Problem
Please demonstrate how to use dynamic SQL and stored procedures to simplify dramatically the computation with SQL of one-way and two-way tabulations. The request is that the specification to calculate one-way or two-way tabulations with SQL should be as simple as with the R language.
Solution
A prior MSSQLTips.com tip (Contingency Table Analysis via Chi Square with SQL: Part 1) provided SQL-based templates for calculating counts of observed category values in one-way and two-way tabulations. Two-way tabulations are typically called contingency tables in data science projects. An additional template demonstrated how to assess the independence of row and column category values in a contingency table based on a Chi Square test. A noteworthy take-away from the prior tip is that it is possible to create SQL-based templates for calculating one-way and two-way tabulations. However, the SQL code is dramatically less compact at specifying this kind of calculation than the R scripting language, a popular data science programming tool. Also, the templates required some manual adjustment to accommodate new sets of category values. Nevertheless, much data for potential data science projects reside in SQL-based databases, and it could therefore be very beneficial to radically simplify the specification of one-way and two-way tabulations with SQL code.
This tip develops an improved SQL-based approach relying on dynamic SQL and stored procedures for computing one-way and two-way tabulations. The stored procedures accept parameters like built-in R-based functions for computing tabulations. Also, because of the use of dynamic SQL inside the stored procedures, the code does not require any changes to accommodate new row and column category value sets. All a user needs to do is update stored procedure parameter names pointing at new row and/or column categories.
The sizzle of this tip appears in three sections that are easy to scan. By quickly reviewing these sections, you can easily get the top-line idea conveyed by the tip. The section names are as follow.
- The “Demonstrations of one-way and two-way tabulations with R” section quickly demonstrates the R syntax for specifying one-way and two-way tabulations with R, which this tip aims to emulate with SQL.
- The “SQL one-way tabulation demonstrations” shows several examples of a SQL-based approach that lets you generate a one-way tabulation with just one line of SQL code.
- The “SQL two-way tabulation demonstrations” shows several examples of a SQL-based approach that lets you generate two-way tabulation with just one line of code.
If you decide you want to implement these kinds of solutions in your work or you just care to learn more about the approach, you can gain instruction in how to implement and customize the solution by reviewing the other sections that present the sample data and underlying SQL code for making the approach work.
Demonstrations of one-way and two-way tabulations with R
Here’s a series of simple examples from the DataCamp website of how to use R for one-way and two-way tabulations with a popular data science dataset named Cars93. These examples illustrate how easy it is to specify one-way and two-way tabulations with the R language.
You can specify the data to be processed in R with code like this. Notice how just two lines of code designate a data source and enumerate the Type values for all 93 data rows in the Cars93 dataset. The code even returns a list of distinct Type values at the bottom of the display.
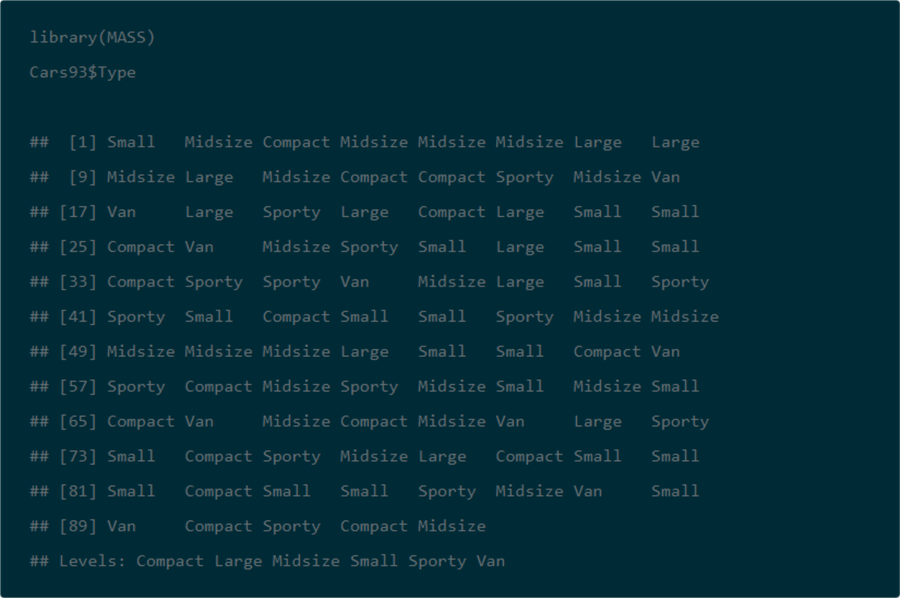
Here’s an example of how just one line of R code generates a one-way horizontal tabulation of Type values from the Cars93 dataset.
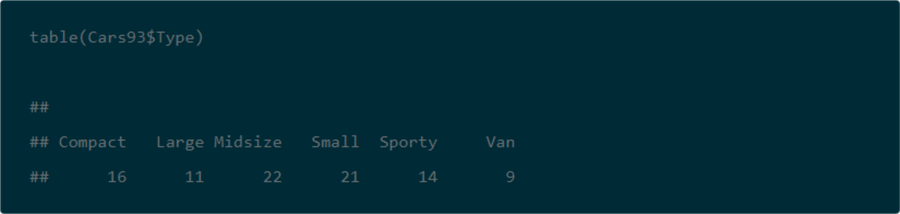
Here’s another line of R code to generate a one-way horizontal tabulation of Origin values from the Cars93 dataset.
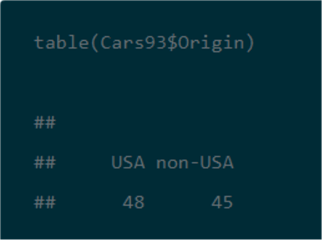
Finally, here’s an example of one line of R code for generating a two-way tabulation of Type by Origin values from the Cars93 dataset.
Data and analysis plan for the tip
This tip uses the classic data science dataset named Cars93; the dataset ships with the R language package. This tip downloads the dataset from this resource. This tip’s analysis plan is based on both the part 1 tip “Contingency Table Analysis via Chi Square with SQL: Part 1“) in this two-part series and a prior article on the DataCamp website. The Cars93 dataset is a very widely used dataset for statistical analysis demonstrations; see these references for examples (here and here).
This tip limits its focus to one-way and two-way tabulations for selected categories in the Cars93 dataset, but the stored procedures are believed to be applicable without modification to any set of categories in any dataset. In general, a tabulation is a count of observed category values, such as number of cars by origin (USA or non-USA) or type of car (Compact, Large, Midsize, Small, Sporty, Van). Tabulations are only appropriate for variables that are categorized. Tabulations are not appropriate when processing a continuous variable such as car weight, unless weight is categorized into a set of categories, such as less than or equal to 2,500 pounds, greater than 2,500 and less than or equal to 3,500 pounds, and greater than 3,500 pounds).
- A one-way tabulation is a popular tool for performing exploratory data analysis. This kind of tabulation counts observed value instances within a dataset by one set of category values. For example, the count of cars by manufacturer. Database developers can think of one-way tabulations as a form exploratory data analysis because the tabulations can highlight errors in a data source. In fact, this tip highlights an issue with the Cars93 dataset. I am guessing the issue is in Cars93 on purpose so that those analyzing the dataset can gain experience in how to discover a data issue. In any event, I found the error in other published versions of the dataset.
