Problem
Please provide an introduction for how to analyze contingency tables with SQL. Demonstrate how to derive contingency tables from a simple dataset. Also, provide a SQL framework for analyzing a contingency table via the Chi Square test statistic.
Solution
Do you want to leverage your dataset and SQL scripting skills for data science projects? Well, this tip is one place for you to start doing just that. An article on the DataCamp website motivated this tip; the DataCamp website is a tutorial and training resource for data science development skills. The article featured an introduction to contingency tables using the popular R language with the Chi Square test and other statistical tools. This tip aims to illustrate how you can create contingency tables and analyze them with a SQL script and the Chi Square test. A major goal of the tip is to illustrate one way to leverage SQL scripting in a typical data science project.
Both R and Python scripting environments feature much built-in functionality to facilitate data science projects, but they are not especially well endowed with relational database management features. On the other hand, SQL, as implemented by Microsoft with SQL Server and other leading SQL database providers, offers outstanding data management features and basic scripting capabilities that can be applied within data science projects. Using SQL instead of R or Python can make sense – especially when the data for a project are already stored (or destined to be stored) in a SQL database.
In this tip, you will see how to use a classic data science source (here and here) and SQL Server scripting features in a data science project. In addition to using a classic data science source, this tip also compares SQL and R for performing multiple steps in a data science project from accessing a dataset, to performing exploratory data analysis, to computing a contingency table, to computing a Chi Square statistic.
What is a contingency table?
Within statistics, a contingency table represents counts for two or more distinct sets of random discrete variables. The Data Science with SQL Server for Inferential and Predictive Statistics: Part 2 tip illustrates the layout of a two-way contingency table in a format suitable for analysis with SQL scripting. For your easy reference, the layout also appears below. This tip demonstrates computational and statistical techniques for a two-way contingency table.
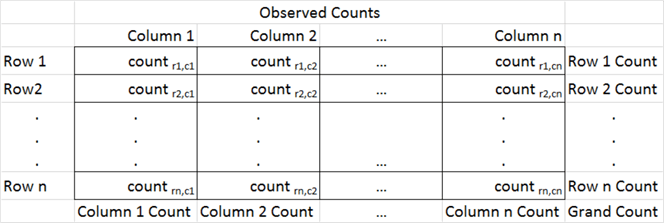
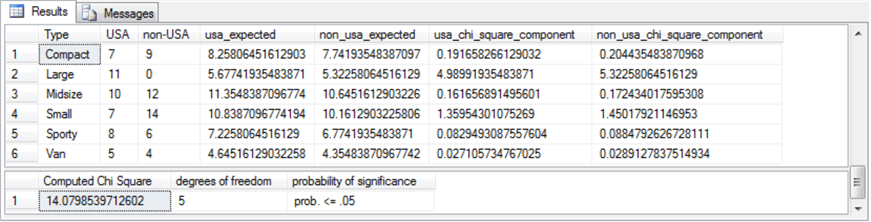
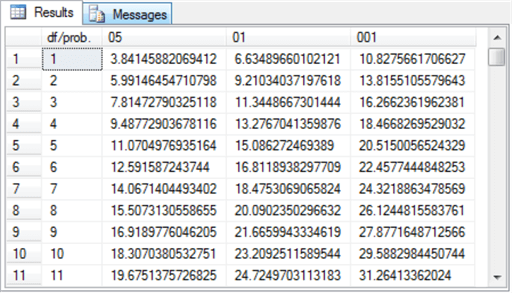
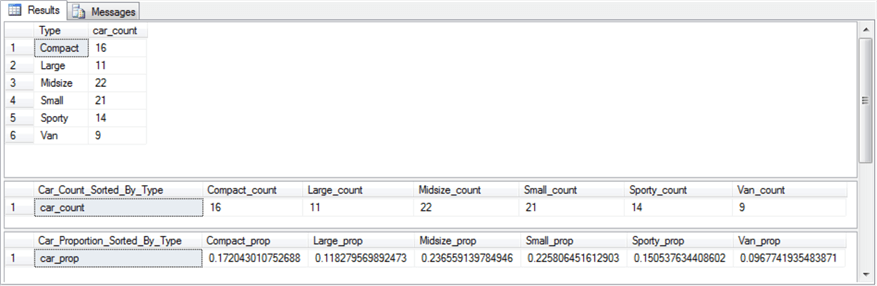
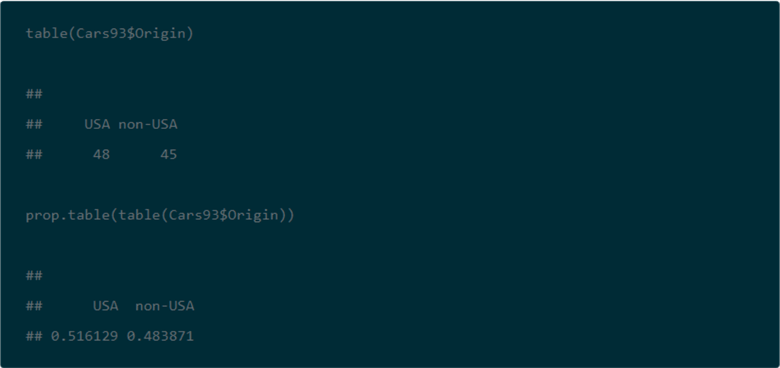
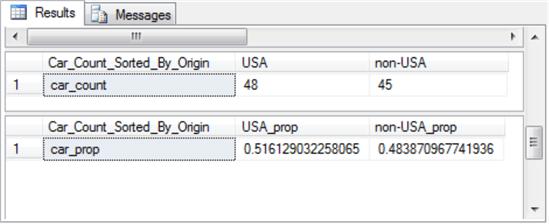
The contingency table consist of the cells with counts in them; the table normally appears with row and column labels. The row of column label values with Column 1 through Column n denote one set of discrete variables. The row label values with Row 1 through Row n denote a second set of discrete variables. Notice that each cell with a count in it also has two subscripts, such as count r1,c1 and count rn,cn There are three additional sets of values that are not strictly part of the contingency table. There is a row of column footers labeled Column 1 Count through Column n Count. These represent the sum of count values, respectively, in columns 1 through n. Similarly, there is a column of values to the right of the contingency label with the values Row 1 Count through Row n Count. These represent the sum of count values, respectively, in rows 1 through n. There is a third set consisting of just one additional value with the label Grand Count, which is the sum of all count values across all rows and columns. These three additional sets of values to the bottom and right of the contingency table are frequently useful for calculating expected values. By comparing the observed counts to the expected counts with a Chi Square statistic, you can assess the independence of the column category variable values from the row category variable values. There are