Problem
Performing Index Maintenance in Azure SQL Database has traditionally involved needing to use Azure Automation or rolling your own solution in App Service. The lack of any real integrated or semi-integrated job scheduling agent combined with the database centric approach of Azure SQL Database meant that DBAs have been reluctant to move due to the overhead of maintenance solutions.
Solution
With the introduction of Elastic Database Jobs in Azure, Microsoft has gone a long way to filling the gap that database administrators need to perform database maintenance. Combine this with Ola Hallengren’s IndexOptimize solution for index and statistics maintenance and this solves many of the problems in this area for database administrators.
Here we will look at how to deploy and schedule Ola’s solution and schedule regular maintenance with Elastic Database Jobs.
Deploying Ola Hallengren’s IndexOptimize on Azure Using Elastic Database Jobs
Because of the way that Azure SQL Database works we must deploy the maintenance solution to each Azure SQL Database to make use of it. There are two options, one is to deploy it via scripts such as DBATools, the other is to make it part of the job execution.
As I described in my earlier post, Introduction to Elastic Database Jobs, we can configure Elastic Database Jobs to automatically enumerate Azure SQL Servers, Shard Maps, and Elastic Pools. This means that as we add more databases to our collections they will automatically be identified and added to the system. In this instance I will look to make use of the job system to perform the deployment, there are however two conditions that we must meet to make this work.
- Creation and configuration of the appropriate logins and users for the Database Scoped Credential used by the Elastic Database Jobs on the target databases that we deploy.
- Job steps for the deployment must be idempotent as they will run with every execution of the job.
Assumptions:
- All databases that we will be targeting in this scenario have been configured with the appropriate logins and users that have the permissions needed to perform the activities in the job.
- Target group called “Index Maintenance Group” has been created and had servers/databases/elastic pools/shard maps added as covered in my previous tip “Introduction to Azure Elastic Database Jobs”.
The first thing that we need to do is create the job that will form the basis of this maintenance solution. We can do this with the following T-SQL statement.
--// Create a job that will run once a day.
DECLARE @JobName NVARCHAR(128) = N'Index Maintenance Solution'
DECLARE @JobDescription NVARCHAR(512) = N'Daily job that deploys and runs Ola Hallengrens IndexOptimize: https://ola.hallengren.com/'
DECLARE @Enabled BIT = 1
DECLARE @ScheduleIntercalType NVARCHAR(50) = N'Days'
DECLARE @ScheduleIntervalCount INT = 1
DECLARE @ScheduleStart DATETIME2 = N'20180817 22:00:00'
--// Create Job
EXEC jobs.sp_add_job @job_name = @JobName,
@description = @JobDescription,
@enabled = @Enabled,
@schedule_interval_type = @ScheduleIntercalType,
@schedule_interval_count = @ScheduleIntervalCount,
@schedule_start_time = @ScheduleStart
;
This script creates a job called “Index Maintenance Solution” that runs daily at 22:00.
Now we need to add the steps that will deploy the maintenance solution. We will need to modify these scripts slightly to consider things like the use of single quotes, etc. within the scripts from Ola.
All the objects that we are deploying as part of the following job steps are done in such a way that they will only be deployed if they do not already exist, meaning that they can be run every time the job runs without causing issues to existing deployments.
Step 1 – Deploy Maintenance Schema
To make this process as self-contained as possible, I am going to create a schema in the target database called Maintenance, and grant execute permission on this schema to the user that our Database Scoped Credential is mapped to. This will mean that the scope of execution is smaller than deploying to dbo and granting our user access to execute all the content of that schema. However, you should do what is appropriate for your environment and the constraints that you operate within.
DECLARE @JobName NVARCHAR(128) = N'Index Maintenance Solution'
DECLARE @JobStepName NVARCHAR(128) = N'Deploy Maintenance Schema.'
DECLARE @Command NVARCHAR(MAX) = N'IF NOT EXISTS(SELECT * FROM sys.schemas AS S WHERE s.name = N''Maintenance'')
BEGIN
EXEC sp_executesql @command = N''CREATE SCHEMA [Maintenance];''
GRANT EXECUTE ON SCHEMA::Maintenance TO [JobExecCredential01];
END
GO'
DECLARE @CredentialName NVARCHAR(128) = N'JobExecCredential01'
DECLARE @TargetGroupName NVARCHAR(128) = N'Index Maintenance Group'
DECLARE @Parallelism INT = 3
--// Create Job Step
EXEC jobs.sp_add_jobstep @job_name = @JobName,
@step_name = @JobStepName,
@command = @Command,
@credential_name = @CredentialName,
@target_group_name = @TargetGroupName,
@max_parallelism = @Parallelism
;
GO
Note: That by taking this approach we will need to modify the scripts from Ola’s solution to create the objects in the new maintenance schema, as well as updating the scripts to reference the objects in this schema.
Step 2 – Deploy Command Log Table
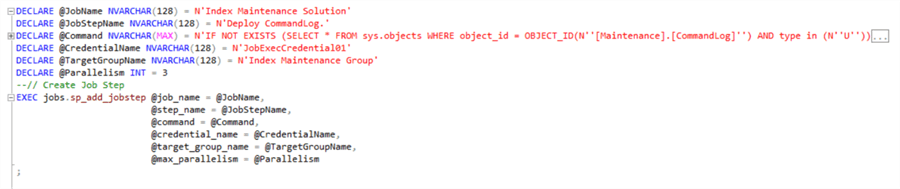
Deploying the Command Log table is the first step as it is used in subsequent procedures which we are going to be deploying as part of this process. All I have done is to modify the create scripts by adding extra single quotes to format the string so that it will work in the job step. You can download the script for this job step here.
Step 3 – Deploy Command Execute Procedure

