By: Ron L'Esteve | Comments | Related: > Azure Synapse Analytics
Problem
While Spark offers tremendous value in the advanced analytics and big data spaces, there are currently a few known limitations around indexing with Spark when compared to the SQL Server Indexing systems and processes. While Spark isn't great at b-tree indexing and single record lookups, Spark partitioning attempts to address some of these indexing limitations. However, when users query the data with a different search predicate than what was partitioned, this will result in a full scan of the data along with in-memory filtering on the Spark cluster, which is quite inefficient.
In my previous article, Getting Started with Delta Lake Using Azure Data Factory, I covered some of the benefits and capabilities of Delta Lake. While the Delta formats offer Z-ordering, which is the equivalent to a SQL Server Clustered Index, what other options do we have for non-clustered indexing in Spark in order to improve query performance as well as reduce operational overhead costs?
Solution
Microsoft recently announced a new open source indexing subsystem for Apache Spark called Hyperspace. While it is currently only partially baked at version 0.2 which only supports Spark 2.4, there is huge potential for this Spark indexing sub-system, specifically within the Azure Synapse Analytics landscape since it comes built into the Synapse workspaces.
Similar to a SQL Server non-clustered index, Hyperspace will:
- Create an index across a specified data-frame,
- Create a separate optimized and re-organized data store for the columns that are being indexed,
- Include additional columns in the optimized and re-organized data store, much like a non-clustered SQL Server index.
This article will explore creating a dataset in a Synapse workspace along with a Hyperspace Index to compare a query using hyperspace indexed vs non-indexed tables to observe performance optimizations.
Pre-Requisites
Create a Synapse Analytics Workspace:
Prior to working with Hyperspace, a Synapse Analytics Workspace will need to be created. This quick-start describes the steps to create an Azure Synapse workspace by using the Azure portal: Quickstart: Create a Synapse workspace.
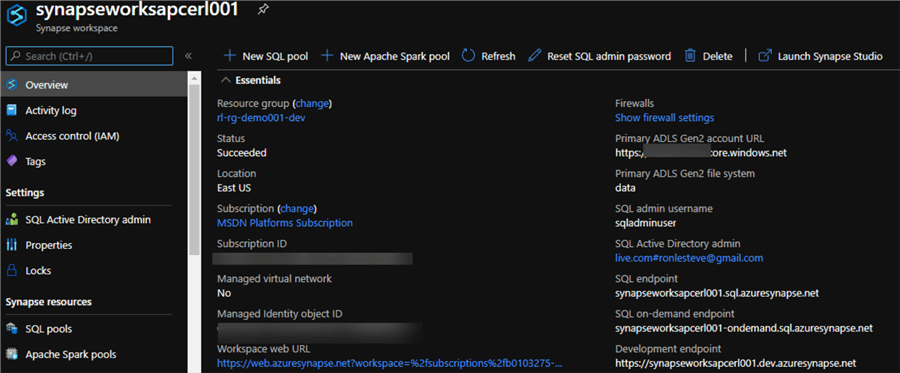
Create a Spark Pool:
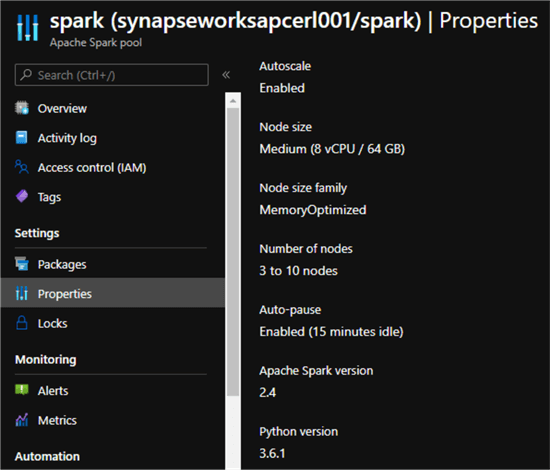
In addition to a Synapse workspace, a Spark Pool will be needed. For more information related to creating a Spark Pool, see: Quickstart: Create a new Apache Spark pool using the Azure portal.
For this demo, I have created a Medium Node size with 8 vCPU/ 64 GB.
