Problem
Python is easy to learn, read, and use [1]. IT professionals who have an interest in Python programming can learn the basics quickly. Some practice problems in programming tutorials are simple. We can picture how to use several lines of code to solve these problems. However, practical problems at work usually are not trivial. Some of us may not know how to start; others may write code almost immediately. If we rush to the keyboard without a program design, we may quickly write a large amount of code, but later discover that large portions of the code are unnecessary. These issues emphasize the importance of program design. People who are new to Python programming want to learn a program design approach.
Solution
The top-down design approach, also called stepwise refinement, is essential to developing a well-structured program [2]. This approach is a problem-solving technique that systematically breaks a complicated problem into smaller, more manageable pieces. If any of these subproblems is not easier to solve, we further divide the subproblem into smaller parts. We repeat the subdividing process until all small parts are not dividable. Then, we can use a few lines of code to solve every trivial problem. In the end, we put all these little pieces together as a solution to the original problem. This approach makes it easy to think about the problem, code the solution, read the code, and identify bugs.
To demonstrate how to apply the top-down approach to design a program, we tackle a real-world problem:
- We work in the IT department of a manufacturing company. The company web site provides an email address that collects questions and comments from visitors. Customer relationship managers want to extract all email messages into a SQL server database for data mining.
We adopt the top-down design approach to create a tree-like structure chart. Then, we implement this design by refining all tasks at nodes into Python code. I organize the remaining sections of this tip as follows: Section 1 introduces the top-down design approach. We prepare for a development environment in Section 2. In Section 3, we walk through a five-step procedure to perform the top-down design. Finally, the summary section wraps up this tip.
I tested code used in this tip with Microsoft Visual Studio Community 2019 and Python 3.7(64-bit) on Windows 10 Home 10.0 <X64>. The DBMS is Microsoft SQL Server 2017 Enterprise Edition (64-bit).
1 – Introducing the Top-Down Design
The top-down design approach is to produce a plan for solving a complicated problem. The output of this design is a tree-like structure chart, shown in Figure 1.

Figure 1 A Tree-like Structure Chart
The root is the entry point of the program. The first level contains several major subtasks. These subtasks work together to solve the initial problem. If a subtask is not trivial at the first level, we divide it into smaller tasks, and then we place all these smaller tasks at the second level. This process continues until we reach a level at which breakdown is not necessary. There are several levels between the root and leaves. At each level, the dividable subtasks reference subtasks at the lower level. We define interfaces (or signatures) of these subtasks to communicate with other subtasks at the different levels. We use the following procedure to walk through the top-down design [3]:
- Start with an initial problem statement.
- Define subtask at the first level.
- Divide subtasks at a higher level into more specific tasks.
- Repeat step (3) until each subtask is trivial.
- Refine the algorithm into real code.
The program that implements the top-down design reflects the quality code's characteristics: readable, extendable, extensible, and debuggable [4]. Because of descriptive names of functions and variables, and human-readable syntax, people who do not know Python language may infer what the program is doing. When we have new requirements, we can add a piece of code without modifying existing functions. If we find the program does not work correctly, we only need to run suspicious functions to locate the problematic function. Besides, this program allows other people to improve one function without touching code in other functions.
Top-down design and object-oriented programming (OOP) can co-exist [5]. The top-down design approach answers a question about how to start tackling a complicated problem. However, the top-down design approach has some limits [6]. If we do not divide a task into several independent subtasks carefully, we may face a challenge when implementing those subtasks at the lower levels.
2 – Preparing for a Development Environment
It this exercise, we read Emails from a Gmail account and then save them into a SQL Server database table. To prepare for running the Python program, we should enable IMAP access to the Gmail account and create a database table. It is worth noting that we change the Email account setting for demo. The change put the Google account on security risk.
2.1 Configuring the Gmail Account
We use the built-in Python module, imaplib [7], to read new emails from a Gmail account. A Gmail account with the default configuration does not allow other clients to access using IMAP. We should make the following changes so that our Python program can access the Gmail box:
1. Log into Google account, and click on the “Manage your Google Account” button. The portion of the Google Account page should look like Figure 2. Click on the “Security” menu item.

Figure 2 Google Account Management
2. On the security page, scroll down to the section “Less secure app access” and click on the “Turn on access (not recommended)” link to turn on less secure app access, as shown in Figure 3.

Figure 3 Turn on Less Secure App Access
3. Access the Gmail box, and go the setting page. Switch to the “Forwarding and POP/IMAP” tab and find the “IMAP access” section. Select the “Enable IMAP” option, as shown in Figure 4.