- A two-way tabulation or contingency table counts the observations classified by each of two distinct pairs of category values, such as Type and Origin. If Type has six distinct category values and Origin has two distinct category values, the contingency table for Type by Origin has twelve cells; this number of cells is the outcome of crossing each of the six Type category values with each of the two Origin category values.
The subset of Cars93 categories used in this tip to test code include: Origin, Type, Manufacturer, DriveTrain, and Man.Trans.Avail. Notice that not all these category names are consistent with SQL Server column naming conventions. In particular, the Man.Trans.Avail category name is consistent with a SQL Server three-part name, but the whole name really references a single column in the Cars93 dataset — not the avail table in the trans schema of the Man database.
Transferring data from a csv file to a SQL Server table
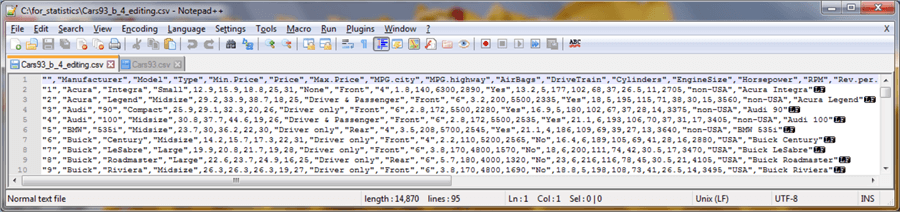
As covered in the preceding section, the data for this tip can be downloaded from one of several sources where you can obtain the Cars93 dataset as a csv file. For your convenience, one of these sources is in the download file with this tip. The following screen shot displays the first ten of ninety-four rows from the csv file. The original downloaded Cars93.csv file is renamed Cars93_b_4_editing.csv within this tip.
- The first row contains the field names for the columns in the Cars93 dataset as it is available from this resource. Notice that the first column in the first row specifies a blank column name (“”). The rows following the first row show the first column is an identity column that starts with a value of 1 and increments by one for each successive row.
- Also, one column of integer values (Cylinders) has its values embraced by double quote marks and other columns of integer values are not embraced by double quote marks.
- Fields with alphabetical values are consistently embraced in quotes.
- Finally, notice that each line ends with a linefeed designator.
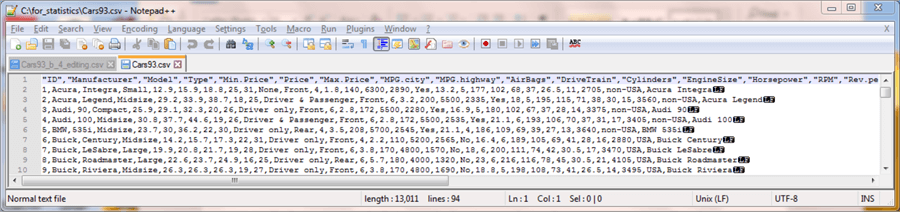
Some minor editing was performed on the raw csv file to make it an easy and familiar one to import into a SQL Server table. The following screen shot shows the edited version of the downloaded file, which has the name Cars93.csv.
- The name ID is assigned to the first column in the first row.
- Double quote marks are removed from all field values starting in row 2 through the end of the file.
The Cars93.csv file can help create and populate a SQL Server table by either of two different stored procedures which are nearly the same. Both stored procedure versions create and populate a temporary table named ##temp_clean.
- The load_contingency_table_source_data_wo_ManTransAvail_fix stored procedure contains a minimal amount of code for getting the Cars93.csv data file into SQL Server for processing.
- The load_contingency_table_source_data_w_ManTransAvail_fix stored procedure contains nearly the same code as in the first one – except that it assigns an alias to one column from the csv file. The alias allows the column to be processed from within SQL Server. Without the name change, the source for the column is incorrectly specified for a SQL Server column.
- This tip provides a separate stored procedure for each version of the ##temp_clean table. You can update the stored procedure with the fix for manual transmission availability as required for cleaning other columns. As additional cleaning becomes necessary, you can either modify the load_contingency_table_source_data_w_ManTransAvail_fix stored procedure or prepare another stored procedure that populates the ##temp_clean global table with the most recently cleaned Cars93 dataset.
The script_to_create_load_contingency_table_source_data_wo_ManTransAvail_fix.sql file is for the first stored procedure; the SQL script file is available for download with this tip. This script file has four code segments. The segments are separated from one another by horizontal lines comprised of dashes (-). The file appears in the following script window.
The initial segment drops the load_contingency_table_source_data_wo_ManTransAvail_fix stored procedure if it already exists in the database context.
- The segment commences with a use statement for the AllNasdaqTickerPricesfrom2014into2017 database. You can replace this database name with the name of any other existing database you prefer.
- Then, a try…catch block removes the load_contingency_table_source_data_wo_ManTransAvail_fix stored procedure if it already exists.
The second segment creates a SQL Server table based on the contents of the Cars93.csv file.
- This segment commences with a create procedure statement. This statement assigns a name (load_contingency_table_source_data_wo_ManTransAvail_fix) to the stored procedure.
- A local temp table named #temp is used in the third segment to store a string image of the column contents of the csv file.
- There are twenty-eight columns in the Cars93.csv file – one to uniquely identify rows (ID) and twenty-seven more columns for variables in the Cars93 dataset.
- The ID column is specified as an int data type. You can change the data type to bigint if you require more rows for a dataset, but sample data science datasets are rarely extraordinarily large.
- Each of the remaining columns is designated as a varchar data type with a maximum length of fifty characters.
- Aside from the ID column, no distinctive data types are assigned to columns based on their contents at this stage in the import process. Distinctive data types based on column contents are assigned in the fourth segment.
The third segment uses a bulk insert statement to transfer the contents of the Cars93.csv file to the #temp table. The bulk insert statement relies on four parameters in this tip.
- The from parameter designates the file name and path for the sample dataset’s csv file used in this tip.
- The firstrow parameter designates a row number for the first row with data to transfer.
- The fieldterminator parameter designates the delimiter separating the value in one column from a following column.
- The rowterminator parameter designates the parameter separating each row of column values from a following row or a null row when there is no more data. The ‘0x0a’ assignment to the parameter indicates that lines end with a linefeed character. This type of csv rowterminator is more common for UNIX and Linux systems than for Windows systems. See this prior tip for a more focused demonstration on different types of rowterminator parameter values for the bulk insert statement.
The fourth segment converts the string values in the #temp local temp table into the ##temp_clean global temp table with distinctive data types for the values in each column. Recall all the columns in the #temp table except for the ID column all have a varchar data type. The use of a global temp table makes the values from the table outside the scope of the stored procedure.
- The code in this segment references the #temp table in the from clause of a select statement.
- The select list items contain conversions, if necessary, for a column’s values.
- The into operator just before the from clause denotes an output table (##temp_clean) in which to store transferred, and converted if necessary, column values from #temp table.
- When the column name and data type is not modified, then the data type for the column matches the data type in the #temp table.
- Columns with a numeric value but no decimal point are converted to an int data type with a cast statement.
- Columns with a numeric value and a decimal point are converted to a float data type with a cast statement.
