Problem
At a project we have multiple filegroups created in our SQL Server data warehouse. For example, there was a filegroup to store the fact tables on, a filegroup for the dimensions, a filegroup for heavy indexes and so on. This works great at first, but after a while when people come and go on the project, tables are sometimes created and put in an incorrect filegroup or just created on the default filegroup (most likely PRIMARY). Is it possible to get an overview of all the tables and indexes to see which filegroup they are stored?
Solution
This tip will continue the series of Administration Intelligence and will provide the answer in the format of a custom report you can use in your own environment. First of all we need to construct a query that will provide us with all the information we need. The query is a modified version of a query submitted by Olaf Helper at the Microsoft Gallery.
SELECT
FileGroupName = DS.name
,FileGroupType = CASE DS.[type]
WHEN 'FG' THEN 'Filegroup'
WHEN 'FD' THEN 'Filestream'
WHEN 'FX' THEN 'Memory-optimized'
WHEN 'PS' THEN 'Partition Scheme'
ELSE 'Unknown'
END
-- ,AllocationDesc = AU.type_desc
,TotalSizeKB = SUM(AU.total_pages / 0.128) -- 128 pages per megabyte
,UsedSizeKB = SUM(AU.used_pages / 0.128)
,DataSizeKB = SUM(AU.data_pages / 0.128)
,SchemaName = SCH.name
,TableName = OBJ.name
,IndexType = CASE IDX.[type]
WHEN 0 THEN 'Heap'
WHEN 1 THEN 'Clustered'
WHEN 2 THEN 'Nonclustered'
WHEN 3 THEN 'XML'
WHEN 4 THEN 'Spatial'
WHEN 5 THEN 'Clustered columnstore'
WHEN 6 THEN 'Nonclustered columnstore'
WHEN 7 THEN 'Nonclustered hash'
END
,IndexName = IDX.name
,is_default = CONVERT(INT,DS.is_default)
,is_read_only = CONVERT(INT,DS.is_read_only)
FROM sys.filegroups DS -- you could also use sys.data_spaces
LEFT JOIN sys.allocation_units AU ON DS.data_space_id = AU.data_space_id
LEFT JOIN sys.partitions PA ON (AU.[type] IN (1, 3) AND AU.container_id = PA.hobt_id)
OR
(AU.[type] = 2 AND AU.container_id = PA.[partition_id])
LEFT JOIN sys.objects OBJ ON PA.[object_id] = OBJ.[object_id]
LEFT JOIN sys.schemas SCH ON OBJ.[schema_id] = SCH.[schema_id]
LEFT JOIN sys.indexes IDX ON PA.[object_id] = IDX.[object_id]
AND PA.index_id = IDX.index_id
WHERE OBJ.type_desc = 'USER_TABLE' -- only include user tables
OR DS.[type] = 'FD' -- or the filestream filegroup
GROUP BY DS.name,SCH.name,OBJ.name,IDX.[type],IDX.name,DS.[type],DS.is_default,DS.is_read_only -- discard different allocation units
ORDER BY DS.name,SCH.name,OBJ.name,IDX.name;
The query returns all the filegroups of the current database – including filestream and memory-optimized filegroups – together with the various user tables, schema, index information and the usage data in kilobytes.
Custom SQL Server Reporting Services Report
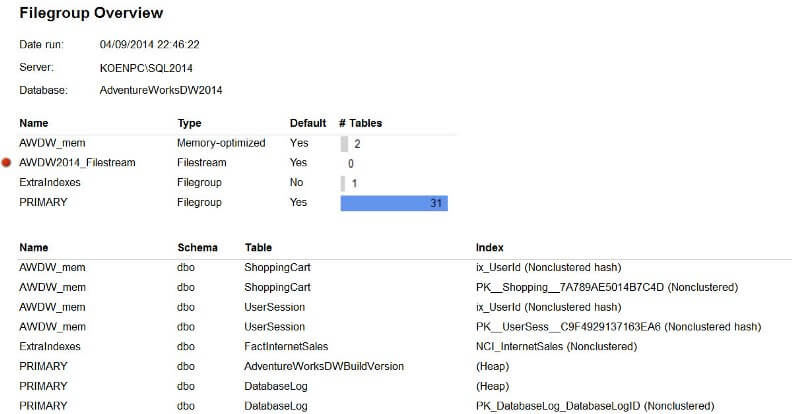
The report itself first gives an overview of all the different filegroups in the database, along with their type and the number of tables. There is also a column to indicate if the filegroup is a default filegroup or not and an indicator is displayed when a filegroup is read-only.

This tablix uses the detail information at the index level provided by the query. This means data has to be aggregated to the filegroup level. This is done by grouping on FilegroupName and FilegroupType in the details row group.

The Boolean columns is_default and is_read_only are converted to the int data type in the query so they can be aggregated. An expression checks if the result is bigger than 0 or not. For example:
iif(sum(Fields!is_default.Value) > 0,"Yes","No")
The number of tables is visualized through data bars. The values are derived using a distinct count on the table names. To make sure the biggest number doesn’t take all the horizontal space, the maximum value of the horizontal axis is set to the distinct count of all tables (as opposed to the distinct count of tables in the group). This is done by setting the scope of the distinct count to the entire tablix.

For example, the largest filegroup of 50 tables – with a total of 100 tables in the database – will take up 50% of a data bar.
Through an expression, the data bar of the PRIMARY filegroup gets another color so that it stands out against the other filegroups. The reason for this is that you can focus on the number of user tables that are still in the PRIMARY filegroup. It’s considered a good idea to make another filegroup the default.

The report contains another tablix with a detailed overview per filegroup.

The data you see here is based on the 2014 version of the AdventureWorksDW sample database. In order to have more than one filegroup, I enabled filestream on the DimProduct table, I added some memory-optimized tables and for fun I also added full-text search. The table displays the storage used by the index or heap in kilobytes. After an index name, the type of index is added between brackets.
The final report looks like this when added to SSMS:
See the tip Adding Custom Reports to SQL Server Management Studio on how to add a report to SSMS.
Next Steps
- The report created in this tip can be downloaded here for your own use.
- Keep your eye on the site for more tips about administration intelligence and custom reports that you can add to your toolbox.
- More tips on filegroups:

Koen Verbeeck is a seasoned business intelligence consultant with over a decade of experience with the Microsoft Data Platform. He holds several certifications, including Azure Data Engineer. He’s a prolific writer, with over 375 articles on technologies such as Microsoft Fabric, SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at various events such as PASS, SQLBits, dataMinds Connect and many others. He frequently delivers educational webinars on MSSQLTips.com. For his efforts, Koen has been awarded the Microsoft MVP data platform award for many years.
- MSSQLTips Awards:
- Leadership Award (200+ Tips) – 2021
- Author of the Year – 2014/2020/2022
- Author Contender – 2024/2025