Problem
Sometimes when I see discussions about dimensional modeling for Business Intelligence projects, people say to avoid the snowflake schema and stick to a clean star schema. Why is that? Is something wrong with creating a snowflake schema?
Solution
For people not so familiar with the concepts of dimensional modeling, both modeling techniques are described in the following two tips:
It’s advised to go through both tips – if you haven’t already – before you continue with this tip, as they lay the groundwork for comparison.
In the author’s opinion, the main guideline for developing data warehouses with the dimension modeling methodology is the following:
- Always start with the star schema and only expand to a snowflake schema if it’s beneficial.
This rule seems to make sense: A snowflake is an expansion of a star schema. But when would you expand into a snowflake? To get more insight into this, let’s start with the pros and cons of a snowflake.
Snowflake Schema – Advantages
The most significant advantage of using a snowflake schema is normalization. Normalization itself yields certain benefits, such as reducing redundant data in the model. Take the product snowflake schema of the AdventureWorks sample data warehouse, for example:
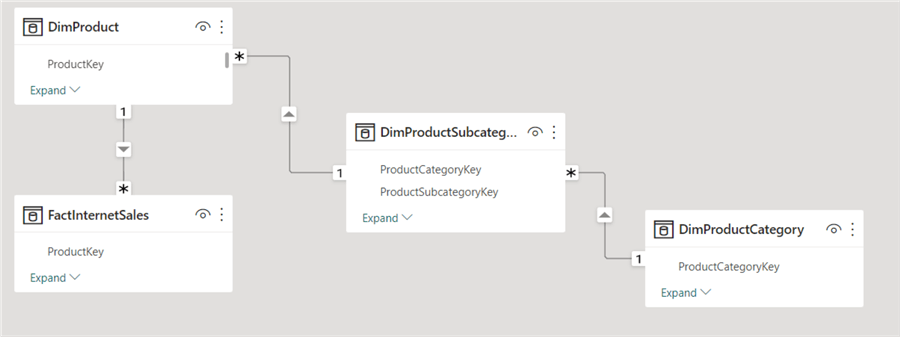
Suppose AdventureWorks is a big multinational company with millions of products. If we had a standard star schema, the subcategory and category information would be stored alongside the millions of rows in the product dimension tables. If both dimensions had many columns (common in data warehouses), this would incur massive overhead. Updating a category (of which only four exist, as shown in the screenshot below) will force an update across millions of rows!
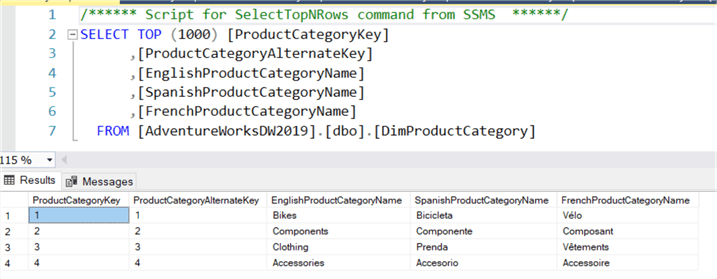
Such an update could be optimized by using an index but would incur overhead on other operations. Denormalizing data is done in a data warehouse to speed up the SELECT queries as fewer joins are needed. Still, this can come with considerable maintenance overhead for very large tables.
Another advantage of normalization is the reduced amount of storage needed. This was more important years ago than today since storage costs have plummeted thanks to elastic cloud storage, and storage size has grown considerably over the last decade. Furthermore, columnstore technologies like the columnstore index in SQL Server or the Snowflake cloud data warehouse (not to be confused with the snowflake schema itself) are so efficient in compressing data that it might be more beneficial to denormalize the data into one table.
Due to reduced storage and redundant data benefits, a snowflake schema can be more scalable from an ETL viewpoint, as inserts, updates, and deletes are faster. However, as mentioned before, modern technologies like Snowflake and Synapse Analytics make this less of an advantage than it used to be.
Because of the normalization, a snowflake schema can be more flexible. Suppose you have a very large customer dimension. The business wants to add a couple of extra columns with customer segmentation information. The number of different segments is small (e.g., small, medium, large), and only a handful of descriptive columns exist. But adding these to the large customer table might take some time. It might be beneficial to keep the segments in a different table – the dimension “customer segments” – and add a foreign key into the customer dimension. Adding one single integer column will always be less overhead than adding several string columns into a big table.
Snowflake Schema – Disadvantages
The main drawback of a snowflake schema is its complexity. Inevitably, you end up with more tables. If you need to write a SELECT statement on a fact table and its snowflaked dimensions, you must include more joins in the query. These will slow down the query. Aside from degradation in query performance, maintenance can be harder as well because there are simply more tables and ETL processes to maintain.
In the early days of data warehousing, normalization was the norm (as proposed by Bill Inmon, the “Father of Data warehousing”) for the central part of the data warehouse, typically called the enterprise data warehouse (EDW). On top of the EDW, data marts were built and modeled using star schemas. These data marts offered a view on a certain topic and were added to improve read performance. Later, Inmon proposed to model the EDW with data vault instead. In the Kimball methodology, the EDW only consists of star schemas.
Kimball proposed to eliminate the complexity and only use dimension and fact tables, which are easily understood by all users. A normalized schema is harder to understand and navigate by business users. Instead of having all customer information available in one single table, they need to combine data from several tables to get the desired outcome. It might come across as additional complexity for them while they don’t perceive the benefits of the normalization (they don’t need to handle updates and inserts in the data warehouse). After all, the information in a normal dimension is precisely the same as in snowflaked dimensions, so why split it up?
Conclusion
The advantages of a snowflake model:
- Reduced redundant data, which implies reduced storage size
- More scalable for writes
- More flexible
The disadvantages:
- More complexity by a higher number of tables
- Harder to understand by business users
- Reduced query performance
In general, it’s a good practice to always start with a star schema model and then add snowflake tables if needed.
Next Steps
- How to Create a Star Schema in Power BI Desktop
- The Importance of a Good Data Model in Power BI Desktop
- Why Power BI loves a Star Schema

Koen Verbeeck is a seasoned business intelligence consultant with over a decade of experience with the Microsoft Data Platform. He holds several certifications, including Azure Data Engineer. He’s a prolific writer, with over 375 articles on technologies such as Microsoft Fabric, SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at various events such as PASS, SQLBits, dataMinds Connect and many others. He frequently delivers educational webinars on MSSQLTips.com. For his efforts, Koen has been awarded the Microsoft MVP data platform award for many years.
- MSSQLTips Awards:
- Leadership Award (200+ Tips) – 2021
- Author of the Year – 2014/2020/2022
- Author Contender – 2024/2025


