Problem
Every cloud provider has a serverless interactive query service that uses standard SQL for data analysis. As for the biggest cloud providers, we have Azure Data Lake analytics, Google BigQuery and AWS Athena. Due to the fact that my company is using only AWS, I am greatly enjoying the AWS Athena service – I must say that it is awesome.
Solution
The Athena service is built on the top of Presto, distributed SQL engine and also uses Apache Hive to create, alter and drop tables. You can run ANSI SQL statements in the Athena query editor, either launching it from the AWS web services UI, AWS APIs or accessing it as an ODBC data source. You can run complex joins, use window/analytical functions and many other great SQL language features. In several cases, using the Athena service, eliminates need for ETL because it projects your schema on the data files at the time of the query.
I will show you how you can use SQL Server Management Studio or any stored procedure to query the data using AWS Athena, data which is stored in a csv file, located on S3 storage. I am using a CSV file format as an example in this tip, although using a columnar format called PARQUET is faster.
Querying Data from AWS Athena
I am going to:
- Put a simple CSV file on S3 storage
- Create External table in Athena service, pointing to the folder which holds the data files
- Create linked server to Athena inside SQL Server
- Use OPENQUERY to query the data.
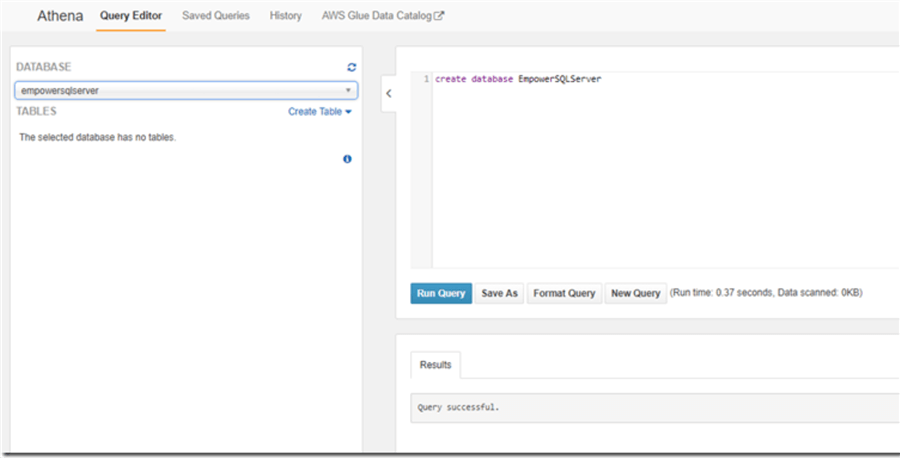
Let’s create database in Athena query editor.
As a next step I will put this csv file on S3. By the way, Athena supports JSON format, tsv, csv, PARQUET and AVRO formats.
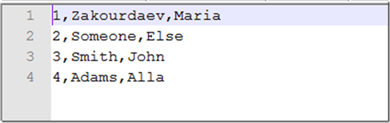
Uploading the below file to S3 bucket (don’t put a column header in the file):
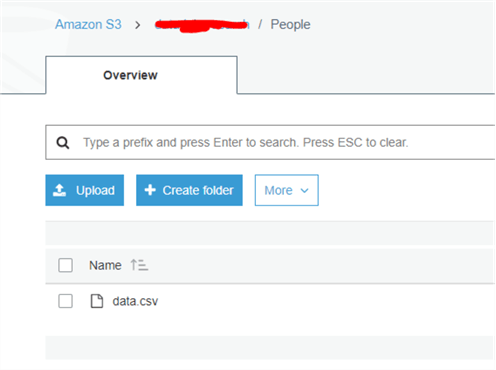
As a next step, I will go back to Athena, to create an external table over in the S3 folder. You can later add as many files as you want to the same folder and your queries will return the new data immediately, just make sure they follow the same order of columns. If in some file you want to add more columns, you will need to alter the Athena table schema definition and the query will return “NULL” values for the files that do not have new columns.
