Problem
Reference data is added to the SQL Server database by multiple developers and testers, thereby causing inconsistencies in the database due to reference data updated by one developer getting overwritten by another developer/tester and so on.
Solution
To overcome this issue, adopt reference data best practices by using Merge scripts which not only avoids such conflicts, but also keeps the database in a consistent and reliable state. Please refer to my previous tip to get a basic understanding of reference data if you are not already familiar with it.
Reference Data Best Practices Part -1 Recap
In the first part of the article we replicated the scenario where two different database developers are publishing reference data (tables) to their debug databases followed by a shared development database using a post deployment script.
The above scenario works well when changes along with reference data is deployed to the debug databases within their local development environment, but when it comes to publishing the database changes to the shared development database, the reference data by one developer gets erased by the reference data added by the second developer.
The reason being, the Always re-create database option is checked under Target Connection String in SQL Database Project, which is fine to do as far as the debug database and Local Development Environment is concerned, but it does not work properly when it comes to a shared development environment.
To resolve this, we unchecked the Always re-create database option and introduced a change script using “IF Not Exists” in data scripts in such a way that the reference data is only written to the tables if it has not already been written.
This can be illustrated as follows:

Please refer to part-1 of this article to better understand how to implement the first solution by using IF NOT Exists logic in data scripts to deploy reference data to a debug database followed by a shared development database.
Limitations of Current Approach
The use of “IF NOT Exists logic” works well from one perspective, but this is not an optimum solution to deploy reference tables data by multiple developers.
This approach has the following limitations despite the fact that it is applicable:
- The code becomes messy as more and more reference data is added to the tables which becomes difficult to maintain afterwards.
- What if we want to keep the data inserted by the test team in a shared development environment prior to the post deployment scripts then more laborious work is required.
- This approach requires a row level data check which can save a lot of time if we can apply it to table level.
- This approach is not flexible enough to move from environment to environment for example from local dev to shared dev, shared dev to test, test to QA and so on.
- This approach does not support a pure declarative style to comply with the rest of the database project pattern.
Using Merge Script to Deploy Reference Data
A better way to deploy reference tables (with data) to the desired environments managed by multiple developers is to use a merge script.
Moreover, we have not purely made our data script declarative which means the script should be totally repeatable no matter how many times it runs against whatever environment.
According to Garry Trinder (SQL Server Data Tools Team Blog), a Merge script can actually make our data script(s) declarative so that we can write a single script to handle insert, update and delete all in one. According to Deborah Kurata, use a Merge script when you want more control over how your data script is processed.
Merge was introduced in SQL Server 2008 and is compatible with all versions after that including Azure SQL Database.
Merge Script Structure
Reference Table
MERGE INTO <Reference Table> AS Target
USING (VALUES
(1, ’First’),
(2, ’Second’),
(3, ’Third’),
)
AS Source (<ID>,<Name>)
ON Target.ID = Source.ID
Update Name from Source
when ID Matched
WHEN MATCHED THEN
UPDATE SET Name = Source.Name
Add New Name and
ID When Not in Target
WHEN NOT MATCHED BY TARGET
THEN
INSERT (ID, Name)
VALUES (ID, Name)
Delete When Record
is in Target but not in Source
WHEN NOT MATCHED
BY SOURCE THEN
DELETE
Setup Cars Sample Solution (Database Projects)
Please refer to part-1 of this tip to go through all the steps of creating database projects under the Cars Sample Solution to publish reference tables (with data) to a Local Development Environment and a Shared Development Environment named dev1 and dev2.
Review the projects where they were left in the first part of this article to proceed further.

Dev1 Local Development Environment
Dev1 Local Development Environment is used to deploy initial changes to the debug database simply by debugging the dev1 database project.
We have used LocalDB to replicate Local Development Environment as follows:
Dev2 Local Development Environment
The same localdb is used to replicate Dev2 Local Development Environment as follows:

Dev1 and Dev2 Shared Development Environment
Then SQL Server instance is used to mock a shared development environment as shown below:

Adding Merge Script to Dev1 Reference Data
If we want the data script managed by Dev1 to be written successfully on a local dev database and a shared dev database then a Merge script is the answer.
A Merge script as mentioned earlier, works as a composite statement which inserts the data if it is not already present, updates the data if it is different than source based on ID and deletes the data if other than source.
Update CarMake reference data script (CarMake.data.sql) as follows:
-- Adding reference data to CarMake table
SET IDENTITY_INSERT [dbo].[CarMake] ON
MERGE INTO [dbo].[CarMake] AS Target
USING (VALUES
(1, N'Honda', NULL),
(2, N'Toyota', NULL),
(3, N'BMW', NULL),
(4, N'Volvo', NULL),
(5, N'Wolkswagen', NULL)
)
AS Source (CarMakeId, Name, Detail)
ON Target.CarMakeID = Source.CarMakeID
-- Update Name and Detail from Source when ID is Matched
WHEN MATCHED THEN
UPDATE SET
Name = Source.Name
,Detail=Source.Detail
--Add New Name and Detail When ID is Not in Target
WHEN NOT MATCHED BY TARGET THEN
INSERT (CarMakeId, Name, Detail)
VALUES (CarMakeId, Name, Detail)
--Delete When record is in Target but not in Source
WHEN NOT MATCHED BY SOURCE THEN
DELETE;
SET IDENTITY_INSERT [dbo].[CarMake] OFF
Adding Merge Script to Dev2 Reference Data
Similarly, reference data script for Dev2 (CarType.data.sql) can also be modified using a Merge script as follows:
-- Add reference data to CarType table using Merge script
SET IDENTITY_INSERT [dbo].[CarType] ON
--Reference Data for Reference Table
MERGE INTO [dbo].[CarType] AS Target
USING (VALUES
(1, N'Estate', NULL)
,(2, N'SUV', NULL)
,(3, N'Saloon', NULL)
,(4, N'Hatchback', NULL)
,(5, N'MPV', NULL))
AS Source (CarTypeID,Name,Detail)
ON Target.CarTypeID = Source.CarTypeID
--Update Name and Detail from Source when ID Matched
WHEN MATCHED THEN
UPDATE SET Name = Source.Name,
Detail=Source.Detail
--Add New Name and ID When Not in Target
WHEN NOT MATCHED BY TARGET THEN
INSERT (CarTypeID, Name,Detail)
VALUES (CarTypeID,Name,Detail)
--Delete When record is in Target but not in Source
WHEN NOT MATCHED BY SOURCE THEN
DELETE;
SET IDENTITY_INSERT [dbo].[CarType] OFF
Unchecking Always re-create database option
Since Merge is capable of handling the situation when data already exists, let’s uncheck “Always re-create database” under Database Project Settings > Debug. Deployment options for both Dev1 and Dev2:

Deploying to Local Development Environment (Dev1 and Dev2)
Press F5 to start deploying changes to the local dev environment (localdb in our case) for Dev1 first:

Add some more records in Dev1’s debug database (CarsSampleDev1) as follows:

Now Run the Merge script again by debugging Dev1 Project (CarsSampleDev1) and refresh the CarMake reference table:

The Merge script has synched the database project with the debug database (Local Development Environment) without the need of using the “Always re-create database” option.
Debug CarsSampleDev2 database project to deploy the changes to localdb (Local Development Environment).
Let’s now delete the last two records from the CarsSampleDev database:

Debugging the CarSampleDev2 database project gets the deleted records back:

Deploying to Shared Dev Environment (Dev1 and Dev2)
Deploy dev1 changes (CarsSampleDev1.publish.xml) to the shared dev environment using publish script:

Next, use publish script to deploy dev2 changes (CarsSampleDev2.publish.xml) to the shared dev environment.
View CarsSample shared dev database reference tables after both publish scripts have run successfully:

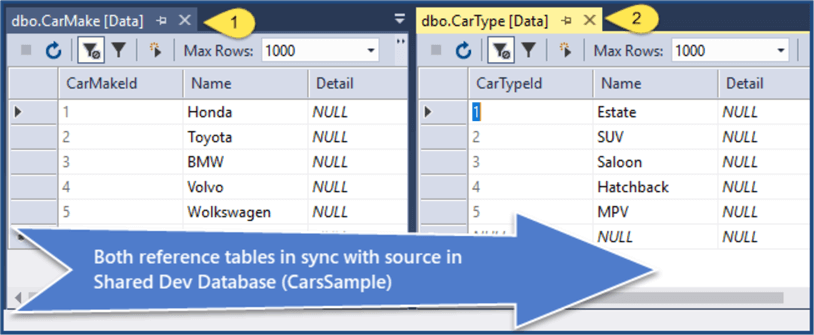
Congratulations, the Merge script has been applied successfully to deploy reference tables to target database environment(s).
Reviewing Reference Data Best Practices
Let’s extract some best practices that we have learned so far when it comes to reference data:
- It is better to use a Merge script to deploy reference data to the target database(s).
- A Merge script is best used if INSERT, UPDATE and/or DELETE rules are all required.
- A Merge script for reference data less than 1000 records does not need to load the data into temporary tables rather it handles it as an inline script.
- Reference data deployment by a Merge script is best suited when the size of the reference table is less than 1000 records.
- DELETEs in Merge script must be omitted if you want to keep the changes done by other developers or testers on the database directly using connected database development mode.
Next Steps
- Please try implementing the solution where you want to keep the changes done by other developers or testers on the database.
- Please try adding more deployment environments such as QA/Test and add related publish scripts using the Merge statement in such a way that for shared dev the direct changes on the database are not allowed, but for test direct changes on the database reference tables must not be deleted.
- Please add reference tables and referencing tables (pointing to reference tables data) to your solution using Merge script.

Haroon Ashraf’s deep interest in logic and reasoning at an early age of his academic career paved his path to become a data professional.
He holds BSc (Gold Medal) and MSc Degrees in Computer Science and also received the OPF merit award.
His programming career began in 2006 working on his first data venture to migrate and rewrite a public sector database driven examination system from IBM AS400 (DB2) to SQL Server 2000 using VB 6.0 and Classic ASP along with developing reports and archiving many years of data.
His work and interest revolves around Business Intelligence and Database Centric Architectures and his expertise include database and reports design, development, testing, implementation and migration.
He has recently earned “Knowledge Management and Big Data in Business” certificate from The Polytechnic University of Hong Kong.
- MSSQLTips Awards: Trendsetter (25+ tips) – 2020 | Author of the Year Contender – 2018-2020
