Problem
I have some curated datasets, whether a SQL Server table or a CSV dump. I want to analyze the data by making a dataset profile. Additionally, I want to have the option to manage columns and data types or perform other data transformation activities. Each operation uses a script that allows parameterization and results display.
Solution
While Power BI can help with this scenario, this tip will focus on reading and profiling data with the pandas package. Profiling, aka exploratory data analysis, provides a good overview of the dataset, uncovers basic dependencies, and suggests what features to focus on in a more in-depth analysis.
Environment Setup
Let’s start by creating a new conda environment. Start the anaconda prompt from the start menu and run:
conda create -n MSSQL_Tips_pandas pandas pandas-profiling

The new environment is called “MSSQL_Tips_pandas” with the latest Python version and adds the pandas and pandas-profiling packages. For more information, please refer to the conda documentation and my previous tip, How to Get Started Using Python using Anaconda, VS Code, Power BI and SQL Server.
Command execution may take up to several minutes, during which the target packages and package dependencies will be resolved and installed. After completion, you can start VS code. Open the target directory and create a new file with the .ipynb extension in the working directory. This file will be a Jupiter notebook. Make sure to select the correct environment from the top right-hand corner of the interface:

Package Import
Next, you can import the target packages, and you will even get suggestions on package names as you type:

Note: depending on the pandas version used, you may get an error:
'ImportError: cannot import name 'ABCIndexClass' from 'pandas.core.dtypes.generic'
You either need to downgrade your pandas package or follow the solution in this thread here.
Load CSV
For this tip, we are using an open dataset containing total trade data per year per country. You can find and download it from the EU open data portal here. The second order of business is to read it into a pandas dataframe. There is an extensive documentation page on the read_csv method here, so it can be left to the reader to explore the different options. For our purposes here, we need to add just one additional argument, the encoding option:
df = pd.read_csv(r'14.TOTAL-TRADE_YEAR_2020.csv',
encoding='latin-1')

Alternatively, you can connect directly to an SQL instance and have the data read from a single table or a more complex query into a pandas dataframe. Check my previous tips on how to do so.
Pre-processing
Before profiling, check if pandas has correctly parsed the column datatypes. In some cases, this happens automatically, but not always. You can check the data types by running df.dtypes:

There are a couple of issues here. First, the PERIOD values should be explicitly cast to a date type. Second, VALUE USD should be a float. Additionally, if you notice from the preview, there are two more issues: QUANTITY KG appears to be in a scientific notation, which is hard to read. And the thousands separator (comma) will prevent VALUE USD from being converted to float successfully. Let’s resolve these issues.
First, run this pandas command to change the float display format globally for the whole notebook:
pd.set_option('display.float_format', lambda x: '%.2f' % x)
Next, replace the comma thousands separator with an empty string:
df['VALUE USD'] = df['VALUE USD'].str.replace(',', '')
Finally, cast the columns to the correct datatypes. Use the astype method, which accepts a dictionary. The keys represent the column names and the values – the target pandas datatypes as string:
df = df.astype({'PERIOD':'datetime64','VALUE USD':'float64'})
Here is the result:

Simple Profiling
The simplest way to profile your dataset is to use the pandas describe method. By default, calling the method with no parameters will include only the numeric type columns. The result is a dataframe containing information on the count, mean, standard deviation, min, max, and the quartiles:
df.describe()
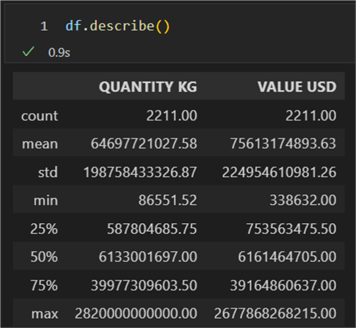
If you call the method by explicitly including all columns, you will get extra information on the categorical data types. The extra descriptors are count, unique, top, and freq. The top is the most frequently occurring value. The freq is that value’s frequency. Timestamps also include the first and last items.

Beware of dataframes with large dimensionality (e.g., hundreds of columns and millions of rows). Either select only the relevant columns or be computationally prepared.
Extensive Profiling
For a more detailed profile of the target dataset, we must use the additional package pandas profiling. You need a profile object first, with arguments, the dataframe variable, and a name for the report:
profile = ProfileReport(df, title="Export Data Profiling Report")
There are two options to display the results:
- profile.to_widgets(): renders an interactive widget, or
- profile.to_notebook_iframe(): creates an embedded HTML page.
For example:

Overview
The overview provides a high-level summary of the dataset, including the number of columns (variables), rows (observations), missing and duplicate values, and some memory information.
Variables
In the Variables section, there is a complete breakdown of each column’s values. For example, let’s check out the VALUE USD and click Toggle details:

Since some of the max values are in the trillions, they are represented with scientific notation. Additionally, to the descriptive part (shown above), there is also a histogram and information on common and extreme values.
Interactions
This section produces a scatter plot to describe how the numerical values interact. This plot is a bit misleading in this case due to some outliers in VALUE USD.