Figure 4 Gmail Account IMAP Access Setting
2.2 Creating a Database Table
We adopt the extract-to-stage design pattern that decouples the extract from the transformation and load [8]; therefore, we create a staging table to store email messages extracted from a Gmail account. Besides necessary columns for email messages, we add some audit information even though we perform a simple ETL process. The following SQL script creates the staging table:
CREATE TABLE [dbo].[GmailMessage]( [MessageId] NVARCHAR(256) NOT NULL, [FromUserName] NVARCHAR(50) NOT NULL, [FromEmail] NVARCHAR(50) NOT NULL, [DateReceived] DATETIME NOT NULL, [Subject] NVARCHAR(256) NOT NULL, [Content] NVARCHAR(MAX) NOT NULL, [DateImported] DATETIME NOT NULL, [ImportedBy] NVARCHAR(50) NOT NULL, [ImportBatchId] INT NOT NULL, [DateUpdated] DATETIME NULL, [UpdatedBy] NVARCHAR(50) NULL, [DateCleansed] DATETIME NULL, [CleansedBy] NVARCHAR(50) NULL, [AuditStatus] NVARCHAR(20) NOT NULL, CONSTRAINT [PK_GmailMessage] PRIMARY KEY CLUSTERED([MessageId] ASC) )
3 – Performing the Top-Down Design
Every activity we perform at work is in response to business needs [9]. Programmers should write programs to satisfy business requirements. Before designing a program, we should perform a business requirement analysis.
From the business requirement analysis, we can define an initial problem statement for the top-down design. Then, we divide the initial problem into several general tasks at the first level in the tree-like structure. Next, we break each dividable task into more specific tasks. This process repeats until we can use several lines of code to implement each subtask. In the end, we put all these little pieces together to solve the initial problem.
3.1 Starting with an Initial Problem Statement
The first step is to perform business analysis and understand what the specifications are asking. Then, we can define an initial problem statement for the design:
- Read new emails from an email box and save email messages into a database table.
3.2 Defining Subtasks at the First Level
Every Python function written in this exercise adopts the input-process-output pattern, a widely used approach in systems analysis and software engineering, to describe a problem-solving process [10]. The input-process-out pattern includes these three steps: (1) Get input, (2) Process, and (3) Output. We should also choose descriptive function names; consequently, others can easily understand the program [11]. When a program can clearly express our intent, we do not need to add comments to the program very much [12].
Since Python’s syntax is human-readable, we directly use Python code to express these subtasks. The main() function, the program’s entry point, is the root of the structure chart. We breakdown the initial problem statement into two general subtasks:
# The root
def main():
emailMessages = extractEmailMessages()# subtask at level 1
stageEmailMessages(emailMessages) # subtask at level 1
We have decomposed the original problem into two independent subtasks. This decomposition process breaks a complex problem into small parts that are easier to conceive, understand, program, and maintain. We do not need to worry about the detailed definitions of these subtasks in this step. We assume that all the subtasks work correctly, and we use them to solve the initial problem. We also call this process abstraction.
We can visualize this step with the tree-like structure chart; each task in the design is a rectangle. An arrow connecting two rectangles indicates that the one at a higher level uses the one below. We use Python functions to implement these subtasks.
A Python function usually has a name, arguments, and an expected return value. We call this information the interface or signature of the function. To add more information to the chart, we place arguments and return value along the edges. The chart produced from this step should look like Figure 5.

Figure 5 The First Level of the Tree Structure
Since we extract email messages from an email server and then load these messages into a SQL server database, we can store email messages into a list of dictionaries. The keys in the dictionary correspond to columns in the database table.
3.3 Dividing Subtasks at the Higher Level into More Specific Tasks
If any task at a higher level is trivial (i.e., indivisible), we can create a prototype of this function to implement the task, and we do not further divide the task. However, these two tasks at a higher level are still complicated. We break them into six smaller tasks expressed by Python code:
# Level 1 def extractEmailMessages(): emailConn = createEmailConnection() # subtask at level 2 emailMessages = extractNewEmails(emailConn) # subtask at level 2 closeEmailConn(emailConn) # subtask at level 2 return emailMessages def stageEmailMessages(emailMessages): dbConn = createDBConnection() # subtask at level 2 InserDataIntoDB(dbConn,emailMessages) # subtask at level 2 closeDBConnection(dbConn) # subtask at level 2
We add the level 2 to the tree-like structure chart, and the chart should look like Figure 6.

