Problem
Kubernetes is an open-source orchestration and management system for containers. It is an exciting technology to learn once you begin to embrace the cloud platforms. As a DBA, how should you leverage running SQL Servers on containers and deploying them to Kubernetes?
For this tip, we will discuss the different considerations before you begin deploying your SQL Servers images in Kubernetes.
Solution
How does Kubernetes work?
Kubernetes is mainly an orchestration tool. You might say you have hundreds of containers running applications and databases. Kubernetes offers a highly scalable, reliable control plane to run these containers. Many SQL Server container images have been published and made public some years back. One very popular container repository is the Docker hub site.
Key Benefits of Running SQL Server in Containers
Here is a great tip that explains the containers for SQL Servers on Windows and Linux. One of the key benefits of having images of SQL Servers on containers is that you skip the installation and configuration part. Basically, you have an image of your database server and its run and availability is orchestrated by the Kubernetes Cluster.
Inside the Kubernetes Cluster, there is a control plane that manages and orchestrates the nodes, which in turn is running the pods. Pods are where your SQL Server container is running and your data and logs are sitting on persistent volumes under the hood.
Ideally, when considering if running SQL Servers in Kubernetes is appropriate for your use case, make sure to test and deploy with a POC or staging environment. Make sure to understand the gears that are running behind the scenes. Understand what happens when the pods, where your SQL container is, die, the data loss acceptable and storage configurations. Here is a good link on SQL internals for containers.
Deploying SQL Container in Azure Kubernetes Cluster
For this tip, I will share how to deploy an empty SQL Server running on Linux to an Azure Kubernetes Cluster. An existing Azure Kubernetes Cluster is required for this tip. If you do not have yet a running Azure Kubernetes Cluster, you can start to create one here.
Once you have a running AKS, connect to it via PowerShell or Azure CLI. To connect to AKS via Azure CLI use the following:
az account set --subscription <subscriptionguid> az aks get-credentials --resource-group <resourcegroupname> --name <kubernetes cluster name>
Also proceed to install kubectl via PowerShell or Azure CLI. Kubectl is the PowerShell command to manage your AKS. To setup kubectl on your server you can do this with these two options below.
Via PowerShell:
Install-Script -Name 'install-kubectl' -Scope CurrentUser -Force

Or via CMD Window if you already have curl:
curl -LO https://dl.k8s.io/release/v1.20.0/bin/windows/amd64/kubectl.exe


First we create the SA password, the SQL login we need to connect to SQL Server after we deploy it. Make sure to make it a bit complex and keep it where you can retrieve for connecting later.
.\kubectl create secret generic mssql --from-literal=SA_PASSWORD=”yourpassword” --namespace=”database”
To validate that our secret mssql password is created, we run the .\kubectl describe secret. The parameter –namespace is optional if you have not created a namespace.
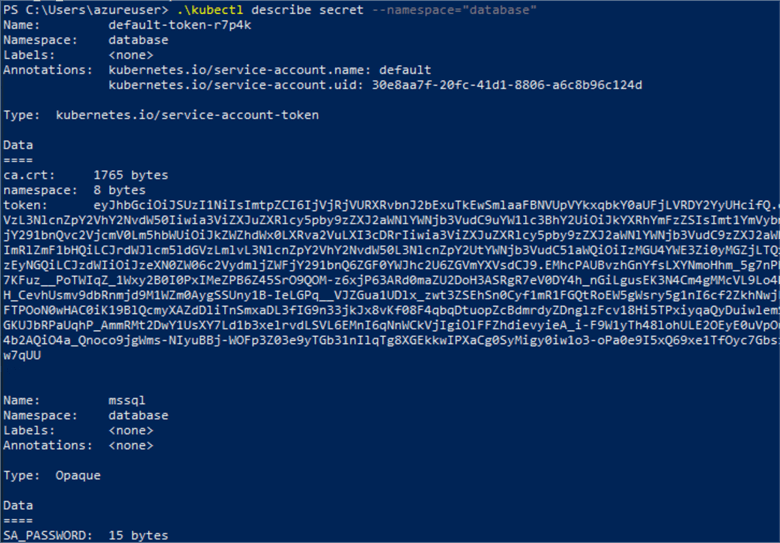
Next we need to create persistent volume. Persistent volumes are independent storage volumes where data is written. When creating a persistent volume, they are like storage pods, that is claimed by your pods. Thus, we need to create a persistent volume claim (pvc). For this tip, we will create a persistent volume claim using Azure disk.
In your local directory, open Notepad, copy the below script and save as pvc.yaml.
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: azure-disk
namespace: database
provisioner: kubernetes.io/azure-disk
parameters:
storageaccounttype: Standard_LRS
kind: Managed
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mssql-data
namespace: database
annotations:
volume.beta.kubernetes.io/storage-class: azure-disk
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 8Gi
Once you have the file ready, run the below kubectl command.
.\kubectl apply -f pvc.yaml