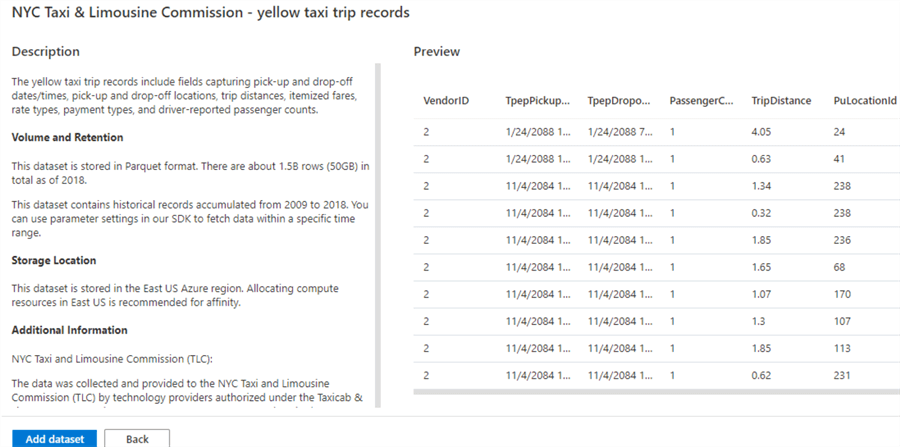
Choose a Dataset:
Finally, we'll need a dataset to work with. While big datasets are always preferable, this would come with overhead and compute costs, therefore for this demo, I have used a subset of the NYC Taxi & Limousine Commission – yellow taxi trip records. While the entire record-set spans 1.5 billion records (50GB) from 2009 to 2018, I have chosen to use a 7-month subset of the data from 2018-05-01 to 2018-05-08, which is around 2.1 million records. Note that this dataset and more is also available in the Synapse Workspace Knowledge Center.
Import a Dataset
Now that we have established our pre-requisites, the following code will import the NycTlcYellow data from Azure ML Open Datasets. There is also a parser filter for the desired dates. Finally, the code will load the data to a spark data frame.
from azureml.opendatasets import NycTlcYellow from datetime import datetime from dateutil import parser end_date = parser.parse('2018-05-08 00:00:00') start_date = parser.parse('2018-05-01 00:00:00') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) nyc_tlc_df = nyc_tlc.to_spark_dataframe()
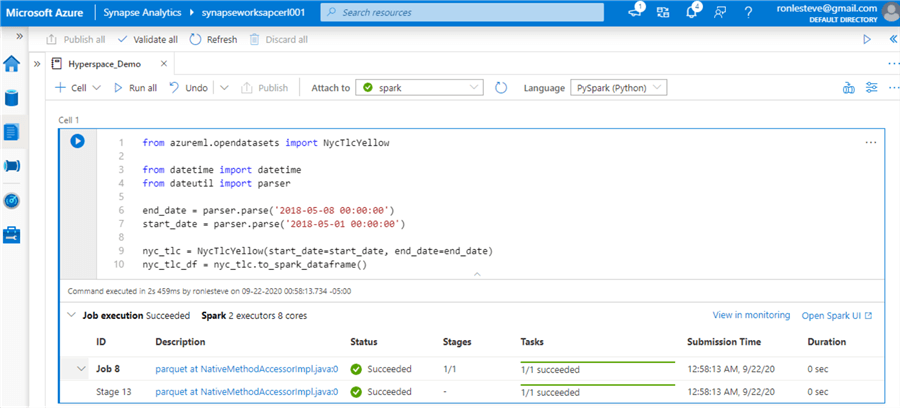
After the job succeeds, we can run a select on the VendorID column to confirm that we have approximately 2.1M records, as expected.