- For selected columns, such as those with an NA in one or more rows, a case statement replaces NA values with NULL values.
- For the Cylinders column, a case statement transforms a row with a value of rotary to NULL; there are no cylinders in a rotary engine. Just one row in the Cylinders column of the dataset has a rotary value; this row is for the Mazda RX-7.
- The next-to-last statement in the fourth segment displays the transformed data from the ##temp_clean table. You can at your option uncomment a preceding line to display the untransformed data in the #temp table.
- The last statement in the script file is go. This statement activates the create procedure statement at the start of the second segment and creates the stored procedure in the current database.
use AllNasdaqTickerPricesfrom2014into2017
go
begin try
drop procedure load_contingency_table_source_data_wo_ManTransAvail_fix
end try
begin catch
print 'load_contingency_table_source_data_wo_ManTransAvail_fix not available to drop'
end catch
go
----------------------------------------------------------------------------------------------
CREATE PROCEDURE load_contingency_table_source_data_wo_ManTransAvail_fix
as
-- create fresh copy of #temp with varchar fields
-- except for ID int column
begin try
drop table #temp
end try
begin catch
print '#temp not available to drop'
end catch
create table #temp(
ID INT
,Manufacturer varchar(50)
,Model varchar(50)
,Type varchar(50)
,"Min.Price" varchar(50)
,"Price" varchar(50)
,"Max.Price" varchar(50)
,"MPG.city" varchar(50)
,"MPG.highway" varchar(50)
,"AirBags" varchar(50)
,"DriveTrain" varchar(50)
,"Cylinders" varchar(50)
,"EngineSize" varchar(50)
,"Horsepower" varchar(50)
,"RPM" varchar(50)
,"Rev.per.mile" varchar(50)
,"Man.trans.avail" varchar(50)
,"Fuel.tank.capacity" varchar(50)
,"Passengers" varchar(50)
,"Length" varchar(50)
,"Wheelbase" varchar(50)
,"Width" varchar(50)
,"Turn.circle" varchar(50)
,"Rear.seat.room" varchar(50)
,"Luggage.room" varchar(50)
,"Weight" varchar(50)
,"Origin" varchar(50)
,"Make" varchar(50)
)
----------------------------------------------------------------------------------------------
-- cars93.csv is downloaded from:
-- https://forge.scilab.org/index.php/p/rdataset/source/tree/master/csv/MASS/Cars93.csv
-- manual modifications to downloaded csv file
-- convert first column designator from "" to "ID" in first row
-- remove double-quote delimiters for column values in second through ninety-fourth rows
-- data file rows terminate with line feed character only as in Unix and Linux
-- so rowterminator is set to '0x0a'
bulk insert #temp
from 'C:\for_statistics\cars93.csv'
with
(
firstrow = 2
,fieldterminator = ','
,rowterminator = '0x0a'
)
----------------------------------------------------------------------------------------------
-- create fresh copy of ##temp_clean
begin try
drop table ##temp_clean
end try
begin catch
print '##temp_clean not available to drop'
end catch
-- cleaned #temp table into #temp_clean with
-- int and float assignments for fields with numbers
-- text catches for NA and rotary in
-- Cylinders, [Rear.seat.room], [Luggage.room] columns
select
ID
,Manufacturer
,Model
,Type
,cast([Min.Price] as float) [Min.Price]
,cast(Price as float) Price
,cast([Max.Price] as float) [Max.Price]
,cast([MPG.city] as int) [MPG.city]
,cast([MPG.highway] as int) [MPG.highway]
,AirBags
,DriveTrain
,
case
when [Cylinders] = 'rotary' then NULL
else cast([Cylinders] as int)
end [Cylinders]
,cast(EngineSize as float) EngineSize
,cast(Horsepower as int) Horsepower
,cast(RPM as int) RPM
,cast([Rev.per.mile] as int) [Rev.per.mile]
,[Man.trans.avail] -- notice the original column name is retained
,cast([Fuel.tank.capacity] as float) [Fuel.tank.capacity]
,cast(Passengers as int) Passengers
,cast(Length as int) Length
,cast(Wheelbase as int) Wheelbase
,cast(Width as int) Width
,cast([Turn.circle] as int) [Turn.circle]
,
case
when [Rear.seat.room] = 'NA' then NULL
else cast([Rear.seat.room] as float)
end [Rear.seat.room]
,
case
when [Luggage.room] = 'NA' then NULL
else cast([Luggage.room] as int)
end [Luggage.room]
,cast(Weight as int) Weight
,Origin
,Make
into ##temp_clean
from #temp
-- echo original source data and cleaned data
-- primarily for clarifying input data processing
--select * from #temp
select * from ##temp_clean
goAs mentioned, one of the five Cars93 fields used in this tip for unit testing is not designated correctly as a SQL Server column name. The default field name is Man.Trans.Avail. This field name needs to be updated in a way so that it does not reference a field named avail in the trans schema of the Man database. One way to accomplish this is to assign an alias to the field named ManTransAvail. The alternative name transforms the field name from one pointing at a particular schema in a particular database to one pointing at a field name in the same default database and schema as the other fields used for unit testing. There are other original Cars93 field names that need the same kind of fixing for processing within SQL Server, but these fixes are outside the scope of this tip because they are not used for unit testing in this tip.
In order to demonstrate easily the consequences of the fix for the field name, it is convenient to create a second stored procedure that is identical to the original stored procedure, except for the ManTransAvail alias assigned to the Man.Trans.Avail field. The second stored procedure is the same as the original one with two exceptions.
- First, the second stored procedure has a different name. The new name is load_contingency_table_source_data_w_ManTransAvail_fix instead of load_contingency_table_source_data_wo_ManTransAvail_fix.
- Next, the second stored procedure assigns an alias to the Man.Trans.Avail field from the #temp table when its alias is assigned in the ##temp_clean table.
- For your easy reference, these two changes are persisted in the script_to_create_load_contingency_table_source_data_w_ManTransAvail_fix.sql file, which is available for download with this tip. You can run this script file to create a copy of the load_contingency_table_source_data_w_ManTransAvail_fix stored procedure in a database of your choice.
SQL one-way tabulation demonstrations
The following script is an excerpt from the “Compute_horizontal_tab before_and_after_column_fix” SQL file. The script presents a demonstration of a SQL-based approach for creating one-way tabulations from a temporary table named ##temp_clean. The tabulations are for five category variables with named: Origin, Type, Manufacturer, DriveTrain, and Man.Trans.Avail. All five of these names point to columns in the Cars93.csv file.
The script has two main parts.
- First, it loads a cleaned version of the Cars93.csv file into the ##temp_clean table. The script invokes the load_contingency_table_source_data_wo_ManTransAvail_fix stored procedure to accomplish this goal.
- Second, the script successively invokes the Compute_horizontal_tab stored procedure for each of the five category variables used for unit tests. As you can see, the category variable name is passed to the stored procedure as a string variable; single quote marks after the stored procedure name embrace the category variable name for a one-way tabulation.