Figure 6 The Second Level of the Tree Structure
After abstraction, the complicated task is no longer a complicated thing to do. The task “closeEmailConn,” “createDBConnection,” and “closeDataConn” are trivial, and therefore we do not subdivide these subtasks further. We create prototypes of these three functions:
# Level 2 def closeEmailConn(emailConn): emailConn.close() def createDBConnection(): server ='yourDBServerName' database ='yourDBName' dbConn =pyodbc.connect(Driver="{SQL Server}",Server=server,Database=database,Trusted_Connection="Yes") return dbConn def closeDBConnection(dbConn): dbConn.close()
The prototypes are a stripped-down version of real functions. We do not need to make them meet full specifications in this step.
3.4 Repeat Step (3) Until Each Subtask is Trivial
Level 2 includes these complicated subtasks: “createEmailConnection”, “extractNewEmails”, and “InserDataIntoDB”. We continue to apply the input-process-out pattern to write these functions.
1. Break down the tasks at level 2 and then put subtasks at level 3
# Level 2 def createEmailConnection(): host = 'imap.gmail.com' emailConn = imaplib.IMAP4_SSL(host) loginEmailAccount(emailConn) # subtask at level 3 return emailConn def extractNewEmails(emailConn): newRawEmails = searchNewEmails(emailConn) # subtask at level 3 listDictEmailMessages = parseEmailRawData(emailConn, newRawEmails)# subtask at level 3 return listDictEmailMessages def InserDataIntoDB(dbConn,emailMessages): cursor = dbConn.cursor() sqlStatement = constructSQLStatement(emailMessages) # subtask at level 3 cursor.execute(sqlStatement) dbConn.commit()
The updated structure chart should look like Figure 7.

Figure 7 The Third Level of the Tree Structure
The task “loginEmailAccount” and “searchNewEmails” are trivial, and we do not break them further. We create prototypes of these three functions [13]:
# Level 3 def loginEmailAccount(emailConn): emailConn.login('yourAccount@gmail.com','yourPWD') emailConn.select() def searchNewEmails(emailConn): _, newEmails = emailConn.search(None, 'UnSeen') return newEmails
2. Break down the tasks at level 3 and then put subtasks at level 4
For the sake of demonstration, we use real Python code to express these subtasks. Using real code is not necessary. If we know a task is simple, but we do not know how to write Python code, we can use pseudo-code to implement this task. We place our focus on design in this step, and we can ignore all detailed implementations.
# Level 3 def constructSQLStatement(emailMessages): insertRows = list() sqlStatement = '''INSERT INTO [dbo].[GmailMessage] ([MessageId] ,[FromUserName] ,[FromEmail] ,[DateReceived] ,[Subject] ,[Content] ,[DateImported] ,[ImportedBy] ,[ImportBatchId] ,[AuditStatus]) VALUES {}''' for dictEmailMessage in emailMessages: insertRows.append(extractValuesFromDict(dictEmailMessage))# subtask at level 4 values = ', '.join(map(str, insertRows)) return sqlStatement.format(values).replace('"',"'") def parseEmailRawData(emailConn, newEmails): rtnValue = list() for emailID in newEmails[0].split(): _, emailData = emailConn.fetch(emailID, '(RFC822)') for part in emailData: if isinstance(part, tuple): dictEmail = readEmailDataToDict(part) # subtask at level 4 rtnValue.append(dictEmail) return rtnValue
The updated the chart should look like Figure 8:
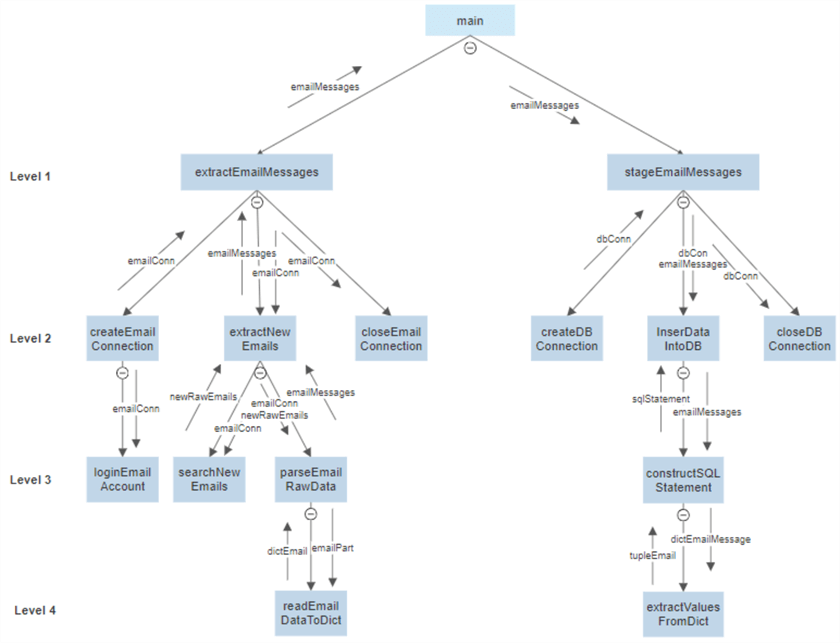
Figure 8 The Fourth Level of the Tree Structure
The task “extractValuesFromDict” is trivial, and we do not divide it further. When we insert multiple rows into the database using Python, we construct a list of tuples. Each tuple in the list contains values of a data row. Thus, this function should return a tuple. We create a prototype of this function:
def extractValuesFromDict(dictEmailMessage): rtnValue = list() rtnValue.append(dictEmailMessage['MessageId']) rtnValue.append(dictEmailMessage['FromUserName']) rtnValue.append(dictEmailMessage['FromEmail']) rtnValue.append(dictEmailMessage['DateReceived']) rtnValue.append(dictEmailMessage['Subject']) rtnValue.append(dictEmailMessage['Content']) rtnValue.append(dictEmailMessage['DateImported']) rtnValue.append(dictEmailMessage['ImportedBy']) rtnValue.append(dictEmailMessage['ImportBatchId']) rtnValue.append(dictEmailMessage['AuditStatus']) return tuple(rtnValue)
3. Break down the tasks at level 4 and then put subtasks at level 5
It is not necessary to use precise Python syntax to implement functions at this step. For example, if we do not know the function to get the received date of an email from raw email data, we can use a pseudo function such as get_email_received_date(). We replace this function with a real Python function later. If we do not find a Python function to replace the pseudo function, this pseudo function becomes a subtask.
# Level 4 def readEmailDataToDict(emailPart): rtnValue = dict() emailMessage = email.message_from_bytes(emailPart[1]) emailBody = extractEmailBody(emailMessage) # subtask at level 5 rtnValue['MessageId'] = emailMessage['Message-ID'] rtnValue['FromUserName'], rtnValue['FromEmail'] = email.utils.parseaddr(emailMessage['from']) rtnValue['DateReceived'] = get_email_received_date() # pseudo function rtnValue['Subject'] = emailMessage['subject'] rtnValue['Content'] = emailBody.decode().replace("'","''") rtnValue['DateImported'] = datetime.datetime.now().strftime("%Y-%m-%dT%H:%M:%S") rtnValue['ImportedBy'] = 'Python' rtnValue['ImportBatchId'] = int(datetime.datetime.now().strftime("%H%M")) rtnValue['AuditStatus'] = 'Extract' return rtnValue
The updated the chart structure looks like Figure 9:

Figure 9 The Fifth Level of the Tree Structure
At level 5, the subtask becomes trivial, and further decomposition is not needed. We create the prototype for the subtask:
# Level 5 def extractEmailBody(oneEmailData): return 'Email Body'
3.5 Refining Algorithm into Real Code
In the previous steps, we focused on program design. We used code to express the design, but some code may be written more or less in pseudocode. We should get all code to meet full specifications in this step. Commonly, we may face a challenge to implement a task. If this situation occurs, we should go back to check the design.
