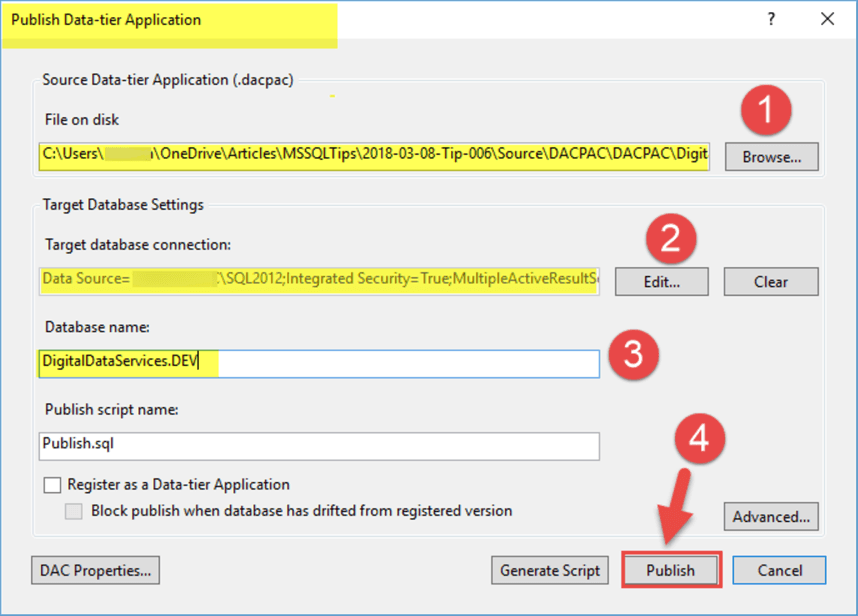
Right click on the Database and select “Publish Data-tier Application…” as shown below:

Next browse the DACPAC file and provide the name for the database “DigitalDataServices.Dev” to be published and click on “Publish” button as follows:

Check the Database Built from DACPAC
Next open the database and check the objects that have successfully been created.
Now right click on the ClientType table and click on “View Data” as follows:

Congratulations! The artifact (DACPAC) contains the data along with the database objects and it has not only successfully created the whole database, but also populated the ClientType table.
So, we have demonstrated how to add reference data in the database continuous integration pipeline.
Next Steps
- Try adding more reference tables and their data scripts in the database continuous integration pipeline
- Please go through my Tip 4 and see if you can replicate developing multi-customer database using database continuous integration and delivery along with adding reference data
- Please have a look at my Tip 2 to add tSQLt unit tests to your project and see if you can add those tests in VSTS Build
- Try creating the whole project mentioned in the my Tip 3 using test-driven development (TDD)
- Please explore further Database CI/CD by visiting VSTS home page

Haroon Ashraf’s deep interest in logic and reasoning at an early age of his academic career paved his path to become a data professional.
He holds BSc (Gold Medal) and MSc Degrees in Computer Science and also received the OPF merit award.
His programming career began in 2006 working on his first data venture to migrate and rewrite a public sector database driven examination system from IBM AS400 (DB2) to SQL Server 2000 using VB 6.0 and Classic ASP along with developing reports and archiving many years of data.
His work and interest revolves around Business Intelligence and Database Centric Architectures and his expertise include database and reports design, development, testing, implementation and migration.
He has recently earned “Knowledge Management and Big Data in Business” certificate from The Polytechnic University of Hong Kong.
- MSSQLTips Awards: Trendsetter (25+ tips) – 2020 | Author of the Year Contender – 2018-2020
