Problem
The number of computer systems has drastically increased over time as the number of people supporting those systems has decreased. This means managers are responsible for doing more with less staff. If custom code is written for each business rule and duplicated for applications, we will have a maintenance nightmare. How can we reuse code that has been hardened by extensive testing?
Solution
Azure Databricks supports two ways to define and use functions to reduce maintenance. Functions were added to the Azure Databricks runtime engine in version 9.1. These functions are defined using Spark SQL within the notebook. Before the introduction of native functions, the Python library supported the creation of user defined functions that could be used with either dataframes or SQL. Today, we are going to investigate how to define and use functions.
Business Problem
Our company has just started using Azure Databricks, and our manager wants us to learn how to use functions to increase code reuse. Here is a list of topics we need to investigate and report on:
| Task Id | Description |
|---|---|
| 1 | Scalar functions |
| 2 | Using functions |
| 3 | Table functions |
| 4 | User defined functions |
At the end of the research, we will have a good understanding of how to create and use functions.
Scalar Functions (Spark SQL)
Two types of values can be returned from a Spark SQL function: scalar values and table values. In this section, we will be talking about scalar functions. The first program every computer scientist write is “hello world.” The first function defined below is similar in nature. We will use the %sql magic command in our Python notebook to signify the language of our statements.
Run the code below to create a function called “big_data” that returns a simple string. Use the CREATE FUNCTION documentation to learn more.
%sql CREATE FUNCTION big_data() RETURNS STRING RETURN 'Spark rules the world!';
Execute the function called “big_data” in a typical SELECT statement to see the output.
%sql SELECT big_data() AS Truth;
The output of our very first function is shown below.

Below is an example of another function.
%sql
CREATE OR REPLACE FUNCTION mask_data (clear_txt STRING, last_chars STRING)
RETURNS
STRING
RETURN
if (char_length(clear_txt) <= cast(last_chars as int),
clear_txt,
concat( repeat('=', char_length(clear_txt) - cast(last_chars as int)),
substring(clear_txt, - cast(last_chars as int)))
);
Using Functions (Spark SQL)
Often, a company might have several user functions already defined in the hive catalog. Call the SHOW USER FUNCTION statement to find out what is in your environment:
%sql SHOW USER FUNCTIONS
The output of this statement shows three functions in my environment.

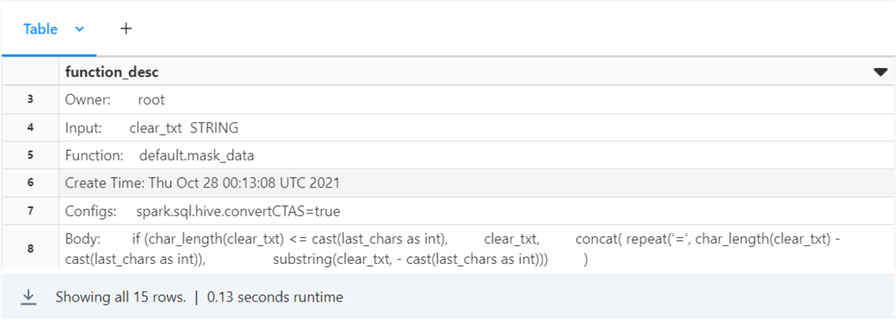
Use the DESCRIBE FUNCTION EXTENDED statement to find details on the “mask_data” function.
%sql DESCRIBE FUNCTION EXTENDED default.mask_data
There is a ton of detail about this function. See the image below for more information. I chose to screenshot the most important part of the output.
What are the inputs, and what does the code do? The function takes two inputs. The string parameter called clear_txt is the string we want to mask. The integer parameter called last_chars tells the program how many characters at the end of the string to leave unmasked. The output is the masked data string.
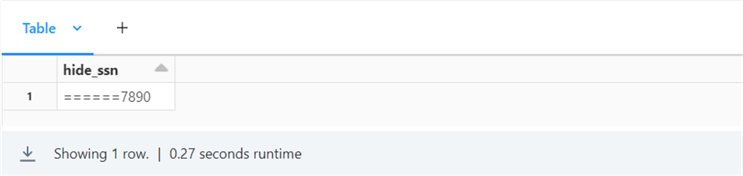
Let’s try using the “mask_data” function now. There is a fictitious SSN as input.
%sql
SELECT default.mask_data("1234567890", 4) AS hide_ssn;
The output of the SELECT statement only shows the last 4 digits of the SSN.
While you might slowly build your user functions, the Spark SQL language comes with many prebuilt functions. Use the SHOW SYSTEM FUNCTIONS statement to list these functions.
%sql SHOW SYSTEM FUNCTIONS
There are 360 predefined functions in the Azure Databricks engine version 9.1, which is a deployment of Apache Spark 3.1.2 code base. I will use the explode function in an upcoming section.