two types of Chi Square tests for contingency tables. The Data Science with SQL Server for Inferential and Predictive Statistics: Part 2 tip includes a layout for computing expected values based on the independence of row and column category variables. This layout is duplicated below for your easy reference. As you can see, the expected value for a cell is the product of the row sum for a cell and the column sum for a cell divided by the grand count across all cells. Notice that cells in the following table of expected values have the same layout as the observed values in the contingency table. Even though the sampling plan (or how you collect data) for each kind of test is different, the computational details are the same for both the test for independence and the test for homogeneity. There is a restriction regarding the count per cell that is variously expressed in different sources (here, here, and here). For example, it is sometimes indicated that the minimum observed count must not be less than five. Other sources indicate that no more than twenty percent of the expected counts can be less than five. This tip does not take a position about the count per cell. If your contingency table does not conform to a set of minimum requirements or you cannot re-group the categorical data to conform to a set minimum count requirements, then you can consider another type of test instead of the Chi Square test. The computed Chi Square value is based on the squared difference between each cell’s observed and expected values divided by the cell’s expected value summed across all cells in the contingency table. Wikipedia demonstrates the application of this approach to calculating a computed Chi Square value for categorical data from a contingency table in the "Example chi-squared test for categorical data" section of its Chi-squared test page. In order to use the computed Chi Square value for either of the two Chi Square contingency tests, you need to compare the computed Chi Square value to a corresponding critical Chi Square value at an appropriate statistical significance level. Critical Chi Square values are defined by two parameters: the number of degrees of freedom and a level of statistical significance. The degrees of freedom for a two-way contingency table is the number of rows less one multiplied by the number columns less one. The most common statistical significance levels are the .05, .01, and .001; these are the statistical significance levels used in this tip. The critical Chi Square values for any degrees of freedom and statistical probability level can be derived from Excel’s CHISQ.INV.RT function. MSSQLTips.com has multiple tips describing how to populate a SQL Server table of critical Chi Square values from the CHISQ.INV.RT function (for example, see the "Introduction to Goodness-of-fit Chi Square test" section in the Using T-SQL to Assess Goodness of Fit to an Exponential Distribution tip). The table of critical Chi Square values for this tip resides in the Chi Square Critical Values 05 01 001 table of the AllNasdaqTickerPricesfrom2014into2017 database. The table is populated from an Excel worksheet with CHISQ.INV.RT function values imported into the SQL Server table. You can import the Excel worksheet, which is available as a download with this tip, to populate a SQL Server table in any database of your choice. The following screen shot shows an excerpt from the full table. The excerpt shows that critical Chi Square values increase with increasing degrees of freedom and statistical probability levels that are progressively rarer. The null hypothesis for the Chi Square test is that there is no difference between the set of observed counts and the set of expected counts. If the computed Chi Square value exceeds a critical Chi Square value at a given probability level, then the null hypothesis is statistically rejected at that probability. This tip uses the Cars93 dataset that ships with the R programming language package. This dataset has one row per make (comprised of a