Verify the pvc with the describe command.
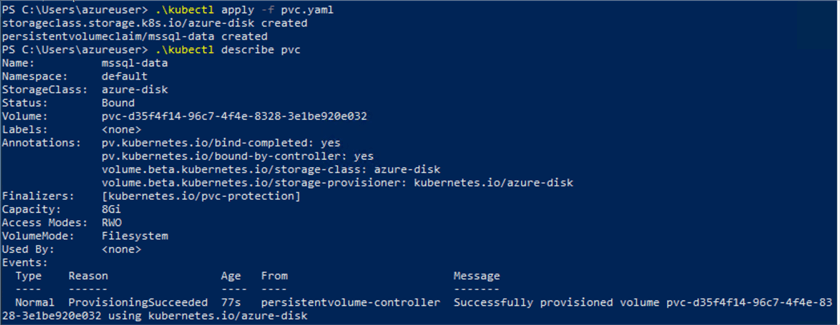
In the Azure portal, the disk is created as below.

On the Azure Kubernetes Cluster, it should appear in the Storage of your AKS.

The next step will prepare the script for the SQL Server deployment. To create the sqldeployment.yaml, open Notepad, and copy the below script and save as sqldeployment.yaml.
apiVersion: apps/v1
kind: Deployment
metadata:
name: mssql-deployment
namespace: database
spec:
replicas: 1
selector:
matchLabels:
app: mssql
template:
metadata:
labels:
app: mssql
spec:
terminationGracePeriodSeconds: 30
hostname: mssqlinst
securityContext:
fsGroup: 10001
containers:
- name: mssql
image: mcr.microsoft.com/mssql/server:2019-latest
ports:
- containerPort: 1433
env:
- name: MSSQL_PID
value: "Developer"
- name: ACCEPT_EULA
value: "Y"
- name: SA_PASSWORD
valueFrom:
secretKeyRef:
name: mssql
key: SA_PASSWORD
volumeMounts:
- name: mssqldb
mountPath: /var/opt/mssql
volumes:
- name: mssqldb
persistentVolumeClaim:
claimName: mssql-data
---
apiVersion: v1
kind: Service
metadata:
name: mssql-deployment
namespace: database
spec:
selector:
app: mssql
ports:
- protocol: TCP
port: 1433
targetPort: 1433
type: LoadBalancer
Once you have created the file, run kubectl to apply the deployment yaml.
.\kubectl apply -f sqldeployment.yaml

To verify that we have the pod created, run the kubectl get pod command. The pod has a status of Running. This status indicates that our SQL Server container is ready.
.\kubectl get pod

