Problem
In the world of polyglot persistence, each data asset should get the best matching database management tool. Many companies these days keep their data assets in multiple data stores. Many companies that I have worked at have used other database systems alongside SQL Server, such as MySQL instances, Redis, Elasticsearch or Couchbase. There are situations when the application, that uses SQL Server as their main database, needs to access data from another database system. For instance, in legacy applications, developers might demand a transparent solution at the database level, so their interfaces would not change.
Some datastores have ODBC/JDBC drivers so you can easily add a linked server and use it inside your procedures. Some datastores do not have such an easy way of accessing its data, so we will look at what we can do with SQL Server and Python to access these other platforms.
Solution
Python support was introduced in SQL Server 2017 and opens a new perspective on querying remote databases. Using the sp_execute_external_script procedure allows us to query any database that has a Python library. The query results can be used later on in any Transact SQL logic inside SQL Server stored procedures. Such solutions offload the hard work of scanning, filtering and aggregating data to the remote database while your application continues to work with SQL Server. Moreover, you can access huge tables, that may cause query performance issues, from any fast datastore and still serve the queries through SQL Server.
Preliminary Setup Steps
In order to use the sp_execute_external_script procedure to execute Python scripts, you will need to follow these 3 steps:
Step 1. Enable external scripts execution:
exec sp_configure 'external scripts enabled', 1 RECONFIGURE
Step 2. In order to avoid firewall errors, I disabled the Windows Firewall, but the right way would be to figure out how to set the correct configurations. If the Windows Firewall is on, Python scripts that are trying to access external resources will fail.
Step 3. In order to use additional Python libraries, we will install them using the PIP utility. The PIP utility has been installed as a part of the SQL Server installation wizard ( Machine Learning > Python support ). See this for Detailed installation steps.
For the purpose of this tip I will show how to access data stored in the NoSQL database – Elasticsearch. Elasticsearch is widely used as an addition to other databases, more like a fast data reading layer. You can read more about Elasticsearch.
We will install the elasticsearch library to connect to the Elasticsearch cluster. Start windows cmd. Note that the path below can vary depending on the disk where you have installed the SQL Server binaries.
cd C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\PYTHON_SERVICES\Scripts pip install <library> , in my case pip install elasticsearch
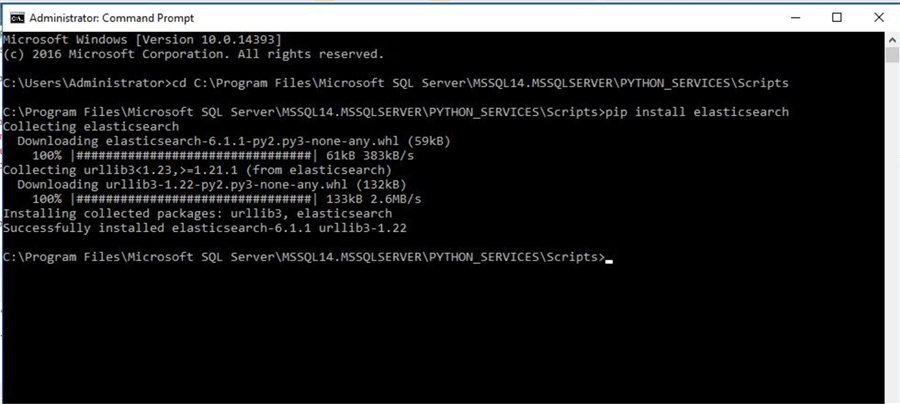
That’s it, we are ready to go.
Query Elasticsearch Cluster
In Elasticsearch, data is stored in indexes which is a data logical namespace similar to a database or table, depending on the implementation. You can read more about Elasticsearch indexes here.
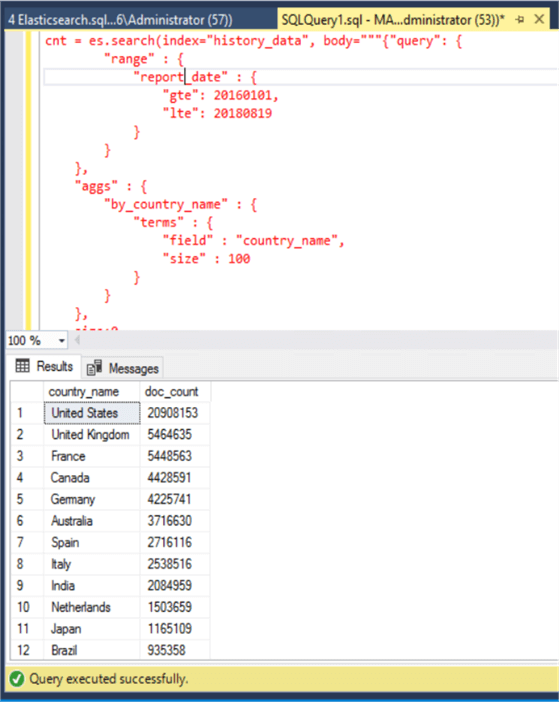
The below example is a simple group by query. Elasticsearch query language is somewhat weird, but understandable. This script is searching history_data index. We add a range filter on the report_date column between 20160101 and 20180819 and calculate the amount of documents (count (*) ) per country_name and alias the new column as by_country_name. This query returns top the 100 groups.