manufacturer and a model) with a top row of field names. This dataset is available from numerous sources; this tip demonstrates how to import the dataset into SQL Server from this source. When you click a link labeled "download this file" from the source, a csv file downloads to your computer, but the file has a non-standard format relative to typical Windows csv files. The following screen shot shows an excerpt from a Notepad++ session with the file after some minor editing. The editing removed double quote marks around field values in lines 2 through 94 and added ID as the first field name to line 1. The field and row terminators are, respectively, comma (,) and linefeed (LF). While the comma is a typical for a Windows csv file, the LF terminator is not typical. In fact, this formatting convention is typical for csv files in Unix and Linux operating systems. A prior tip demonstrates the need to use a special rowterminator code ('0x0a') in SQL Server when importing csv files terminating in LF. The following SQL script uses a two-step process for importing the Cars93.csv file into a SQL Server table. In the first step, all fields, except for ID, are imported as variable length character fields with a varchar (50) specification. The ID field is a number identifier for rows in the file, and its values are imported with an int data type. In the second step, the number field values, except for ID, are converted to int or float depending on whether they contain, respectively, integer data or data with a decimal point. The script additionally demonstrates some other features for importing data science datasets into SQL Server that you may find useful. The last two lines in preceding script display the contents of the #temp and #temp_clean tables. These statements are not strictly necessary, but it is often useful to echo data after the completion of critical steps. The next screen shot contains excerpts from the #temp and #temp_clean tables. The DataCamp tutorial on contingency tables with R starts with some exploratory data analysis. Many data scientists will begin the analysis of a dataset with some exploratory data analysis to become familiar with the data source that they plan to mine and/or model in subsequent processing steps. After a simple listing of values in the database in a way that is similar to the preceding screen shot, the tutorial reports some exploratory data analysis for key fields. For example, the following screen shot from the tutorial shows the syntax and results for tabulated counts and proportions by Type from the Cars93 dataset. The top portion of the screen shot is for car count by Type, and the bottom portion of the screen shot is for car proportion by Type. The following code segment displays SQL syntax for arriving at comparable results. The SQL code is less compact than the R code for at least a couple of reasons. SQL is not optimized for exploratory data analysis, and it is more natural with SQL to display results vertically rather than horizontally. Here’s the output from the preceding SQL script. The DataCamp tutorial next directs its attention to counts and proportions for cars by Origin. Cars are classified as manufactured in the USA or in a non-USA country. The reason for exploring this second variable is that its categories will eventually be used in a contingency table as well as a Chi Square test. The code is very compact and follows the same convention as for the car counts and proportions presented above. The next code excerpt is for computing car count and proportion by Origin from a SQL script. The approach follows the same general design as for car count and proportion by Type with the exception that for this script the aggregation of car count by Origin in a vertical alignment is not displayed. However, the aggregation of car count by Origin in a horizontal alignment is generated and displayed in the script below. Because this script is designed to be run immediately after the preceding script, there is no need to declare and populate the @all_cars