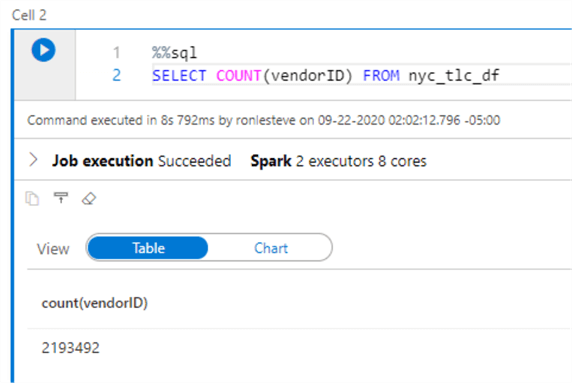
Create Parquet Files
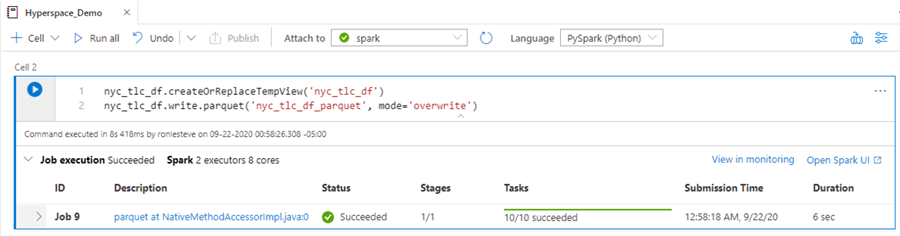
Now that we have a spark data frame containing data, the following code will create parquet files in the linked ADLS2 account.
nyc_tlc_df.createOrReplaceTempView('nyc_tlc_df') nyc_tlc_df.write.parquet('nyc_tlc_df_parquet', mode='overwrite')
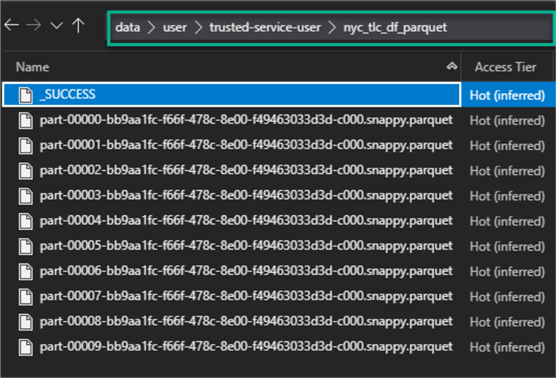
As expected, we can verify in ADLS2 that the snappy compressed parquet files have indeed been created in the nyc_tlc_df_parquet folder.
Run a Query without an Index
Next, let's run the following query on the data frame to obtain a benchmark on how long the aggregate query takes to complete.
from pyspark.sql import functions as F df = nyc_tlc_df.groupBy("passengerCount").agg(F.avg('tripDistance').alias('AvgTripDistance'), F.sum('tripDistance').alias('SumTripDistance')) display(df)
Based on the results, this query took approximately 12 seconds to execute with 2 Spark executors and 8 cores on a 2.1M data frame.
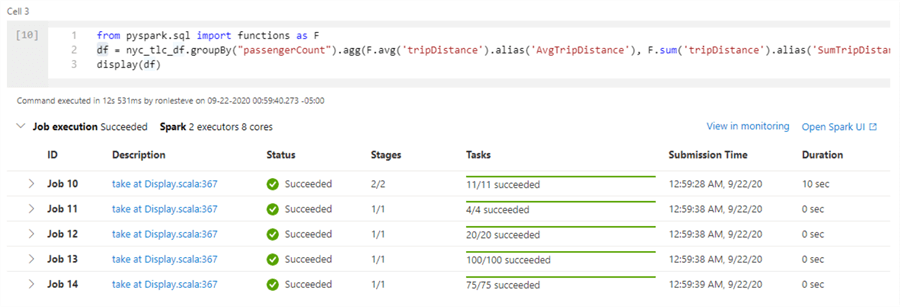
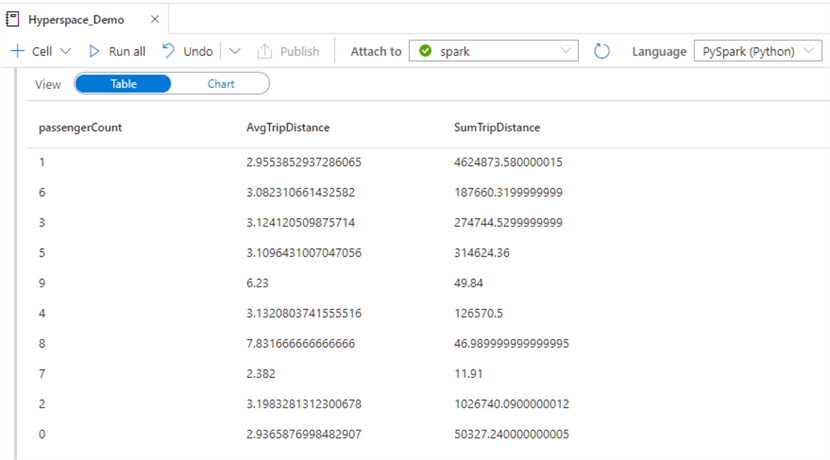
Here are the results of the query.