On the Azure portal, in the Azure Kubernetes Cluster resource, navigate to the menu for Services and Ingresses. You should be able to see msql-deployment. Our SQL Server service is ready for connections at this point.
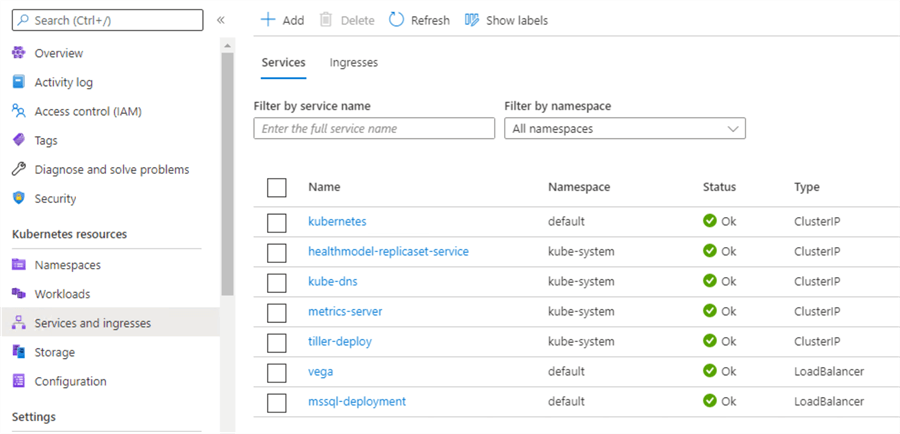
In the column for External IP Address (not shown in the image but the column next to Type) note the ExternalIP address for mssql-deployment. The external IP created by the deployment is also created as a public IP address under the same Kubernetes internal resource group.
Use this same ExternalIP to connect the SQL Server via SSMS or Azure Data Studio.


SQL Recovery and Reliability
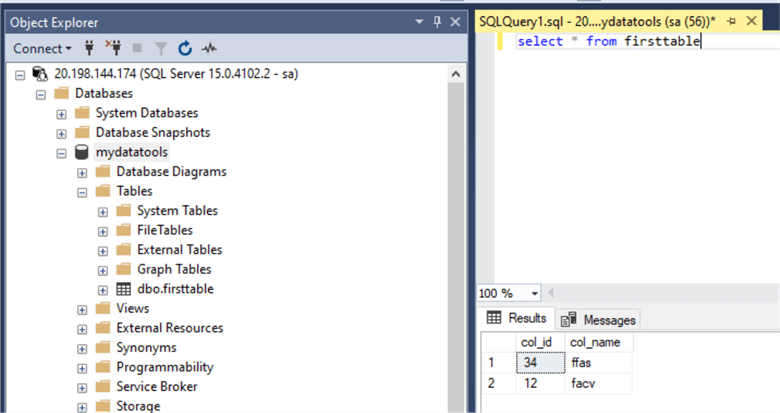
Suppose in your SQL Server that is running in your AKS, you have the table below and created a couple of rows.

Now to test recovery and reliability for our data, lets delete the pod that mssql-deployment is using.
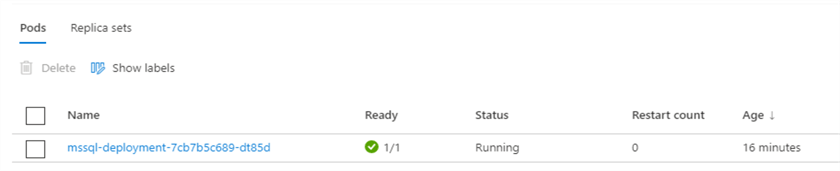

.\kubectl delete pod mssql-deployment-7cb7b5c689-dt85d
The Kubernetes cluster will see this delete operation and will create a new pod using our msql-deployment.yaml. The persistent volume claim (pvc) created earlier will still exist and attach to the new pod. The operation will be recorded in the Kubernetes Cluster events.

And retaining the exact state of your data when the delete pod operation happened.
At this point, I hope I have helped you understand running SQL Server in containers and applying or deploying them to Azure Kubernetes Cluster. Feel free to leave comments if you have any questions. Happy learning!
Next Steps
- Check out these amazing tips for building SQL Server container images:
- SQL Server Container tips.
- Manage your SQL Server Containers.
- Understand persistent volumes for your SQL Containers better.

Carla Abanes is a certified Microsoft SQL Server Database Administrator with extensive experience in data architecture and supporting mission critical databases in production environments. She is based in Manila and wears 2 hats at work as a SQL Server Technical Lead and as a Cloud Architect.
She holds a certification in AWS Solutions Architect – Professional and Azure Administration. I am passionate about conceptualizing proof-of-concepts, turning ideas into real applications and overcoming challenges that come with the execution and delivery of solutions.

It look great!
Hello Carla ,
Nice article. I have having 100 Pods running on AKS. now I want to run one existing script to all running pods.
How can I do?
Thanks in advance.