variable. Here’s the output from the preceding SQL script. Again, the SQL results match the R results, except for the number of places to which values are rounded. The next screen shot shows the R script and its result for computing a contingency table from the Type and Origin in the Cars93 dataset. This script saves the contingency table to the tab1 object. As you will see later when we are computing a Chi Square test, it is not strictly necessary to save the contingency table in order to use it again. The next SQL script excerpt illustrates one approach to computing a contingency table for the Type and Origin in the Cars93 dataset. The next screen shot shows an excerpt from the #temp_row_id_by_col_id_ID table and the contingency table in #temp_type_by_origin_car_count. One reason for constructing a contingency table is to assess if the row categories are distributed in the same way across each column category. When the row categories are distributed in the same proportions across columns, then the row categories are said to be independent of the column categories. Within this tip, the row categories are vehicle types, and the column categories designate the origin country for a vehicle (namely, USA or non-USA). A Chi Square test can assign a statistical probability level to the assumption that the row categories are distributed independently across column categories. In the context of the Cars93 dataset, a Chi Square test can assign a probability level to the assumption that car types have an equal probability of being manufactured in the USA or outside of the USA (non-USA). The following screen shot shows the code and results from the DataCamp website for computing a Chi Square value based on the contingency table created in the preceding section. An R script implements this task. The following SQL script indicate one way to compute the Chi Square for the contingency table. The purposes for reviewing the code are to present a framework for applying a Chi Square test to any contingency table and to confirm that the SQL script generates the same result as the R script. There are four main steps to compute with SQL the Chi Square for the contingency table. Here’s a topline summary of the operations within the script that appears below. The SQL code is heavily commented to help you follow the detail about how the code works. The following screen shot shows the output from the preceding script. In particular, the top pane presents the Chi Square components in its two rightmost columns and the inputs for components in the preceding columns. The bottom pane shows the summary assessment for the computed Chi Square. Next Steps This tip depends on several files, which are available as a download with this tip. After installing the files in your development environment and verifying that they work as described in this tip, you should be ready to start processing your own data. Use a csv file as your source data file. Change the column names from Type and Origin to whatever other names are appropriate for your data. This will allow you to compute a two-way contingency table for any data of your choice and to run a Chi Square test to assess the independence of row and column categories from the contingency table. Rick Dobson is a SQL Server professional with decades of T-SQL experience that includes authoring books, running a national seminar practice, working for businesses on finance and healthcare development projects, and serving as a regular contributor to MSSQLTips.com. He has been a practicing Python developer for more than the past half decade – with a special emphasis for data visualization and ETL tasks with JSON and CSV files. His most recent professional passions include financial time series data and analyses, AI models, and statistics. If you are interested in growing your skills in any of these areas especially as they relate to financial securities, consider visiting his blog at https://securitytradinganalytics.blogspot.com/2023/12/.What is a Chi Square test for a contingency table?