-- load first version of cleaned data
-- ##temp_clean must be populated from the sample dataset file (Cars93.csv)
-- prior to invoking this script
exec load_contingency_table_source_data_wo_ManTransAvail_fix
-- before Man.trans.avail column rename fix
exec Compute_horizontal_tab 'Origin'
exec Compute_horizontal_tab 'Type'
exec Compute_horizontal_tab 'Manufacturer'
exec Compute_horizontal_tab 'DriveTrain'
exec Compute_horizontal_tab 'Man.Trans.Avail'After running the preceding script in SQL Server Management Studio (SSMS), the Messages tab shows the following message.
- The reason SSMS opens to the Messages tab is to alert the user to the fact Man.Trans prefix does not match a table name or alias used in the query.
- As a consequence, SSMS does not show a results tab for the Man.Trans.Avail category name in the Results tab.
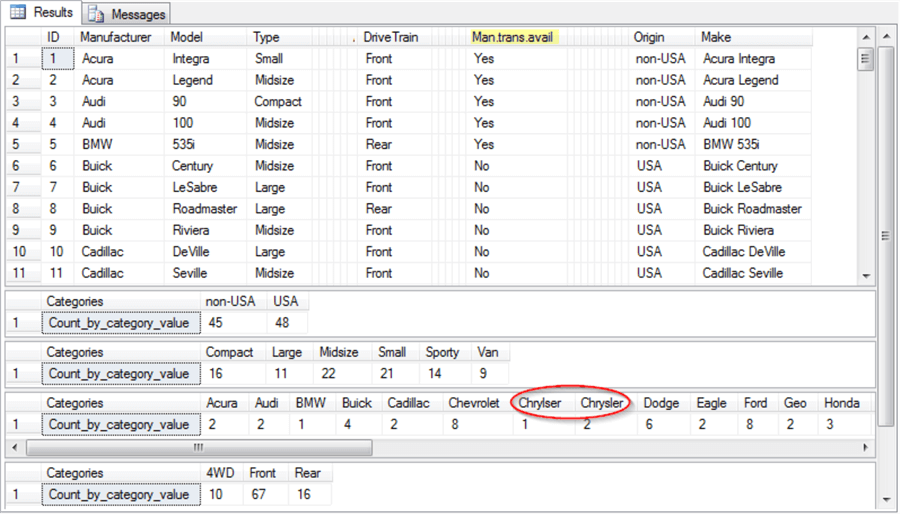
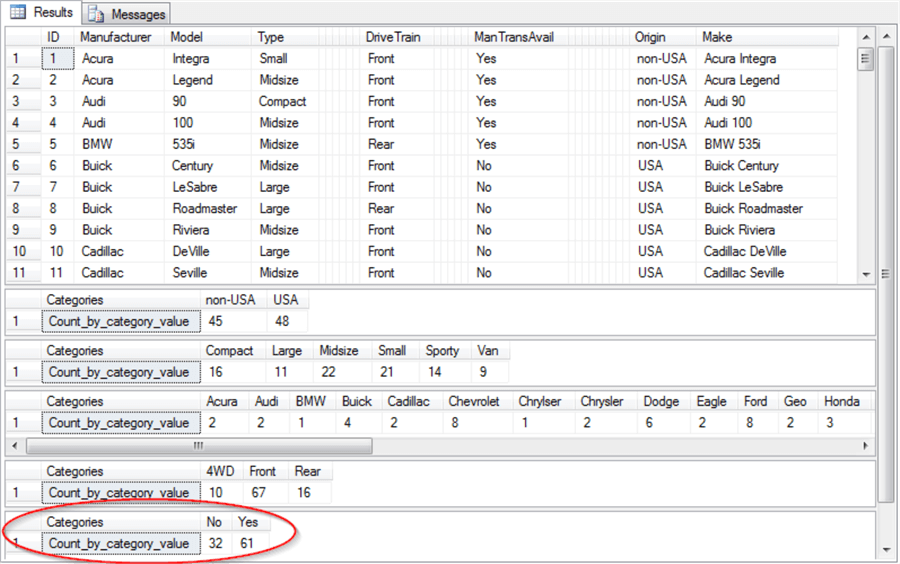
The next screen shot shows an excerpt of the output in the Results tab from running the preceding script. There are two main types of output from the script.
- First, you can view the initial eleven data rows for selected columns from the ##temp_clean table.
- There is a total of ninety-three data rows in the first result set.
- Also, note that the Man.trans.avail column is highlighted. The highlighting is manually added by a screen editing tool to confirm that the column exists in the ##temp_clean table. The code can list the set of columns (*) in the ##temp_clean table. However, as the preceding screen shot confirms, SQL code cannot separately reference the Man.Trans.Avail column in the table because of the column’s name.
- The remaining columns showing for the ##temp_clean table are either columns used as input to the Compute_horizontal_tab stored procedure for the computation of a one-way tabulation or identifier fields, such as ID, Model, or Make.
- Next, there are four more result sets – one for each of the category variables in the unit test with a legitimate SQL Server column name. The result sets for categories appears in the order that they are referenced when invoking the Compute_horizontal_tab stored procedure.
- The Origin category has just two category values: non-USA and USA.
- There are six Type category values. Some of these (Compact, Large, Midsize, and Small) appear in the initial eleven rows of the ##temp_clean table; other categories (Sporty and Van) do not appear in the first eleven rows.
- The Manufacturer category has a data issue that the one-way tabulation makes evident: a red ellipse is around two column names that are nearly identical. The category name values are: Chrylser and Chrysler. Because there is no car manufacturer with a name of Chrylser, this category name value is likely a typo which should be spelled as Chrysler.
- The last result set is for the DriveTrain category. The result set shows three categories (4WD, Front, and Rear) – two of which appear in the first eleven rows of the ##temp_clean table.
The next code listing displays the SQL code to return result sets for all five category variables after the assignment of an alias of ManTransAvail to the ##temp_clean column with an original name of Man.Trans.Avail.
- The alias is assigned to the Man.Trans.Avail by invoking the load_contingency_table_source_data_w_ManTransAvail_fix stored procedure. The stored procedure is described towards the end of the preceding section. A script to create the stored procedure in a database of your choice is available as a download with this tip.
- The last line in the script below invokes the Compute_horizontal_tab stored procedure with an argument of ‘ManTransAvail’. This argument references the ManTransAvail alias for the Man.Trans.Avail column in the Cars93 dataset.
-- load second version of cleaned data
-- ##temp_clean must be populated from the sample dataset file (Cars93.csv)
-- prior to invoking this script
exec load_contingency_table_source_data_w_ManTransAvail_fix
-- after Man.trans.avail column rename
exec Compute_horizontal_tab 'Origin'
exec Compute_horizontal_tab 'Type'
exec Compute_horizontal_tab 'Manufacturer'
exec Compute_horizontal_tab 'DriveTrain'
exec Compute_horizontal_tab 'ManTransAvail'The next screen shot shows the output from the preceding script. This script did not open in SSMS to the Messages tab because there was no critical error message. The Results tab appears below.
- This script starts by invoking the load_contingency_table_source_data_w_ManTransAvail_fix stored procedure. It is also worth noting that the ManTransAvail column appears in the first result set showing an excerpt for the first eleven rows of ##temp_clean table.
- A main point of the screen shot is to show that a result set appears for the column with an alias of ManTransAvail; the result set is encircled by a red ellipse. This is the last result set for the category variables because it is for the last category variable name passed to the Compute_horizontal_tab stored procedure.
