Problem
The previous tip, Google Cloud Platform Overview for a Data Professional – Part 1, provided insights on the Google Cloud Platform (GCP) virtual network and some of Compute Engine’s features. There are other GCP products we need to look at to feel more comfortable working with GCP as a data professional.
Solution
This tip continues the series and covers topics regarding data storage options and available database services.
GCP Data Storage Options
The storage options available in GCP are object storage, block storage, and file storage. Before digging into the details, let’s briefly overview these storage types.
- Object storage is a sequence of bytes that can be accessed with a URL and has metadata to describe the data. Think of it like a flat structure where data is broken into many objects.
- Block storage has the data stored in chunks (blocks). When data is needed, the software layer underneath reassembles the chunks and forms the complete file. For example, it’s used in SANs to provide a storage layer for databases.
- File storage has the data stored in one piece inside a folder. It has a path to access a specific file. A great example is the Windows file system.
Let’s look at their characteristics to help us choose the best product for our needs.
| Object Storage | Block Storage | File Storage | |
|---|---|---|---|
| Cloud storage | Persistent disk | Local SSD | Filestore |
| Good for: Unstructured data, binary, object data, blobs Use cases: Streaming videos, documents, images, backups, websites | Good for: Block store for VMs Use cases: Disks for VMs, database storage | Good for: Ephemeral block store for VM, stateless workload Use cases: Application scratch disk, scale-out analytics, hot cache layer for analytics | Good for: Shared file storage for unstructured data Use cases: Fully managed NAS option, media processing, machine learning, application migration |
Cloud Storage
You can use cloud storage for many things, like serving website content, storing data for archival and disaster recovery, or distributing large data objects to users via direct download. Cloud storage has a couple of key features:
- It’s scalable to exabytes of data.
- It has very high availability across all storage classes.
- It has a single API across those storage classes.
- Customer-supplied encryption key (CSEK).
- Object Lifecycle Management – automatically delete or archive objects.
- Object Versioning – Maintain multiple versions of objects.
- Encryption at rest.
Cloud storage is a collection of buckets where you place objects. Directories can be created. But in the case of object storage, a directory is nothing but an object that points to different objects in the bucket. Each object has a unique URL that you use to access that specific object.
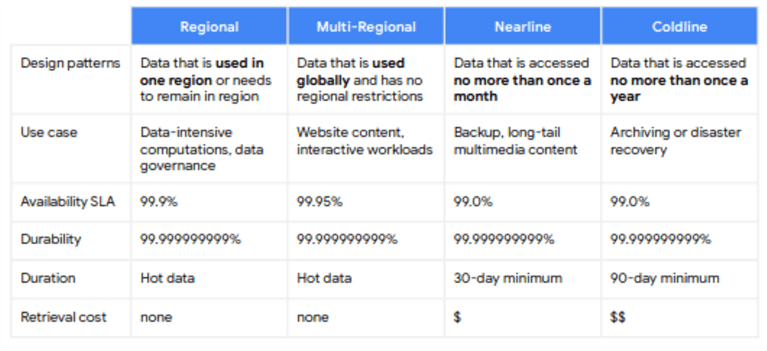
Cloud storage has multiple storage classes: Regional, Multi-regional, Nearline, and Coldline. They have different prices, SLAs, and use cases.
You can specify a storage class when you upload an object in cloud storage. If you want, you can change the storage class of existing objects without moving them to another bucket or changing the URL. Depending on the access pattern or purpose, you can minimize storage costs by setting different storage classes on objects. For example, setting the storage class to Nearline or Coldline makes sense for rarely accessed objects.
Block Storage
Used by the Compute Engine VMs, block storage can be accessed by the operating system as a mounted drive volume.
Persistent Disk performance scales with the disk size and the number of CPUs on the VM instance. You can choose between SSD or HDD based on the performance you need; the disks are automatically encrypted, and you can snapshot them for backup purposes.
Local SSD has lower latency and is used for analytics and temporary data, making it a good candidate for a tempdb database in SQL Server.
File Storage
We can use Filestore for a fully managed file storage solution similar to a NAS option. Files can be mounted using NFS or SMB protocol, have a classic path, be backed up, have low latency, and provide concurrent access to tens of thousands of clients.
Here is a comparison between these storage solutions.
GCP Database Options
There are many flavors to choose from regarding databases in GCP based on the use case, structured or unstructured data, transactional processing, analytical work, etc.