The data for the contingency table
-- create fresh copy of #temp with varchar fields
-- except for ID int column
begin try
drop table #temp
end try
begin catch
print '#temp not available to drop'
end catch
create table #temp(
ID INT
,Manufacturer varchar(50)
,Model varchar(50)
,Type varchar(50)
,"Min.Price" varchar(50)
,"Price" varchar(50)
,"Max.Price" varchar(50)
,"MPG.city" varchar(50)
,"MPG.highway" varchar(50)
,"AirBags" varchar(50)
,"DriveTrain" varchar(50)
,"Cylinders" varchar(50)
,"EngineSize" varchar(50)
,"Horsepower" varchar(50)
,"RPM" varchar(50)
,"Rev.per.mile" varchar(50)
,"Man.trans.avail" varchar(50)
,"Fuel.tank.capacity" varchar(50)
,"Passengers" varchar(50)
,"Length" varchar(50)
,"Wheelbase" varchar(50)
,"Width" varchar(50)
,"Turn.circle" varchar(50)
,"Rear.seat.room" varchar(50)
,"Luggage.room" varchar(50)
,"Weight" varchar(50)
,"Origin" varchar(50)
,"Make" varchar(50)
)
-- cars93.csv is download from:
-- https://forge.scilab.org/index.php/p/rdataset/source/tree/master/csv/MASS/Cars93.csv
-- manual modifications to downloaded csv file
-- convert first column designator from "" to "ID" in first row
-- remove double-quote delimiters for column values in second through ninety-fourth rows
-- from file rows terminate with line feed character only as in Unix and Linux
-- so rowterminator is set to '0x0a'
bulk insert #temp
from 'C:\for_statistics\cars93.csv'
with
(
firstrow = 2
,fieldterminator = ','
,rowterminator = '0x0a'
)
go
-- create fresh copy of #temp_clean
begin try
drop table #temp_clean
end try
begin catch
print '#temp_clean not available to drop'
end catch
-- cleaned #temp table into #temp_clean with
-- int and float assignments for fields with numbers
-- text catches for NA and rotary in
-- Cylinders, [Rear.seat.room], [Luggage.room] columns
select
ID
,Manufacturer
,Model
,Type
,cast([Min.Price] as float) [Min.Price]
,cast(Price as float) Price
,cast([Max.Price] as float) [Max.Price]
,cast([MPG.city] as int) [MPG.city]
,cast([MPG.highway] as int) [MPG.highway]
,AirBags
,DriveTrain
,
case
when [Cylinders] = 'rotary' then NULL
else cast([Cylinders] as int)
end [Cylinders]
,cast(EngineSize as float) EngineSize
,cast(Horsepower as int) Horsepower
,cast(RPM as int) RPM
,cast([Rev.per.mile] as int) [Rev.per.mile]
,[Man.trans.avail]
,cast([Fuel.tank.capacity] as float) [Fuel.tank.capacity]
,cast(Passengers as int) Passengers
,cast(Length as int) Length
,cast(Wheelbase as int) Wheelbase
,cast(Width as int) Width
,cast([Turn.circle] as int) [Turn.circle]
,
case
when [Rear.seat.room] = 'NA' then NULL
else cast([Rear.seat.room] as float)
end [Rear.seat.room]
,
case
when [Luggage.room] = 'NA' then NULL
else cast([Luggage.room] as int)
end [Luggage.room]
,cast(Weight as int) Weight
,Origin
,Make
into #temp_clean
from #temp
-- echo original source data and cleaned data
-- primarily for clarifying input data processing
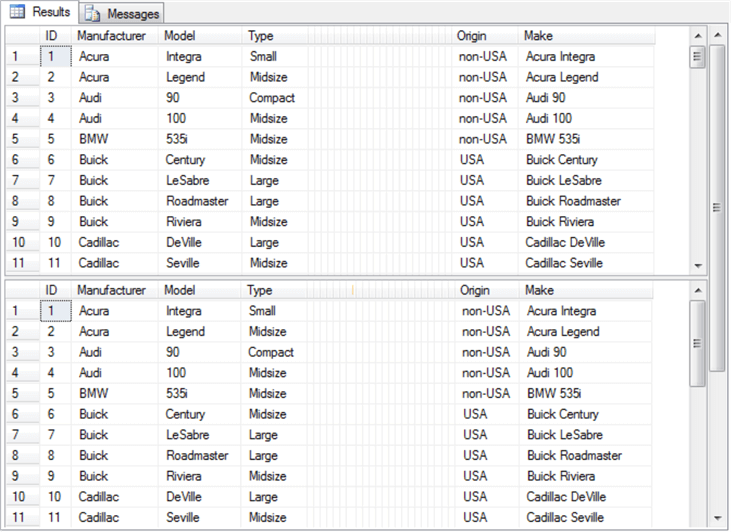
select * from #temp
select * from #temp_clean
SQL versus R for exploratory data analysis

-- declare/populate local variables for storing intermediate
-- scalar values for reuse in script
declare
@all_cars float =(select count(*) from #temp_clean)
,@computed_chi_square float
,@df int
,@05 float
,@01 float
,@001 float
-- create fresh copy of #temp_car_count_by_type
begin try
drop table #temp_car_count_by_type
end try
begin catch
print '#temp_car_count_by_type not available to drop'
end catch