The implementation uses the bottom-up approach. That means we should start at the lowest levels of the structure, then move upward. We should test each function when we complete code implementation. Testing in this manner is called unit testing, which can spot errors immediately. Here is the final version of this program:
import imaplib import pyodbc import email import datetime # The root def main(): emailMessages = extractEmailMessages() # subtask at level 1 stageEmailMessages(emailMessages) # subtask at level 1 # Level 1 def extractEmailMessages(): emailConn = createEmailConnection() # subtask at level 2 emailMessages = extractNewEmails(emailConn) # subtask at level 2 closeEmailConn(emailConn) # subtask at level 2 return emailMessages def stageEmailMessages(emailMessages): dbConn = createDBConnection() # subtask at level 2 InserDataIntoDB(dbConn,emailMessages) # subtask at level 2 closeDBConnection(dbConn) # subtask at level 2 # Level 2 def closeEmailConn(emailConn): emailConn.close() def createDBConnection(): server = 'yourServerName' database = 'yourDBName' dbConn = pyodbc.connect(Driver="{SQL Server}",Server=server,Database=database,Trusted_Connection="Yes") return dbConn def closeDBConnection(dbConn): dbConn.close() # Level 2 def createEmailConnection(): host = 'imap.gmail.com' emailConn = imaplib.IMAP4_SSL(host) loginEmailAccount(emailConn) # subtask at level 3 return emailConn def extractNewEmails(emailConn): newRawEmails = searchNewEmails(emailConn) # subtask at level 3 listDictEmailMessages = parseEmailRawData(emailConn, newRawEmails)# subtask at level 3 return listDictEmailMessages def InserDataIntoDB(dbConn,emailMessages): cursor = dbConn.cursor() sqlStatement = constructSQLStatement(emailMessages) # subtask at level 3 if sqlStatement != None: cursor.execute(sqlStatement) dbConn.commit() # Level 3 def loginEmailAccount(emailConn): emailConn.login('yourAccount@gmail.com', 'yourPWD') emailConn.select() def searchNewEmails(emailConn): _, newEmails = emailConn.search(None, 'UnSeen') return newEmails def constructSQLStatement(emailMessages): insertRows = list() sqlStatement = '''INSERT INTO [dbo].[GmailMessage] ([MessageId] ,[FromUserName] ,[FromEmail] ,[DateReceived] ,[Subject] ,[Content] ,[DateImported] ,[ImportedBy] ,[ImportBatchId] ,[AuditStatus]) VALUES {}''' for dictEmailMessage in emailMessages: insertRows.append(extractValuesFromDict(dictEmailMessage))# subtask at level 4 values = ', '.join(map(str, insertRows)) if len(insertRows) == 0: return None else: return sqlStatement.format(values).replace('"',"'") def parseEmailRawData(emailConn, newEmails): rtnValue = list() for emailID in newEmails[0].split(): _, emailData = emailConn.fetch(emailID, '(RFC822)') for part in emailData: if isinstance(part, tuple): dictEmail = readEmailDataToDict(part) # subtask at level 4 rtnValue.append(dictEmail) return rtnValue # Level 4 def readEmailDataToDict(emailPart): rtnValue = dict() emailMessage = email.message_from_bytes(emailPart[1]) emailBody = extractEmailBody(emailMessage) # subtask at level 5 rtnValue['MessageId'] = emailMessage['Message-ID'] rtnValue['FromUserName'], rtnValue['FromEmail'] = email.utils.parseaddr(emailMessage['from']) rtnValue['DateReceived'] = email.utils.parsedate_to_datetime(emailMessage['Date']).strftime("%Y-%m-%dT%H:%M:%S") rtnValue['Subject'] = emailMessage['subject'] rtnValue['Content'] = emailBody.decode().replace("'","''") rtnValue['DateImported'] = datetime.datetime.now().strftime("%Y-%m-%dT%H:%M:%S") rtnValue['ImportedBy'] = 'Python' rtnValue['ImportBatchId'] = int(datetime.datetime.now().strftime("%H%M")) rtnValue['AuditStatus'] = 'Extract' return rtnValue def extractValuesFromDict(dictEmailMessage): rtnValue = list() rtnValue.append(dictEmailMessage['MessageId']) rtnValue.append(dictEmailMessage['FromUserName']) rtnValue.append(dictEmailMessage['FromEmail']) rtnValue.append(dictEmailMessage['DateReceived']) rtnValue.append(dictEmailMessage['Subject']) rtnValue.append(dictEmailMessage['Content']) rtnValue.append(dictEmailMessage['DateImported']) rtnValue.append(dictEmailMessage['ImportedBy']) rtnValue.append(dictEmailMessage['ImportBatchId']) rtnValue.append(dictEmailMessage['AuditStatus']) return tuple(rtnValue) # Level 5 def extractEmailBody(oneEmailData): if oneEmailData.is_multipart(): return extractEmailBody(oneEmailData.get_payload(0)) else: return oneEmailData.get_payload(None,True) if __name__ == "__main__": main() print("The program ran successfully!")
Using the top-down design approach, we create 16 functions, and each function performs a specific task. If the program goes wrong, we can quickly locate bugs and fix them. We do not need to go through the entire program to discover bugs. This benefit reflects a quality software criterion, maintainability, which is the software's suitability for ease of locating and fixing a fault in the implementation [14].
Summary
We used the top-down design approach to solve the real-world problem. The top-down design approach uses the divide-and-conquer algorithm that expresses a complex problem in terms of small, simple problems.