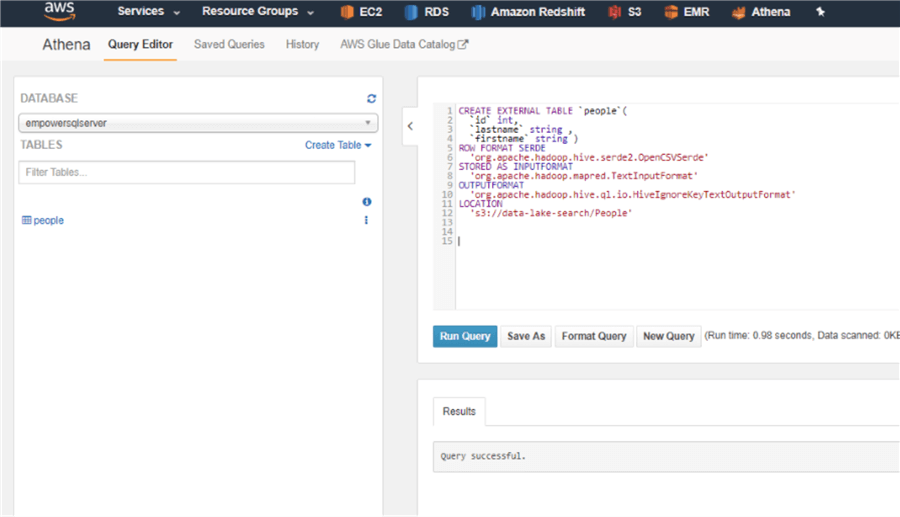
Now I can query the data through the AWS Athena UI:
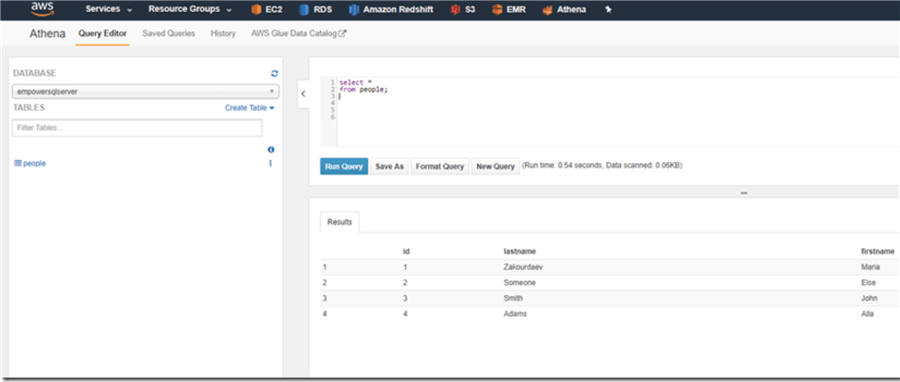

Querying Data from AWS Athena Using SQL Server Management Studio and Linked Servers
As a next step I will set up a linked server from my SQL Server instance because I would like to offload the big data querying to AWS Athena. Of course, I am using this tiny example data file, but in real life we are querying sometimes 300GB data file in a single query and the query takes just a few seconds.
Athena has an ODBC driver; I will install it on a SQL Server machine (AWS EC2 instance for this example).
Here is an installation link: https://s3.amazonaws.com/athena-downloads/drivers/ODBC/Windows/Simba+Athena+1.0+64-bit.msi.
Set up the ODBC connection. Important, click on the Authentication Option and fill in the AccessKey and SecretKey that have permissions to access the S3 bucket. The S3 output location below will hold the csv files with results from your queries. Remember to clean up the output files from time to time.
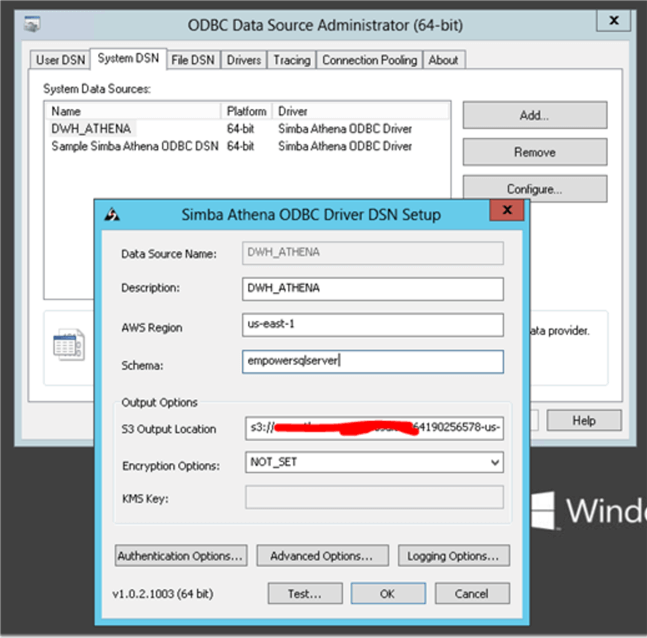
What is left, is to set up Linked Server inside Management Studio using OLEDB provider for ODBC.