-- this is for a source table in a pivot query
-- it is referenced by #temp_car_count_by_type in the pivot query
-- it is derived from a #temp_clean
select Type, count(ID) AS car_count
into #temp_car_count_by_type
FROM #temp_clean
group by Type;
-- echo #temp_car_count_by_type
select * from #temp_car_count_by_type
-- pivot table with one row and six column counts
select
'car_count' Car_Count_Sorted_By_Type
,[Compact] Compact_count
,[Large] Large_count
,[Midsize] Midsize_count
,[Small] Small_count
,[Sporty] Sporty_count
,[Van] Van_count
from
(select Type, car_count from #temp_car_count_by_type) AS SourceTable
pivot
(
avg(car_count) -- avg function captures previously aggregated value in SourceTable
FOR Type IN([Compact], [Large], [Midsize], [Small], [Sporty], [Van])
) AS PivotTable;
-- pivot table with one row and six column proportions
SELECT 'car_prop' Car_Proportion_Sorted_By_Type,
[Compact]/@all_cars [Compact_prop]
,[Large]/@all_cars [Large_prop]
,[Midsize]/@all_cars [Midsize_prop]
,[Small]/@all_cars [Small_prop]
,[Sporty]/@all_cars [Sporty_prop]
,[Van]/@all_cars [Van_prop]
FROM
(select Type, car_count from #temp_car_count_by_type) AS SourceTable
pivot
(
avg(car_count) -- avg function captures previously aggregated value in SourceTable
FOR Type IN([Compact], [Large], [Midsize], [Small], [Sporty], [Van])
) pivotable;
-- create fresh copy of #temp_car_count_by_origin
begin try
drop table #temp_car_count_by_origin
end try
begin catch
print '#temp_car_count_by_origin not available to drop'
end catch
-- source table name is #temp_car_count_by_origin
-- it is derived from a #temp_clean
select Origin, count(ID) AS car_count
into #temp_car_count_by_origin
from #temp_clean
group by Origin;
-- create fresh copy of #temp_car_count_by_origin
begin try
drop table #temp_pivoted_car_count_by_origin
end try
begin catch
print '#temp_pivoted_car_count_by_origin not available to drop'
end catch
-- pivot table with one row and two column counts
select 'car_count' Car_Count_Sorted_By_Origin,
[USA], [non-USA]
into #temp_pivoted_car_count_by_origin
from
(select Origin, car_count from #temp_car_count_by_origin) AS SourceTable
pivot
(
avg(car_count) -- avg function captures previously aggregated value in SourceTable
FOR Origin IN([USA], [non-USA])
) pivottable;
select * from #temp_pivoted_car_count_by_origin
-- pivot table with one row and two column counts
select 'car_prop' Car_Count_Sorted_By_Origin,
[USA]/@all_cars [USA_prop], [non-USA]/@all_cars [non-USA_prop]
from
(select Origin, car_count from #temp_car_count_by_origin) AS SourceTable
pivot
(
avg(car_count) -- avg function captures previously aggregated value in SourceTable
FOR Origin IN([USA], [non-USA])
) pivottable;
SQL versus R for contingency table calculation

-- create fresh copy of #temp_row_id_by_col_id_ID
begin try
drop table #temp_row_id_by_col_id_ID
end try
begin catch
print '#temp_row_id_by_col_id_ID not available to drop'
end catch
-- source table name is #temp_type_by_car_count
-- it is derived from a #temp_clean
SELECT ID, Origin, Type
into #temp_row_id_by_col_id_ID
FROM #temp_clean
-- echo of #temp_row_id_by_col_id_ID
select * from #temp_row_id_by_col_id_ID
-- create fresh copy of #temp_type_by_origin_car_count
begin try
drop table #temp_type_by_origin_car_count
end try
begin catch
print '#temp_type_by_origin_car_count not available to drop'
end catch
-- This is the contingency table
select Type, [USA], [non-USA]