The second job step is to deploy the command execute procedure which is used to run the commands generated in the subsequent IndexOptimize procedure.
You can download the script to create this job step here.
Step 4 – Deploy Index Optimize Procedure

Finally, the deployment of the IndexOpimize procedure which will be doing the work for us in managing the removal of index fragmentation. You can download the script for this job step here.
Index and Statistics Management Steps
Now that we have the maintenance components setup, it is time to make use of them. Here I am going to setup job steps to do index maintenance as well as statistics maintenance. Ola’s scripts are highly versatile and you can achieve a great degree of granularity by making use of the input parameters to his procedures. The Index Optimize process is comprehensively documented here.
Both job steps will log the executed commands to the CommandLog table in the target databases that is created as part of this process, allowing for further analysis of which indexes and stats are being rebuilt on a regular basis.
Index Maintenance Step
For this step I will simply use the default for rebuilding indexes for the user database with all the defaults.
DECLARE @JobName NVARCHAR(128) = N'Index Maintenance Solution'
DECLARE @JobStepName NVARCHAR(128) = N'Defrag Indexes.'
DECLARE @Command NVARCHAR(MAX) = N'DECLARE @DbName SYSNAME = DB_NAME();
EXECUTE maintenance.IndexOptimize @Databases = @DbName,
@LogToTable = ''Y'';'
DECLARE @CredentialName NVARCHAR(128) = N'JobExecCredential01'
DECLARE @TargetGroupName NVARCHAR(128) = N'Index Maintenance Group'
DECLARE @Parallelism INT = 3
--// Create Job Step
EXEC jobs.sp_add_jobstep @job_name = @JobName,
@step_name = @JobStepName,
@command = @Command,
@credential_name = @CredentialName,
@target_group_name = @TargetGroupName,
@max_parallelism = @Parallelism
;
Statistics Maintenance Step
This step is going to update statistics only on column level statistics where there has been data modification.
DECLARE @JobName NVARCHAR(128) = N'Index Maintenance Solution'
DECLARE @JobStepName NVARCHAR(128) = N'Rebuild Statistics.'
DECLARE @Command NVARCHAR(MAX) = N'DECLARE @DbName SYSNAME = DB_NAME();
EXECUTE maintenance.IndexOptimize @Databases = @DbName,
@FragmentationLow = NULL,
@FragmentationMedium = NULL,
@FragmentationHigh = NULL,
@UpdateStatistics = ''COLUMNS'',
@OnlyModifiedStatistics = ''Y'',
@LogToTable = ''Y'';'
PRINT @Command
DECLARE @CredentialName NVARCHAR(128) = N'JobExecCredential01'
DECLARE @TargetGroupName NVARCHAR(128) = N'Index Maintenance Group'
DECLARE @Parallelism INT = 3
--// Create Job Step
EXEC jobs.sp_add_jobstep @job_name = @JobName,
@step_name = @JobStepName,
@command = @Command,
@credential_name = @CredentialName,
@target_group_name = @TargetGroupName,
@max_parallelism = @Parallelism
;
Once we have deployed these two job steps we now have a maintenance routine in place to remove index fragmentation and managed statistics for our Azure SQL Database deployments that will scale as we need it to.
Summary
Microsoft continues to add functionality and services to Azure that allows Data Platform Engineers to be confident in moving more and more systems to the cloud. With Elastic Database Jobs Microsoft has filled another capability gap that existed in relation to retail SQL Server. Easily allowing Database Admins to port a familiar index maintenance routine to a new and unfamiliar platform helps make management of these new systems easier to adopt and manage as part of a SQL Server estate.
You can find a complete script that deploys the job and job steps for this post here.
Next Steps
- Introduction to Azure Elastic Database Jobs
- Adding Users to Azure SQL Databases
- How to use Azure SQL Database features and settings
- How to use the Azure SQL Database DTU Calculator
- Learn how to Migrate a SQL Server database to SQL Azure server
- Deploying Azure SQL Database Using Resource Manager PowerShell cmdlets
- SQL Azure Migration Wizard
- Guide to Getting Started with SQL Azure
- Long Term Storage for Azure SQL Database Backups

John Martin is a Data Platform Engineer working in the financial sector as well as Director-at-Large for the PASS organisation and currently a Microsoft Data Platform MVP. Previously John has worked as a product manager for SentryOne and a Premier Field Engineer with Microsoft UK.
Having over a decade of experience working with SQL Server and the Microsoft Data Platform. Working as a DBA, Developer and Consultant for Microsoft, John has been lucky enough to see how best, and how not, to use SQL Server and the Data Platform effectively.



I found that the orginal script from Ola Hallengren does not always work for Azure.
It relies on database_id from sys.databases and this is no longer reliable as it changes when the database is moved around. I had a case where sys.databases gave id 132 while db_id() gave 131
is there an updated version of this script?