- The misspelling for the Chrylser category variable is not corrected. This misspelling is not critical for this tip, except to demonstrate that you can readily identify data errors with horizontal tabulations.
Code and process review for Compute_horizontal_tab stored procedure
This section examines the structure and operation of the Compute_horizontal_tab stored procedure. This stored procedure is important for several reasons.
- First, it computes the one-way tabs reported in the preceding section.
- Second, the stored procedure accepts a parameter name for a category. Therefore, it operates dynamically based on the parameter value.
- Third, it computes the category value names within a category. After accepting the name of a category as a parameter, the stored procedure dynamically enumerates distinct category value names within the category. For example, when the category name is Origin, the category value names are non-USA and USA, but when the category name is Type, the category value names are Compact, Large, Midsize, Small, Sporty, and Van.
- Fourth, it computes the count of category values within a category across rows in the data source.
This tip provides a script for generating each stored procedure used in it. By using a script to the generate a stored procedure, you can just edit the script to designate a database to contain the stored procedure, and then run the whole script to create the stored procedure in the designated database. The script file to create the Compute_horizontal_tab stored procedure is available as a download with this tip. The file’s name is script_to_create_Compute_horizontal_tab.sql.
The script file for the Compute_horizontal_tab stored procedure has four major segments that are divided by horizontal comment lines in the following listing.
- The first segment clears any prior version of the Compute_horizontal_tab stored procedure from the current database.
- First, a use statement sets the database context for the current database. This tip uses the AllNasdaqTickerPricesfrom2014into2017 database, but you can change the database name to point at any other existing database of your choice on the SQL Server instance from which you are running the script.
- Second, a try…catch block eliminates any prior version of the Compute_horizontal_tab stored procedure in the database that you designate to contain the stored procedure.
- The main goal of the second segment is to create and populate a fresh copy of the ##category_name_values global temporary table with the category values for the category name passed to the Compute_horizontal_tab procedure.
- The segment commences with a create procedure statement for the Compute_horizontal_tab stored procedure, which is followed immediately by a parameter name (@category_name) to accept the value of the category name passed to the procedure.
- The @sqlstring variable is declared with a varchar type. This local variable holds the dynamic SQL to enumerate the category value names within the @category_name category.
- Next, any prior version of the ##category_name_values table is dropped.
- Then, a set statement assigns the dynamic SQL to the @sqlstring variable. The SQL statement composed by the script can derive the distinct category value names in the @category_name category.
- The final statement in the second segment executes the dynamic SQL in the @sqlstring local variable. The execution of the dynamic SQL populates a fresh copy of the ##category_name_values table for the @category_name parameter passed to the stored procedure.
- The third segment populates a fresh copy of two local variables after an update to the column values in the ##category_name_values table. These two local variables are used in the fourth and final segment of the stored procedure.
- The segment begins with an update statement that adds leading and trailing brackets ([]) to values in the ##category_name_values table. These brackets allow the code to accommodate processing of column values that have special characters, such as “-” in non-USA for one of the Origin category name values.
- The first local variable named @category_name_values contains a comma separated list of the values from the ##category_name_values table.
- The second local variable named @csv_list_of_category_names adds leading and trailing parentheses to the comma separated list in the @category_name_values local variable.
- The fourth segment uses the @category name parameter along with the @category_name_values and @csv_list_of_category_names local variables to specify dynamic SQL in the @sqlstring local variable for counting the category name values for the category name passed to the Compute_horizontal_tab stored procedure. The dynamic SQL relies on a pivot operator to display the category value names and their counts in a horizontal orientation. These pivoted category value counts appear in the preceding screen shot.
use AllNasdaqTickerPricesfrom2014into2017
go
begin try
drop procedure Compute_horizontal_tab
end try
begin catch
print 'Compute_horizontal_tab not available to drop'
end catch
----------------------------------------------------------------------------
go
create procedure Compute_horizontal_tab
-- Add the parameters for the stored procedure here
@category_name varchar(30)
as
begin
-- SET nocount on added to prevent extra result sets from
-- interfering with SELECT statements.
set nocount on;
-- Insert statements for procedure here
declare @sqlstring varchar(max);
-- ##category_name_values is a global temp table for distinct
-- category name values in brackets
begin try
drop table ##category_name_values
end try
begin catch
print '##category_name_values not available to drop'
end catch
set @sqlstring =
'select distinct '
+
'['+ @category_name + ']'
+
' category_name_value into ##category_name_values from ##temp_clean'
exec (@sqlstring)
----------------------------------------------------------------------------
-- add brackets before and after category name values
-- in the ##category_name_values table
-- to accommodate special characters, such as "-" embedded
-- in category name values
update ##category_name_values
set category_name_value = '['+category_name_value+']'
-- contents of ##category_name_values after update to
-- add before/after brackets for category name values
-- select * from ##category_name_values
-- extract category name values from ##category_name_values
-- into @category_name_values variable with commas
-- between category value names and then into
-- @csv_list_of_category_names with leading and trailing parentheses
declare @category_name_values varchar(max), @csv_list_of_category_names varchar(max)
select
@category_name_values =
coalesce(@category_name_values + ', ' ,'')
+
category_name_value
from ##category_name_values
select @csv_list_of_category_names = '(' + @category_name_values + ')'
----------------------------------------------------------------------------
-- construct @sqlstring for display of horizontal tab counts for
-- a categorical name values in a category name
SET @sqlstring =
'select '
+
'''Count_by_category_value ''' + ' ' + '''Categories'''
+
' ,'+@category_name_values
+
'
from
(select ID, '
+@category_name
+' from ##temp_clean) AS SourceTable
pivot
(
count(ID) -- count of ID by column category values in SourceTable
FOR '
+@category_name
+' IN '
+
@csv_list_of_category_names
+
') AS PivotTable;'
-- echo for @sqlstring to execute
-- select @sqlstring
exec (@sqlstring)
end
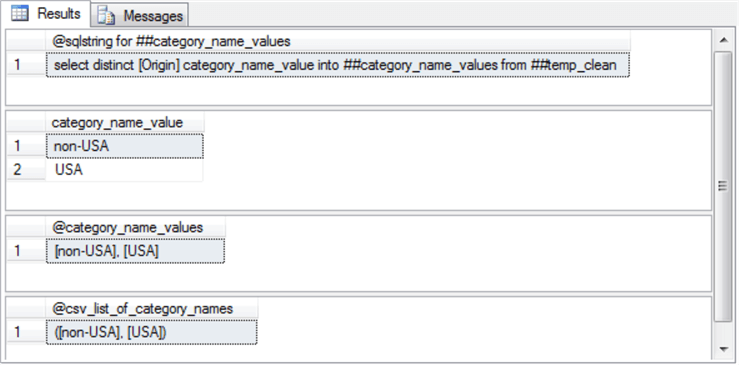
goTo help clarify the operation of the preceding script, selected intermediate outputs are presented and described next. For example, the following screen displays intermediate results generated in the operation of the second and third segments when the @category_name parameter equals Origin.
- The first result set shows the @sqlstring value for populating the ##category_name_values in the second code segment.
- The second result set displays the actual category name values that populate the ##category_name_values table.
- The third result set displays the contents of the @category_name_values local variable populated in the third segment.