into #temp_type_by_origin_car_count
from
(select Type, Origin, ID
from #temp_row_id_by_col_id_ID) p
pivot
(
count(ID)
for Origin IN([non-USA], [USA])
) pvt
order by pvt.Type;
-- echo of #temp_row_id_by_col_id_ID
select * from #temp_type_by_origin_car_count

SQL versus R for contingency table Chi Square results
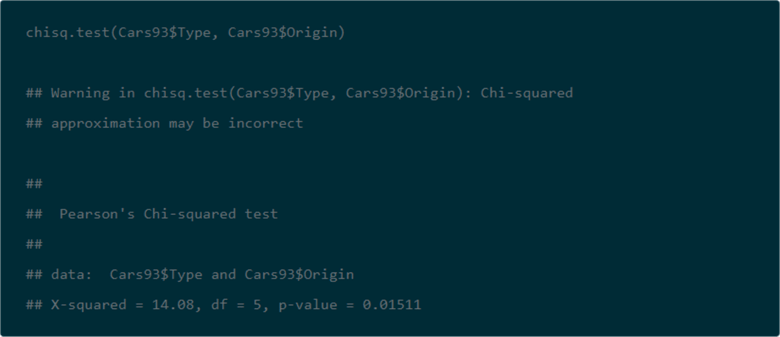
-- calculations for expected counts, computed Chi Square and its statistical significance
-- create fresh copy of #temp_expected_counts
begin try
drop table #temp_expected_counts
end try
begin catch
print '#temp_expected_counts not available to drop'
end catch
-- compute expected counts by row across types
select
car_count_by_type.Type
,(car_count_by_type.car_count*car_count_by_origin_all.USA)/car_count_by_origin_all.all_cars usa_expected
,(car_count_by_type.car_count*car_count_by_origin_all.[non-USA])/car_count_by_origin_all.all_cars non_usa_expected
into #temp_expected_counts
-- based on type marginal counts, origin marginal counts,
-- and @all_cars (Grand Total) result set
from
(select * from #temp_car_count_by_type) car_count_by_type
cross join
(
select *, @all_cars all_cars from #temp_pivoted_car_count_by_origin
) car_count_by_origin_all
-- compute and display chi square components
select
type_by_origin_car_count.* -- contingency table
,expected_counts.usa_expected -- usa column of expected counts
,expected_counts.non_usa_expected -- non-usa column of expected counts
-- chi square component rows for usa and non-usa columns
,power((usa-usa_expected),2)/usa_expected usa_chi_square_component
,power(([non-USA]-non_usa_expected),2)/non_usa_expected non_usa_chi_square_component
from
(select * from #temp_type_by_origin_car_count) type_by_origin_car_count
left join
(select * from #temp_expected_counts) expected_counts
on type_by_origin_car_count.Type = expected_counts.Type
-- assign values to local variables for
-- computed Chi Square (@computed_chi_square) and
-- degrees of freedom (@df)
select
@computed_chi_square = sum(summed_by_row)
,@df =((select count(*) from #temp_car_count_by_type)-1)
*((select count(*) from #temp_car_count_by_origin)-1)
from
(
-- chi square component by row
select
for_chi_square_components.Type
,(for_chi_square_components.usa_chi_square_component + for_chi_square_components.non_usa_chi_square_component) summed_by_row
from
(
-- compute chi square components
select
type_by_origin_car_count.*
,expected_counts.usa_expected
,expected_counts.non_usa_expected
,power((usa-usa_expected),2)/usa_expected usa_chi_square_component
,power(([non-USA]-non_usa_expected),2)/non_usa_expected non_usa_chi_square_component
from
(select * from #temp_type_by_origin_car_count) type_by_origin_car_count
left join
(select * from #temp_expected_counts) expected_counts
on type_by_origin_car_count.Type = expected_counts.Type
) for_chi_square_components
) for_computed_chi_square
-- lookup critical Chi Square values and
-- display computed Chi Square value, degrees of freedom and
-- probability of statistical significance for computed test value
select
@05 = [05]
,@01 = [01]
,@001 = [001]
from [Chi Square Critical Values 05 01 001]
where [df/prob.] = @df
select
@computed_chi_square [Computed Chi Square]
,@df [degrees of freedom]
,
case
when @computed_chi_square < @05 then 'prob. > .05'
when @computed_chi_square < @01 then 'prob. <= .05'
when @computed_chi_square < @001 then 'prob. <= .01'
else 'prob. <= .001'
end [probability of significance]