{"query": {
"range" : {
"report_date" : {. —- here is our filter
"gte": 20160101, —- report_date greater than 20160101
"lte": 20180819 — report_date less then 20180819
}
}
},
"aggs" : {
"by_country_name" : {. Terms aggregation means GROUP BY , by default uses count function
"terms" : {
"field" : “country_name", — aggregated field
"size" : 100 — bring top 100 groups
}
}
},
size:0
}
We will use 2 external libraries in our script:
- Pandas library which is preinstalled during the SQL Server installation to pass a python resultset back to SQL Server.
- Elasticsearch library to connect to the Elasticsearch cluster that we have installed at the beginning of this tip.
import pandas as pd from elasticsearch import Elasticsearch
Connection to Elasticsearch cluster:
es = Elasticsearch(hosts=["servername"], request_timeout=100, timeout=100)
We will execute Elasticsearch query and will print the result set:
cnt = es.search ( IndexName, Query) print (cnt)
This is what the Elasticsearch query result looks like.
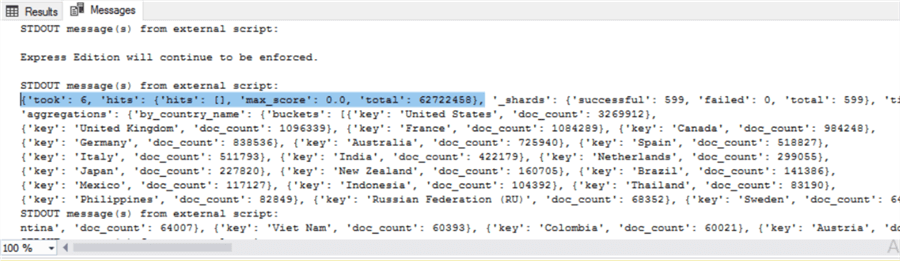
In order to convert this JSON document to a SQL Server resultset, we will do the following:
- Define jvalues variable as a list (collection of items)
- Loop over [“aggregations"]["by_country_name"]["buckets"] part of the json document
- Define another variable res as a dictionary (collection which contains key:value pairs)
- We can get the first key “Key” (surprisingly) and as you see from the above its value contains the Country name
- We will call the second key “total” and it will contact “doc_count” / count * of documents that belong to this country
- Then we will add the created dictionary to the jvalues list
- After the loop is over, we will feed the jvalues list into DataFrame, two-dimensional tabular data structure from pandas library. This is the standard way that SQL Server expects to get results from a Python external script.
1 jvalues = []
2 for val in cnt["aggregations"]["by_country_name"]["buckets"]:
3 res = {}
4 res["key"] = val["key"]
5 res["total"] = int(val["doc_count"])
6 jvalues.append(res)
7 dataset = pd.DataFrame(jvalues)
8 OutputDataSet=dataset
The shorter version of the above script, can look like this:
jvalues = []
for val in cnt["aggregations"]["by_country_name"]["buckets"]:
jvalues.append(dict([("key", val["key"]),("total", int(val["doc_count"]))]))
OutputDataSet= pd.DataFrame(jvalues)
Finally, we will use the WITH RESULT SETS clause to add proper column names to the output resultset. Note that second column datatype is integer and if you will define wrong datatype you will get an error.
WITH RESULT SETS ((country_name varchar(50), doc_count int))
Bringing it all together:
exec sp_execute_external_script
@language =N'Python',
@script=N'
from elasticsearch import Elasticsearch
import pandas as pd
es = Elasticsearch(hosts=["servername"], request_timeout=100, timeout=100)
cnt = es.search(index="history_data", body="""{"query": {
"range" : {
"report_date" : {
"gte": 20160101,
"lte": 20180819
}
}
},
"aggs" : {
"by_country_name" : {
"terms" : {
"field" : "country_name",
"size" : 100
}
}
},
size:0
}""")
print (cnt)
jvalues = []
for val in cnt["aggregations"]["by_country_name"]["buckets"]:
res = {}
res["key"] = val["key"]
res["total"] = int(val["doc_count"])
jvalues.append(res)
dataset = pd.DataFrame(jvalues)
OutputDataSet=dataset
'
WITH RESULT SETS ((country_name varchar(50), doc_count int))
Let’s look again at the messages tab where we have printed the raw results that we got from Elasticsearch:
It took SQL Server 6 seconds to connect to Elasticsearch, Elasticsearch scanned, filtered and aggregated 62,722,458 documents (rows) and returned the result back to SQL Server. Isn’t it amazingly fast?
The Elasticsearch cluster that I have used for this query is a small 2 node cluster, each has 8CPUs and 32GB of memory.
Next Steps

Maria Zakourdaev is a Data Platform Microsoft MVP and a technology expert with more than 20 years of experience, a community leader with a profound knowledge of Microsoft products and services, while also being able to bring together diverse platforms, products, and solutions to solve real-world problems.
Maria has a hands-on experience managing various data management technologies in Azure, AWS and Google public cloud platforms, including SQL Server, Azure CosmosDB, AWS DynamoDB, MemSQL, MySQL, Postgresql, Snowflake, Redis, Amazon Redshift, Couchbase and Elasticsearch, Spark, Databricks, Big Query.
Maria is an organiser of the annual conference “Data TLV” ( ex “SQL Saturday Israel”), a free training event for any data professionals: http://datatlv.com.
- MSSQLTips Awards: Trendsetter (25+ tips) – 2022 | Author Contender – 2022 | Rookie Contender – 2018