Here is a quick recap regarding relational and non-relational databases:
- Relational databases store the data in tables, in rows and columns, and have a fixed schema. We use SQL syntax to interact with them, and they have ACID properties. Because of this, relational databases are suitable for apps that use structured data that requires referential integrity, data structure does not change very often, and table joins, complex queries, and reports are needed.
- Non-relational databases (NoSQL) store unstructured or semi-structured data in a non-tabular manner like key-value pairs, document store like JSON, wide-column or Graph databases. They scale horizontally and can handle a high volume of data with low latency and lots of transactions per second. NoSQL databases are mainly used for apps that require large-scale, complex, and diverse data where the data structure is dynamic and regularly changing and data retrieval is simple and expressed without table joins.
With this in mind, let’s look at the options.
Relational Databases
Cloud SQL
- Managed MySQL, PostgreSQL, and SQL Server databases, fixed schema, automated database provisioning, storage capacity management, and patching.
- Can automatically scale up storage capacity and scale out by adding read replicas.
- Use cases: web apps, e-commerce apps, CRM, general purpose database.
- In this tip, you can see how to migrate SQL Server database in Cloud SQL.
Cloud Spanner
- Globally-distributed, fixed schema, scales infinitely, up to 99.999% availability.
- Offers transactional consistency at a global scale, horizontal scalability, SQL, synchronous replication for high availability, and automatic database sharding based on request load and data size.
- Use cases: scalable large databases, gaming, financial ledgers, and apps that require to scale limitlessly with strong consistency and high availability.
Bare Metal for Oracle
- Lift-and-shift Oracle to GCP.
AlloyDB for PostgreSQL
- Fully managed PostgreSQL service for most demanding database workloads, faster than standard PostgreSQL, has machine learning integrated features for real-time insights and hybrid transactional and analytical processing (HTAP).
- Use cases: demanding enterprise workloads.
NoSQL Databases
Cloud Bigtable
- Wide-column, scales infinitely, good for heavy read and write events, low sub-millisecond latency workloads, integrates with HBase, Beam, Hadoop, and Spark.
- Use cases: adtech, recommendation engine, IoT, operational and analytical applications, storage engine for ML applications.
Firestore
- Serverless managed document datastore, multi-region replication, and strong global consistency, good for large-scale hierarchical data, ACID transactions, acts as a backend-as-a-service, newer version of Cloud Datastore.
- Use cases: game state, user profiles, mobile/web/IoT apps, real-time dashboards.
Firebase Realtime Database
- Shares many features with Firestore and half the name, but certain key elements set them apart.
- Firebase stores data as JSON tree, Firestore as a collection of documents similar to JSON structure, Firestore scales automatically, Firebase needs sharding.
- Check this resource for a comparison of features to help choose between Firebase and Firestore.
In-memory Database
Memorystore
- Fully managed in-memory data store service for Memcached and Redis used for sub-millisecond latency.
- Easy lift-and-shift your applications from Redis to Cloud Memorystore without code changes.
- Scales as needed, provisioning, replication, failover, and patching are all automated.
- Use cases: caching, gaming, session store, leaderboards.
Data Warehouse
BigQuery
- Fully managed, serverless, very fast, and highly scalable cloud data warehouse, has built-in machine learning and BI capabilities.
- Can store data in BigQuery, but its main usage is for big data analysis and interactive querying.
- Can query structured, semi-structured, and unstructured data using SQL.
- Use cases: data warehouse, real-time and log analytics, predictive analytics.
Let’s try to simplify choosing a database service.
- If we have structured data and need a fixed schema, we can use a relational database.
- If we need a dynamic schema with a changing structure and scaling is important go with a NoSQL solution.
- For analytics workload, we have Bigtable and BigQuery. If a data warehouse is needed, BigQuery comes in, and for in-memory workload and a caching engine, we have Memorystore.
Next Steps
- Check out Google Cloud Platform Overview for a Data Professional – Part 1
- In Part 3 of this series, we will continue to discuss GCP resource management, billing, and monitoring.

Sergiu Onet is a SQL Server Database Administrator for the past 10 years and counting, focusing on automation and making SQL Server run faster. He also has a SQL Server developer background, .NET and PowerShell skills which he likes to play around with and learn new things. He is also a certified Google Professional Cloud Architect and AWS Certified Solutions Architect-Associate. His routine tasks include performance tuning, setting up HADR environments, enforcing best practice settings on SQL Server, and automating tedious manual tasks.