- The fourth result set displays the contents of the @csv_list_of_category_names local variable populated in the third segment.
The following table shows the five category variable names (@category_name values) with their matching SQL pivot statement. The Compute_horizontal_tab stored procedure saves the SQL pivot statement in the final @sqlstring local variable assignment. The final exec statement for this @sqlstring local variable generates the horizontal tabulation for the category variable name passed to the stored procedure from dynamic SQL.
@category_name = Origin
select 'Count_by_category_value ' 'Categories',[non-USA], [USA]
from
(select ID, Origin from ##temp_clean) AS SourceTable
pivot
(
count(ID) -- count of ID by column category values in SourceTable
FOR Origin IN ([non-USA], [USA])) AS PivotTable;
@category_name = Type
select 'Count_by_category_value ' 'Categories' ,[Compact], [Large], [Midsize], [Small], [Sporty], [Van]
from
(select ID, Type from ##temp_clean) AS SourceTable
pivot
(
count(ID) -- count of ID by column category values in SourceTable
FOR Type IN ([Compact], [Large], [Midsize], [Small], [Sporty], [Van])) AS PivotTable;
@category_name = Manufacturer
select 'Count_by_category_value ' 'Categories' ,[Acura], [Audi], [BMW], [Buick], [Cadillac], [Chevrolet], [Chrylser], [Chrysler], [Dodge], [Eagle], [Ford], [Geo], [Honda], [Hyundai], [Infiniti], [Lexus], [Lincoln], [Mazda], [Mercedes-Benz], [Mercury], [Mitsubishi], [Nissan], [Oldsmobile], [Plymouth], [Pontiac], [Saab], [Saturn], [Subaru], [Suzuki], [Toyota], [Volkswagen], [Volvo]
from
(select ID, Manufacturer from ##temp_clean) AS SourceTable
pivot
(
count(ID) -- count of ID by column category values in SourceTable
FOR Manufacturer IN ([Acura], [Audi], [BMW], [Buick], [Cadillac], [Chevrolet], [Chrylser], [Chrysler], [Dodge], [Eagle], [Ford], [Geo], [Honda], [Hyundai], [Infiniti], [Lexus], [Lincoln], [Mazda], [Mercedes-Benz], [Mercury], [Mitsubishi], [Nissan], [Oldsmobile], [Plymouth], [Pontiac], [Saab], [Saturn], [Subaru], [Suzuki], [Toyota], [Volkswagen], [Volvo])) AS PivotTable;
@category_name = DriveTrain
select 'Count_by_category_value ' 'Categories' ,[4WD], [Front], [Rear]
from
(select ID, DriveTrain from ##temp_clean) AS SourceTable
pivot
(
count(ID) -- count of ID by column category values in SourceTable
FOR DriveTrain IN ([4WD], [Front], [Rear])) AS PivotTable;
@category_name = ManTransAvail
select 'Count_by_category_value ' 'Categories' ,[No], [Yes]
from
(select ID, ManTransAvail from ##temp_clean) AS SourceTable
pivot
(
count(ID) -- count of ID by column category values in SourceTable
FOR ManTransAvail IN ([No], [Yes])) AS PivotTable;
SQL two-way tabulation demonstrations
This tip utilizes a stored procedure named Compute_contingency_table for computing two-way tabulations. As with the Compute_horizontal_tab stored procedure, the new stored procedure presented in this section uses dynamic SQL and parameters to specify what dataset columns to count. The following script illustrates several examples of how to invoke the Compute_contingency_table stored procedure.
- The code references the AllNasdaqTickerPricesfrom2014into2017 database in a use statement, but you can reference any other database context so long as the Compute_contingency_table stored procedure is installed in that database. See the next section (“Code and process review for Compute_contingency_table stored procedure”) for an example of how to install the stored procedure in any existing database on a SQL Server instance.
- Additionally, you need to populate the ##temp_clean database with a sample dataset, such as Cars93. Invoking the load_contingency_table_source_data_w_ManTransAvail_fix stored procedure accomplishes this objective. The stored procedure is discussed in the “Transferring data from a csv file to a SQL Server table” section.
- You can invoke the Compute_contingency_table stored procedure by following it with the name of the row and column categories for a contingency table.
- The first pair of examples clarify this point by initially invoking the stored procedure with Type as the row and Origin as the column of a contingency table followed by a second call with Origin as the row and Type as the column of a contingency table.
- This example shows how easy this stored procedure makes rotating a contingency table.
- The remaining stored procedures calls are for contingency tables with ManTransAvail versus Origin and DriveTrain versus Origin.
- There is no example using Manufacturer because a category variable with so many category values is not often used to assess if rows are independent of columns in a contingency table.
use AllNasdaqTickerPricesfrom2014into2017
go
-- ##temp_clean must be populated with sample dataset prior
-- to invoking this script
exec load_contingency_table_source_data_w_ManTransAvail_fix
-- Pair of invocations to output a contingency table in either
-- of two orientations
-- first parameter is for the row name and the
-- second parameter is for the column name
-- there are evident differences between non-USA and USA manufactured
-- cars for Type (i.e., large cars and small cars)
exec Compute_contingency_table 'Type', 'Origin'
exec Compute_contingency_table 'Origin', 'Type'
-- Manual transmissions are more likely to be available
-- for cars manufactured outside the USA than inside the USA
exec Compute_contingency_table 'ManTransAvail', 'Origin'
-- The distribution of drive trains (4WD, Front, and Read)
-- is about the same for cars from inside and outside the USA
exec Compute_contingency_table 'DriveTrain', 'Origin'The following screen shot displays selected output from the preceding script.
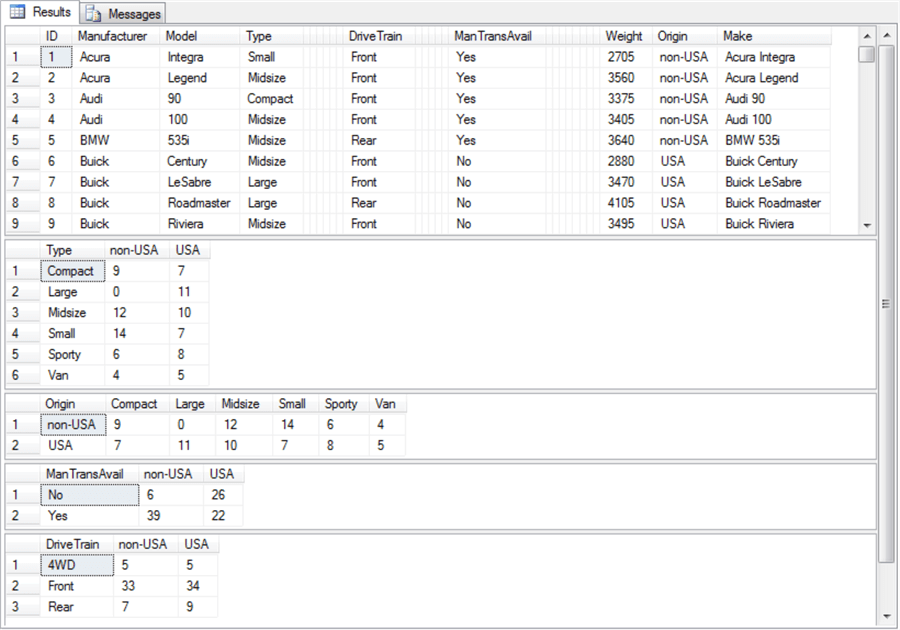
- The first result set is an echo of the ##temp_clean table from the load_contingency_table_source_data_w_ManTransAvail_fix stored procedure. It shows the first nine of ninety-three rows in Cars93 dataset. Columns not used in tabulations or for car identification are collapsed so their column names and values do not show.