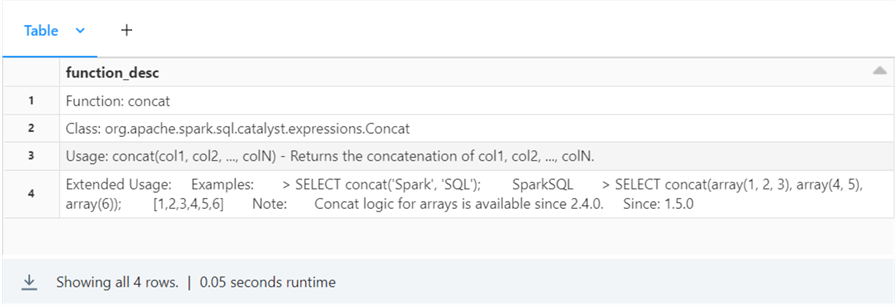
If you want to learn more about a function, use the DESCRIBE FUNCTION EXTENDED statement. The code below gives more details on the concat function.
%sql DESCRIBE FUNCTION EXTENDED concat
The output below shows the name of the function, usage information, and extended usage information.
Since our first function was for learning, we can remove it from the hive catalog using the DROP FUNCTION statement.
%sql DROP FUNCTION big_data;
ANSI SQL supports CREATE, ALTER, and DROP statements for most objects. In Azure Databricks, the CREATE statement comes with an OR REPLACE clause to implement alter actions. So far, we have dealt with user defined functions that return scalar values and system defined functions. In the next section, we will discuss user defined functions that return table values.
Table Functions (Spark SQL)
I will leverage the mounted tables we created last time in the SPARKTIPS schema. These tables were related to airports, airplanes, and air travel. Using a filter, we can use the SHOW TABLES statement to get a list of our tables in our schema.
The code below lists the tables in question.
%sql SHOW TABLES IN SPARKTIPS LIKE 'MT*';
The output below shows the details generated by the statement.

The auditors have told us that data filtered for a given year is a common query. To make life simpler, we want to create a function that returns airplane data for a given year. The default parameters were added to the Databricks Runtime Engine in version 10.4. The code below creates a user defined function called “get_tail_numbers” in the “sparktips” schema. Object names are not case-sensitive in Spark SQL. We must define the return TABLE for the output from the SELECT statement, which is filtered by the year.
%sql
CREATE OR REPLACE FUNCTION sparktips.get_tail_numbers(yearno string)
RETURNS TABLE (
tailnum string,
type string,
manufacturer string,
issue_date string,
model string,
status string,
aircraft_type string,
engine_type string,
yearno string
)
RETURN
SELECT * FROM sparktips.mt_airplane_data ad WHERE ad.year = yearno;
The query below calls the user defined function to return planes in 2003:
%sql
select * from sparktips.get_tail_numbers('2003')
The output below was generated by the table value function above:

To recap, we can use Spark SQL to define functions that return tables. However, this has not added anything special we cannot normally do in the Spark SQL language. In the next section, we will talk about creating user defined functions using Python. This design pattern allows us to use all the pre-built open-source libraries in our Spark SQL code. Check out the PiPy website when looking for Python libraries.
User Defined Functions (Python or Scala)
Certain data problems can be more easily solved with sets (lists) instead of calculations. For instance, I have several employees with overlapping hire and release dates. I want to figure out the total time an individual has been with the company versus the number of workdays used in pension calculations. How can I do this easily in Spark?
The Panda’s library comes with two useful functions for the given problem:
- date_range: Creates a list of dates from a given start and end date
- strftime: Formats the date.
Please see the Python code below that creates a function called expand_date_range_to_list.
We must use functions to redefine the Python function for use with both dataframes and SQL. The sql.functions.udf function takes two parameters: the name of the python function and the return data type. In our case, it is an array of strings. The resulting function called udf_expand_date_range_to_list can be used with dataframes. The spark.udf.register function is used to publish the user defined function for use in Spark SQL.
#
# 0 - Create utility function
#
# required library
import pandas as pd
# define function
def expand_date_range_to_list(start_dte, end_dte):
return pd.date_range(start=start_dte, end=end_dte).strftime("%Y-%m-%d").tolist()
# required libraries
from pyspark.sql.functions import *
from pyspark.sql.types import *
# register df function
udf_expand_date_range_to_list = udf(expand_date_range_to_list, ArrayType(StringType()))
# register sql function
spark.udf.register("sql_expand_date_range_to_list", udf_expand_date_range_to_list)
We can easily test the Python function with a simple call.
# test function
out = expand_date_range_to_list("2022-09-01", "2022-09-05")
out
The output is a list of strings.
The Python code below creates a dataframe from tuples of data and column names. There are three employees and six dates of employment. Two temporary views have been created with the following properties: employee_data0 (does not have dates expanded as a list) and employee_data1 (has dates expanded as a list). We can see the use of the withColumn dataframe method to create a new column called date_list. This column is the output from calling the udf_expand_date_range_to_list function.
#
# 1 - Create sample dataframe + view
#
# required library
from pyspark.sql.functions import *
# array of tuples - data
dat1 = [
("A", "1", "1995-09-08", "1997-09-09"),
("A", "2", "2003-05-08", "2006-11-09"),
("A", "3", "2000-05-06", "2003-05-09"),
("B", "4", "2007-06-27", "2008-05-27"),
("C", "5", "2003-01-20", "2006-01-19"),
("C", "6", "2011-04-03", "2011-04-04")
]
# array of names - columns
col1 = ["user", "rid", "hiring_date", "termination_date"]
# make data frame
df1 = spark.createDataFrame(data=dat1, schema=col1)
# make temp hive view
df1.createOrReplaceTempView("employee_data0")
# expand date range into list of dates
df1 = df1.withColumn("date_list", udf_expand_date_range_to_list( col("hiring_date"), col("termination_date") ) )
# make temp hive view
df1.createOrReplaceTempView("employee_data1")
# show schema
df1.printSchema()
# show data
display(df1)
This is the output of the first record of the dataframe.