EXEC master.dbo.sp_addlinkedserver @server =N'DWH_ATHENA', @srvproduct=N'', @provider=N'MSDASQL', @datasrc=N'DWH_ATHENA' GO EXEC master.dbo.sp_addlinkedsrvlogin @rmtsrvname=N'DWH_ATHENA', @useself=N'False', @locallogin=NULL, @rmtuser=N'*******', @rmtpassword='*********' GO
Replace @rmtuser and @rmtpassword with the AWS access key and secret key and now we can query the data files from any script or stored procedure.
Querying Data from AWS Athena Using SQL Server Management Studio and OpenQuery
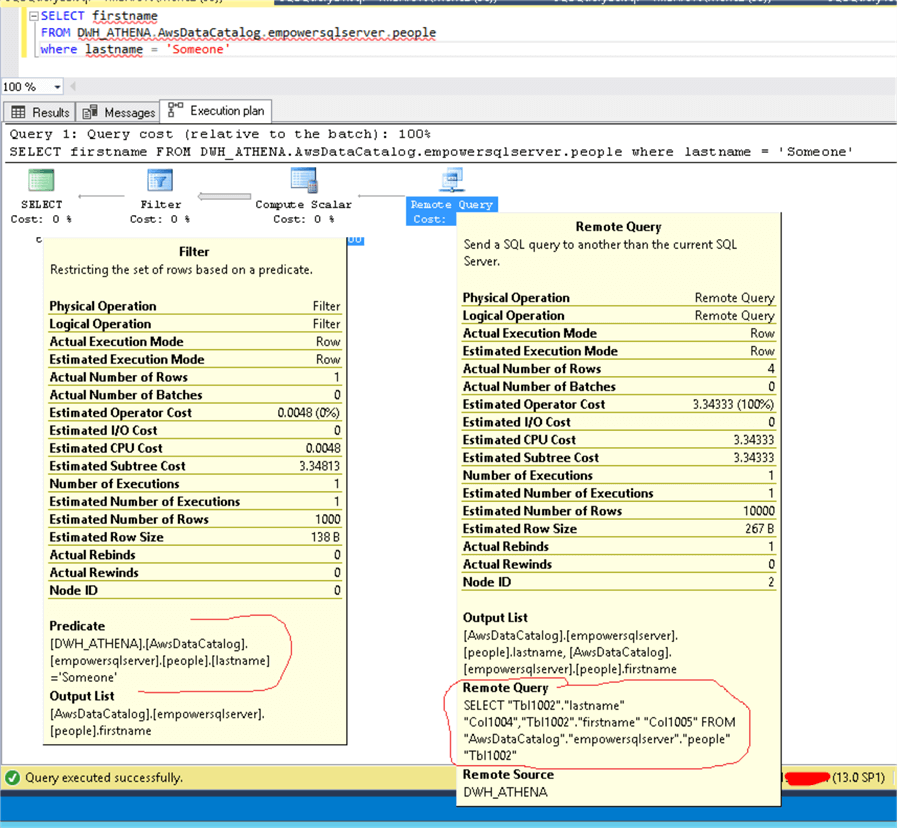
There is one very important thing that you need to know. Regular SQL Server ODBC destinations query behavior is to send “select *” to a linked server and do filtering inside SQL Server. This is very bad for us since we want to offload all work to Athena and we do not want to retrieve all table data. The way to overcome this is to use OPENQUERY.
Here is example of the query that is using a linked server. The remote query has omitted filtering and receiving ALL columns from the remote table and the filter is being applied later on, inside the “Filter” step.