- The second and third result sets are for contingency tables based of Type by Origin counts and Origin by Type counts, respectively.
- The counts for any pair of matching category values correspond to one another across both result sets. For example, the count of Compact, non-USA cars is 9 in the second result set. Similarly, the count of non-USA, Compact cars in third result set is also 9. The orientation of the counts in the second and third result sets are different, but the counts for corresponding category value pairs are the same.
- Contingency tables are useful for assessing the independence of row and column category variables. The second result set and third result set illustrate this point.
- Both result sets show that cars with a Large Type are much more likely to have a USA Origin value than a non-USA Origin value (by a ratio of 11 to 0).
- Also, cars with a Small Type are more likely to have a non-USA Origin than a USA Origin (by a ratio of 14 to 7).
- Other car Type values do not differ much by Origin value.
- The fourth result set highlights a distinction of manual transmission availability (ManTransAvail) by Origin.
- Cars with a non-USA origin are highly likely to have manual transmission available (39 versus 6).
- In contrast, cars with a USA origin have about an equal chance of having a manual transmission available as not having it available (22 versus 26).
- The fifth result set shows an example where the contingency table does not reveal any particularly large differences between cars with USA versus non-USA Origin values.
- Whether or not the contingency table shows a difference between row counts by column or vice versa is not the point. The contingency table is good for showcasing a difference if there is one.
Code and process review for Compute_contingency_table stored procedure
As with other stored procedures from this tip, a script file (script_to_create_Compute_contingency_table.sql) enables you to create a copy of the Compute_contingency_table stored procedure in a database of your choice. The file has four segments with functions that generally follow those for the Compute_horizontal_tab stored procedure. The listing below is copiously commented to make it easy for you to follow the function of lines of code. The commentary below further clarifies the objective(s) of each segment.
- The first segment has two objectives.
- It allows a developer to set the database context so that the balance of the script creates the stored procedure in a database of your choice. By default, a use statement designates AllNasdaqTickerPricesfrom2014into2017 as the database context. You can change the name to any other existing database of your choice.
- After the database context is set, the script drops any existing copy of the Compute_contingency_table stored procedure in the current database.
- The main functions of the second segment are to mark the beginning of stored procedure and populate a global table (##temp_row_id_by_col_id_ID) based on parameters passed to the stored procedure.
- The two passed parameters have names of @row_name and @column_name, which are, respectively, for the name of row and column category designators for the contingency table. Both parameters have a varchar data type with a max length of thirty characters.
- The next segment’s function is to declare two local variables and populate one of them.
- The @sqlstring local variable has a varchar data type with a max length; this local variable stores dynamic SQL code that is executed within the segment to populate the ##temp_row_id_by_col_id_ID table (as well as elsewhere throughout the stored procedure).
- The @row_id_name local variable holds a column name for the ##temp_row_id_by_col_id_ID table; the column name is ID.
- The dynamic SQL code drops the ##temp_row_id_by_col_id_ID table before populating a fresh copy of the table based on the @row_id_name local variable as well as the @column_name and @row_name parameters passed to the stored procedure. The ##temp_row_id_by_col_id_ID table is an excerpt from the ##temp_clean table.
- An exec statement at the end of the segment runs the dynamic SQL which populates the ##temp_row_id_by_col_id_ID table with data values from selected columns in the ##temp_clean table.
- The third code segment in this SQL script file performs nearly identically to the third segment in the script_to_create_Compute_horizontal_tab.sql script file. The difference for this version of the third segment is that @category_name variable is assigned the @column_name parameter value; this parameter is not available when calculating a one-way tabulation. Aside from this difference at the beginning of the segment, the balance of the third segment is a direct replica from the script_to_create_Compute_horizontal_tab.sql script file. The code declares and populates local variables named @category_name_values and @csv_list_of_category_names. These local variables hold string values used in the fourth code segment to specify dynamic SQL for populating the continency table.
- The fourth code segment specifies and executes dynamic SQL for creating and populating the contingency table.
- The dynamic SQL relies on the two passed parameters (@row_name and @column_name) to the stored procedure as well as these local variables: @row_id_name, @category_name_values, and @csv_list_of_category_names.
- A set statement assigns the dynamic SQL to the @sqlstring local variable before invoking an exec statement to run the dynamic SQL code.
- Executing the dynamic SQL generates and displays a contingency table (##temp_row_by_column_count) appearing in the preceding screen shot.
use AllNasdaqTickerPricesfrom2014into2017
go
begin try
drop procedure Compute_contingency_table
end try
begin catch
print 'Compute_contingency_table not available to drop'
end catch
go
-------------------------------------------------------------------------------
create procedure Compute_contingency_table
-- Add the parameters for the stored procedure here
-- @row_name is row name for the contingency table and
-- @column_name is column name for the contingency table
@row_name varchar(30), @column_name varchar(30)
as
begin
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering with SELECT statements.