The code below shows the usage of the SQL registered function on the temporary view.
%sql select user, rid, hiring_date, termination_date, sql_expand_date_range_to_list(hiring_date, termination_date) as date_list from employee_data0
The same output is achieved but uses Spark SQL instead of dataframe methods. We need to use the explode function, which pivots the list elements into rows. In the final solution, I used a common table expression to perform this translation before aggregating and filtering data.
%sql select user, explode(sql_expand_date_range_to_list(hiring_date, termination_date)) as dates from employee_data0
The above code produces the following output:

Now, we can finally start answering some business questions. For each employee, how many total days between their first hire and termination date; how many days worked and days not worked for the company given the employment record? The code below uses the dayofweek Spark SQL function to exclude weekends.
%sql with cte as ( select user, explode(date_list) as dates from employee_data1 ) select user, datediff(max(dates), min(dates)) as total_days, count(distinct dates) as work_days, datediff(max(dates), min(dates)) - count(distinct dates) as unworked_days from cte where dayofweek(dates) not in (1, 7) group by user
The image below shows the answers for the three employees:

The pension department needs to look at the same data but differently. Weekends need to be included to represent the calendar days and years.
%sql with cte as ( select user, rid, explode(date_list) as dates from employee_data1 ) select user, rid, count(distinct dates) as work_days, round(count(distinct dates) / 365.25, 2) as work_years from cte group by user, rid order by user, rid
The image below shows each work period by employee. It contains both workdays and work years.

In a nutshell, we took a calendar date problem and turned it into a set problem. Duplicate dates were tossed out using the DISTINCT clause of the SELECT statement. This is a very small example of how Python or Scala User Defined Functions can be used to solve complex problems.
Next Steps
There are two ways to perform data engineering with Spark. We can either work with Spark SQL or Spark dataframes. Spark SQL supports both scalar and table value functions. While a lot can be done within this language, we are limited to what the language offers. On the other hand, creating user defined functions in a language like Python or Scala is extremely powerful. In this tip’s last example, we solved a date problem using lists created from a function defined in the Pandas library for Python.
Many Python libraries can be installed on the cluster and used in notebook code. In the past, I had to work with satellite data formatted and stored on two lines in the data file. I could have written special Spark code to handle this condition by parsing a text file and keeping track of odd/even line numbers. See the sample data file in the image below.

Instead, I installed the two-line encoding (TLE) library from PyPi.org to solve this problem. Unless you are dealing with extremely large data sets, you might use prebuilt open-source libraries to get the data into Python objects that can be stored to the data lake. This is another example of re-using code. See the image below of data stored in memory as a tuple.

One thing I mentioned but did not stress enough is the centralized use of common code (functions) that have undergone a rigorous testing process. If all the users come up will their own business calculations within your company, you might not have a single truth. Also, if a change needs to be made to a business calculation in hundreds of queries, every notebook must be changed if you are not using functions. If you are using centralized functions, only one section of code has to be changed.
Enclosed are the code files that contain the following information: Spark SQL code and the Spark dataframe code.

John Miner is a Senior Data Architect at Insight Digital Innovation helping corporations solve their business needs with various data platform solutions.
He has over thirty years of data processing experience, and his architecture expertise encompasses all phases of the software project life cycle, including design, development, implementation, and maintenance of systems.
His credentials include undergraduate and graduate degrees in Computer Science from the University of Rhode Island. Also, he has earned certificates from Microsoft for Database Administration (MCDBA), System Administration (MCSA), Data Management & Analytics (MCSE), Data Science (MPP), Databricks Certified, and Fabric Certified.
John has been recognized with the Microsoft MVP award nine times for his outstanding contributions to the Data Platform community.
When he is not busy talking to local user groups or writing blog entries on new technology, he spends time with his wife and daughter enjoying outdoor activities. Some of John’s hobbies include wood working projects, crafting a good beer and playing a game of chess.
- MSSQLTips Awards: Author of the Year – 2019, 2022, 2023 | Champion (100+tips) – 2023