The same query is using OPENQUERY instead of a linked server:
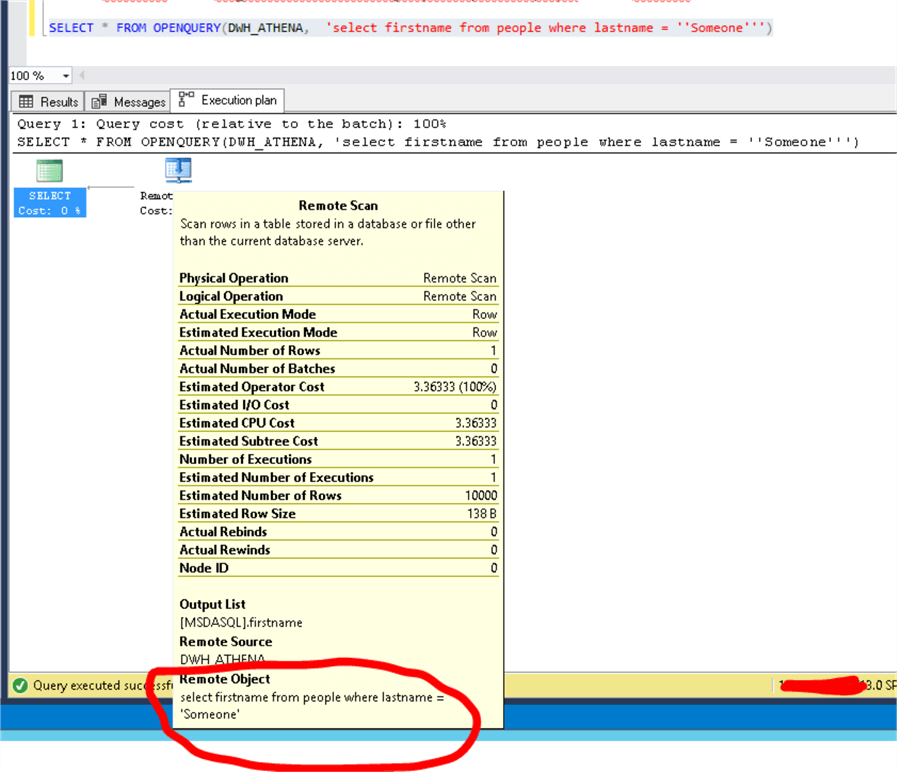
Result:
Isn’t it wonderful to be able to keep the row data in files and query them with minimal effort from SQL Server!
Next Steps
- Check out these resources:

Maria Zakourdaev is a Data Platform Microsoft MVP and a technology expert with more than 20 years of experience, a community leader with a profound knowledge of Microsoft products and services, while also being able to bring together diverse platforms, products, and solutions to solve real-world problems.
Maria has a hands-on experience managing various data management technologies in Azure, AWS and Google public cloud platforms, including SQL Server, Azure CosmosDB, AWS DynamoDB, MemSQL, MySQL, Postgresql, Snowflake, Redis, Amazon Redshift, Couchbase and Elasticsearch, Spark, Databricks, Big Query.
Maria is an organiser of the annual conference “Data TLV” ( ex “SQL Saturday Israel”), a free training event for any data professionals: http://datatlv.com.
- MSSQLTips Awards: Trendsetter (25+ tips) – 2022 | Author Contender – 2022 | Rookie Contender – 2018



Any way to query Athena from Azure SQL?
1) Partition your tables in Athena. Better performance if you have a decent amount of data
2) This means you can’t just do “select from <linkedserver>…tablename”, as that doesn’t tell Athena to do partition elimination
3) Once you’re using OPENQUERY, if you run into issues because it doesn’t know what to expect, you can use CAST or CONVERT to force metadata (aka put “cast(fielda as varchar(500))” if it thinks the field is only 255 characters.
4) That doesn’t help with over varchar(8000). You need to move to EXECUTE AT instead, but that seems better then OPENQUERY as it appears to just pass the data back – I got rid of my CASTs in the athena query. Plus, dynamic SQL is easier! You will have to enable RPC OUT for the Linked Server.
5) I couldn’t do INSERT INTO EXECUTE AT until I disabled Distributed Transactions in that Linked Server.