set nocount on;
-- Insert statements for procedure here
declare
@sqlstring varchar(max)
,@row_id_name varchar(30) = 'ID'
-- this block of code saves and displays source data
-- row_id values along with column and row values
-- for the contingency table
-- ##temp_row_id_by_col_id_ID is defined as global temporary
-- table because it recurs in multiple different @sqlstring values
set @sqlstring =
'-- create fresh copy of ##temp_row_id_by_col_id_ID
begin try
drop table ##temp_row_id_by_col_id_ID
end try
begin catch
print ' + '''##temp_row_id_by_col_id_ID not available to drop'''
+ '
end catch
-- source table name is ##temp_row_id_by_col_id_ID
-- it is derived from a ##temp_clean
SELECT ' + @row_id_name + ', ' + @column_name + ', ' + @row_name
+ ' into ##temp_row_id_by_col_id_ID
FROM ##temp_clean
-- echo of ##temp_row_id_by_col_id_ID
-- select * from ##temp_row_id_by_col_id_ID'
exec (@sqlstring)
-------------------------------------------------------------------------------
-- re-use code segment from Compute_horizontal_tab stored proc
-- category_name in this stored procedure serves same role as
-- @column_name in that stored proc
declare @category_name varchar(30) = @column_name
-- ##category_name_values is a global temp table for distinct
-- category name values in brackets
begin try
drop table ##category_name_values
end try
begin catch
print '##category_name_values not available to drop'
end catch
-- preceding and trailing brackets in this script
-- are to allow all characters in @category_name values
-- into the ##category_name_values table
set @sqlstring =
'select distinct '
+
'['+ @category_name + ']'
+
' category_name_value into ##category_name_values from ##temp_clean'
exec (@sqlstring)
-- add brackets before and after category name values
-- in the ##category_name_values table
-- to accommodate special characters, such as "-" embedded
-- in category name values within the @csv_list_of_category_names variable
-- the brackets are needed for the pivot operator
update ##category_name_values
set category_name_value = '['+category_name_value+']'
-- contents of ##category_name_values after update to
-- add before/after brackets for category name values
-- select * from ##category_name_values
-- extract category name values from ##category_name_values
-- into @category_name_values variable with commas
-- between category value names and then into
-- @csv_list_of_category_names with leading and trailing parentheses
declare @category_name_values varchar(max), @csv_list_of_category_names varchar(max)
select
@category_name_values =
coalesce(@category_name_values + ', ' ,'')
+
category_name_value
from ##category_name_values
--@csv_list_of_category_names in this adaptation of code
-- is not embraced in parentheses
select @csv_list_of_category_names = '(' + @category_name_values + ')'
-------------------------------------------------------------------------------
-- dynamic SQL code to compute contingency table based on passed parameters
-- (@row_name, @column_name), subset (##temp_row_id_by_col_id_ID) of source
-- data (##temp_clean) and two local variable values computed above
-- (@category_name_values and @csv_list_of_category_names)
set @sqlstring =
'
-- create fresh copy of ##temp_row_by_column_count
begin try
drop table ##temp_row_by_column_count
end try
begin catch
print ' + '''##temp_row_by_column_count not available to drop'''
+ '
end catch
-- This is the contingency table
select ' + @row_name + ', ' + @category_name_values
+ ' into ##temp_row_by_column_count
from
(select ' + @row_name + ', ' + @column_name + ', ' + @row_id_name
+ ' from ##temp_row_id_by_col_id_ID) sourcetable
pivot
(
count(' + @row_id_name + ')
for ' + @column_name + ' IN ' + @csv_list_of_category_names + '
) pvt
order by pvt.' + @row_name + '
-- echo of ##temp_row_id_by_col_id_ID (the contingency table)
select * from ##temp_row_by_column_count'
-- echo @sqlstring for initial testing as well as future changes
-- select @sqlstring
exec (@sqlstring)
end
goThe following table presents a side-by-side comparison of the exec statement for each of the four contingency tables displayed by the script in the “SQL two-way tabulation demonstrations” section. Each of the four select statements in the following table is based on a set statement assignment to the @sqlstring local variable towards the end of the preceding script.
- The dynamically generated SQL in the set statement can generate a contingency table that resides in the ##temp_row_by_column_count table.
- The SQL statement for the contingency table has three parts.
- It initially drops any prior version of the ##temp_row_by_column_count table.
- Next, it runs a select statement with a pivot operator. The select statement pumps the result set from the select statement into the ##temp_row_by_column_count table.
- Finally, another select statement displays the contents of the ##temp_row_by_column_count table.
exec Compute_contingency_table ‘Type’, ‘Origin’
-- create fresh copy of ##temp_row_by_column_count
begin try
drop table ##temp_row_by_column_count
end try
begin catch
print '##temp_row_by_column_count not available to drop'
end catch
-- This is the contingency table
select Type, [non-USA], [USA] into ##temp_row_by_column_count
from
(select Type, Origin, ID from ##temp_row_id_by_col_id_ID) sourcetable
pivot
(
count(ID)
for Origin IN ([non-USA], [USA])
) pvt
order by pvt.Type
-- echo of ##temp_row_id_by_col_id_ID (the contingency table)
select * from ##temp_row_by_column_count
exec Compute_contingency_table ‘Origin’, ‘Type’
-- create fresh copy of ##temp_row_by_column_count
begin try
drop table ##temp_row_by_column_count
end try
begin catch
print '##temp_row_by_column_count not available to drop'
end catch
-- This is the contingency table
select Origin, [Compact], [Large], [Midsize], [Small], [Sporty], [Van] into ##temp_row_by_column_count
from
(select Origin, Type, ID from ##temp_row_id_by_col_id_ID) sourcetable
pivot
(
count(ID)
for Type IN ([Compact], [Large], [Midsize], [Small], [Sporty], [Van])
) pvt
order by pvt.Origin
-- echo of ##temp_row_id_by_col_id_ID (the contingency table)
select * from ##temp_row_by_column_count
exec Compute_contingency_table ‘ManTransAvail’, ‘ Origin ‘
-- create fresh copy of ##temp_row_by_column_count
begin try
drop table ##temp_row_by_column_count
end try
begin catch
print '##temp_row_by_column_count not available to drop'
end catch
-- This is the contingency table
select ManTransAvail, [non-USA], [USA] into ##temp_row_by_column_count
from
(select ManTransAvail, Origin, ID from ##temp_row_id_by_col_id_ID) sourcetable
pivot
(
count(ID)
for Origin IN ([non-USA], [USA])
) pvt
order by pvt.ManTransAvail
-- echo of ##temp_row_id_by_col_id_ID (the contingency table)
select * from ##temp_row_by_column_count
exec Compute_contingency_table ‘DriveTrain’, ‘ Origin ‘
-- create fresh copy of ##temp_row_by_column_count
begin try
drop table ##temp_row_by_column_count
end try
begin catch
print '##temp_row_by_column_count not available to drop'
end catch
-- This is the contingency table
select DriveTrain, [non-USA], [USA] into ##temp_row_by_column_count
from
(select DriveTrain, Origin, ID from ##temp_row_id_by_col_id_ID) sourcetable
pivot
(
count(ID)
for Origin IN ([non-USA], [USA])
) pvt
order by pvt.DriveTrain
-- echo of ##temp_row_id_by_col_id_ID (the contingency table)
select * from ##temp_row_by_column_count
Next Steps
This tip depends on several files, which are available as a download with this tip:
- Two csv files contain the Cars93 dataset before and after preliminary editing for use within this tip.
- Two SQL script files to read the Cars93 dataset while implementing different levels of data cleaning.
- Two SQL script files – one for creating a stored procedure for one-way tabulations and another for creating a stored procedure for contingency tables.
- Finally, two SQL script files for invoking stored procedures for one-way and two-way tabulations.
After installing the files in your development environment and verifying that they work as described in this tip, you should be ready to start processing your own data. Use a csv file as your source data file or just directly populate a ##temp_clean table from some alternate source, such as tables in a SQL Server database. Be sure the ##temp_clean table has an identity column named ID and document the other column names in the custom ##temp_clean based on your own data. This will allow you to compute one-way tabulation tables and two-way contingency tables for any data of your choice.
If you desire, refer to the “Contingency Table Analysis via Chi Square with SQL: Part 1” for code that can be adapted to compute a Chi Square test for independence based on your custom contingency tables.

Rick Dobson is a SQL Server professional with decades of T-SQL experience that includes authoring books, running a national seminar practice, working for businesses on finance and healthcare development projects, and serving as a regular contributor to MSSQLTips.com. He has been a practicing Python developer for more than the past half decade – with a special emphasis for data visualization and ETL tasks with JSON and CSV files. His most recent professional passions include financial time series data and analyses, AI models, and statistics. If you are interested in growing your skills in any of these areas especially as they relate to financial securities, consider visiting his blog at https://securitytradinganalytics.blogspot.com/2023/12/.
- MSSQLTips Awards: Leadership (200+ tips) – 2025 | Author of the Year Contender – 2017-2024