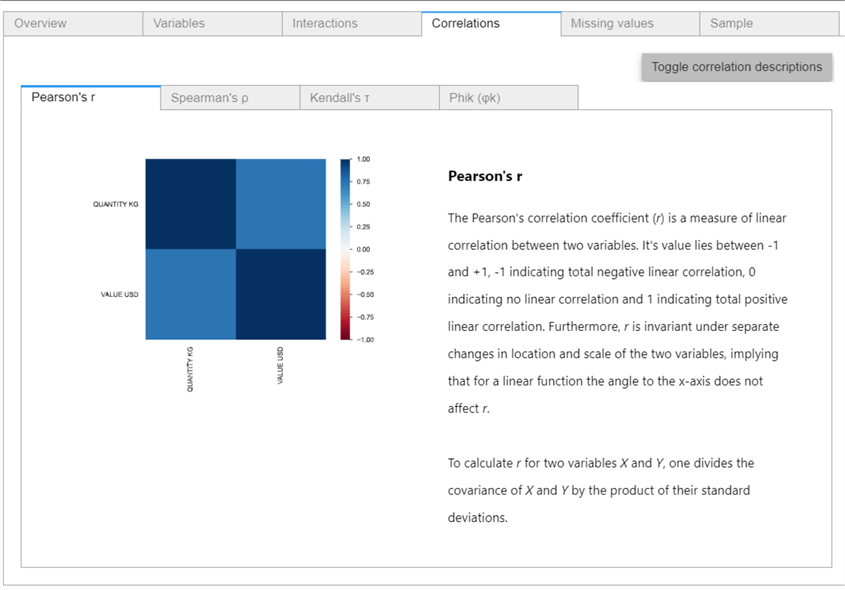
Correlations
This tab provides different correlation coefficients. In this case, there is a high positive correlation between the quantity in Kg and the Value in USD. The more is exported or imported, the higher the value:
Missing values
This section shows an overview of missing values. Here there are no missing values present.

Sample
Finally, the last tab shows the first ten and last ten rows of the dataframe. Note you should explicitly sort the dataframe by a specific column before checking the sample tab if you expect to see the results in a particular order.

Custom Profiling
Exploratory data analysis
Finally, let us examine how to do exploratory data analysis without pandas profiling. Let’s do a quick example by focusing on the numerical columns only. For example, we can develop a method that takes as input a dataframe with only numerical columns. For each column, we will compute the statistic we are interested in:
def get_basic_profile(dataframe):
quantile_range = 0.5
results = {}
for column in dataframe.columns:
count = df[column].count()
nans = df[column].isna().sum()
min = df[column].min()
max = df[column].max()
median = df[column].median()
std = df[column].std()
kurt = df[column].kurt()
skew = df[column].skew()
quant = df[column].quantile(q=quantile_range)
results[column] = {'count': count,
'count_na': nans,
'min':min,
'max':max,
'median':median,
'std':std,
'kurt':kurt,
'skew':skew,
f'quant {quantile_range}':quant}
return results
Running the function outputs the following results:

Histogram
As part of your custom profiling, getting a histogram of the numerical variables is helpful. The histogram is a handy plot showing an overview of the data distribution. Here is an example of how to quickly come up with a histogram for the data:
import numpy as np
import matplotlib.pyplot as plt
#square root choice
bins = int(np.ceil(np.sqrt(len(num_columns['VALUE USD']))))
fig, ax = plt.subplots(1, 1, figsize=(14,8))
ax.hist(num_columns['VALUE USD'], bins)
ax.ticklabel_format(useOffset=False, style='plain')
ax.set_xlabel('Value USD')
ax.set_ylabel('Count')
ax.set_title(r'Histogram of exports in USD')
First, you need to import the numpy and matplotlib packages. Then you can calculate how many bins must be plotted on the histogram. Matplotlib can do this automatically, or you can calculate as explained here (and shown above). Then we need a figure and an ax objects, which we will use for the plotting. On the ax object, you can then call the hist() method passing the numerical series of values and the amount of bins. Finally, several options can be set to make the histogram more informative, such as labels and a title. Here is the result:

What can we infer based on this plot? First, there are several extremely high values. If you check the dataframe you will see that the highest USD values represent the USA and China trade volumes. Second, most of the values are concentrated below the quarter trillion mark. These findings suggest that for further analysis, a) we should probably exclude the extreme values and b) see how to partition the data by a representative amount of export-import activity because this original distribution is severely right-skewed.
Conclusion
This tip showcases how to perform fundamental exploratory data analysis. On one hand, we have the built-in pandas methods, and on the other the pandas-profiling specialized package. Additionally, we can construct our own methods to describe the data, as well as a histogram to examine visually the distribution of target variables.
Next Steps

Hristo Hristov is a seasoned data professional with 10+ years of experience spanning the intersection of data engineering and smart manufacturing solutions. Since 2017, he has specialized in implementing advanced analytics solutions for bridging the IT/OT gap.
A technical writer with over 80 published articles on data and AI technologies, Python development, and cloud solutions. Passionate about transforming complex data into business value through innovative applications of Azure Data Platform, Python, IoT solutions, databases, and other cloud technologies.
Currently applying Industry 4.0 best practices, focusing on IoT connectivity, and implementing data and AI systems in manufacturing. Hristo holds a degree in Data Science and several Microsoft certifications covering SQL Server, Power BI, and related technologies.
- MSSQLTips Awards
- Achiever Award (75+ tips) – 2026
- Rookie of the Year – 2021
- Author Contender – 2022/2023/2024/2025



Please note the pandas-profiling package has been changed to ydata-profiling. The updated documentation is available at https://docs.profiling.ydata.ai/latest/