We started at the first level in the tree-like structure chart and then worked way down to lower levels. At each level, we broke down a general task to several smaller, more straightforward subtasks. Through this approach, the complicated task is no longer a complicated thing to perform.
Tasks at a higher level may call their subtasks. The interface of a function served as a contract to connect the caller and callees. We immediately produced prototypes to implement subtasks that are not dividable.
The last step of this approach is to refine all algorithms into a real Python program. We adopted the bottom-up implementation method. Following this method, we started code implementation and unit testing at the lowest levels of the tree-like structure and then moved upwards.
References
[1] Ekenes, K. (2017). Why Python is Perfect for Beginners. Retrieved from Coding DOJO: https://www.codingdojo.com/blog/python-perfect-beginners.
[2] Deitel, J. P. & Deitel, H. (2017). Java How to Program, Early Objects (11th Edition). New York, NY: Pearson
[3] Myers, B. (2011). Stepwise Refinement (Example). Retrieved from Florida State University: https://www.cs.fsu.edu/~myers/c++/notes/stepwise.html.
[4] Att, E. (2017). How to start writing high quality code at any point of your programming journey. Retrieved from Medium: https://medium.com/the-andela-way/how-to-start-writing-high-quality-code-at-any-point-of-your-programming-journey-d434cb0ba8ca.
[5] James, M. (2017). In Praise of Top Down Programming. Retrieved from I Programmer: https://www.i-programmer.info/professional-programmer/i-programmer/3864-in-praise-of-top-down-.html.
[6] Kornee, A. (2017). How and Why Does Top-Down Programming Work? Retrieved from DZone: https://dzone.com/articles/how-does-top-down-programming-work.
[7] Python Software Foundation. (2020). imaplib — IMAP4 protocol client. Retrieved from python.org: https://docs.python.org/3/library/imaplib.html.
[8] Thornthwaite, W., Kimball, R. & Mundy, J. (2011). The Microsoft® Data Warehouse Toolkit: With SQL Server 2008 R2 and the Microsoft® Business Intelligence Toolset, Second Edition. Indianapolis, IN: Wiley.
[9] Mind Tools Content Team. (2019). Business Requirements Analysis. Retrieved from MindTools: https://www.mindtools.com/pages/article/newPPM_77.htm.
[10] Braunschweig, D. (2018). Input-Process-Output Model. Retrieved from Rebus Community: https://press.rebus.community/programmingfundamentals/chapter/input-process-output-model/.
[11] Stueben, M. (2018). Good Habits for Great Coding: Improving Programming Skills with Examples in Python. Falls Church, VA: Apress.
[12] Martin, C. R. (2008). Clean Code. Crawfordsville, IN: Prentice Hall.
[13] Jay. (2017). How to Read Email from Gmail Using Python. Retrieved from CODE HANDBOOK: https://codehandbook.org/how-to-read-email-from-gmail-using-python/
[14] Plosch, R. (2004). Contracts, Scenarios and Prototypes: An Integrated Approach to High Quality Software. Berlin, German: Springer-Verlag
Next Steps
- The examples used in this tip are for demonstration only. There is much room for improvement. When we present this program to others who do even not know Python language, if they can infer this program's purpose, we think this program is readable. We do not expect to rely on comments to explain the code. When we complete the program, someone asks us to add new features such as downloading email attachments. We can add a new piece of code to the program without changing any existing features; that is, this program is extendable. When other people only want to enhance one function, such as adding error handling in the function "InserDataIntoDB," they can improve the function without affecting other functions. We say this program is extensible. When the program does not work as we expected, we can test the piece of code that possibly causes the error. If we can quickly locate bugs, this program is debuggable. We can practice writing high-quality code using the sample code in this tip as a start point.
- Check out these related tips:

Nai Biao Zhou has twenty years of experience in software development, with strong analytical skills and a broad range of computer expertise.
He has fifteen years of experience in development and maintenance of database applications on SQL Server in OLTP/OLAP/BI environments.
He has a master’s degree in Control Engineering and is pursuing a Master of Science degree in Predictive Analytics.
Knowledge/Skills
Advanced computer programming skills and well versed with C/C#, Java, ASP.NET, JavaScript, and SQL.
In depth knowledge of Solution Architecture, and Software Development Life Cycle (SDLC).
Microsoft Certified Application Developer (MCAD) since 2004.
- MSSQLTips Awards: Author of the Year – 2021 | Rising Star (50+ tips) – 2024 | Author Contender – 2020, 2023