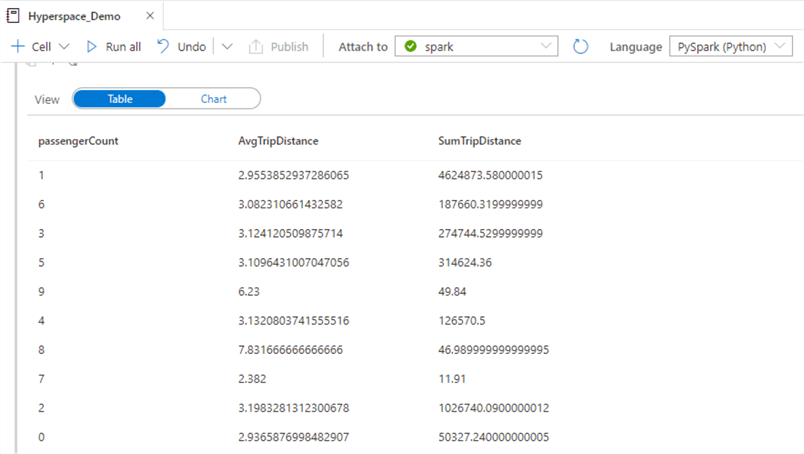
To view more details related to the query, let's open the following Spark UI.
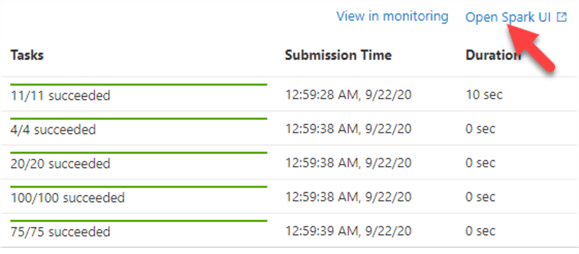
Below are the details of the Query execution. As we can see the job took approximately 11 seconds and there were no indexed tables.
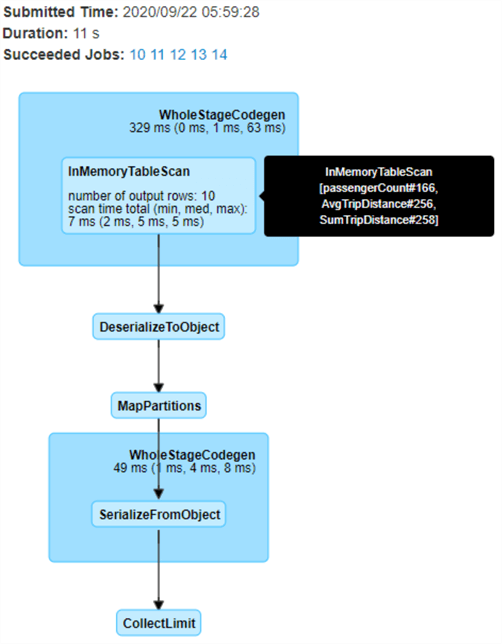
Alternatively to using the Spark UI for query execution details, you could run df.explain() in a code cell to get the details within the notebook itself.
Import Hyperspace
Now that we have established a benchmark query without any indexed tables, lets demonstrate how to get started with Hyperspace in the Synapse workspace.
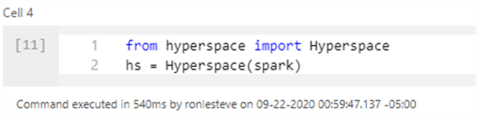
By running the following code, we will import Hyperspace.
from hyperspace import Hyperspace hs = Hyperspace(spark)
Read the Parquet Files to a Data Frame
Next, we'll need to read the parquet files into a data frame. This is because the Hyperspace Index creation process requires the source files to be stored on disk. Hopefully, with a future release, it will have the capability of also creating indexes on in-memory data frames.
df=spark.read.parquet("/user/trusted-service-user/nyc_tlc_df_parquet/")

Create a Hyperspace Index
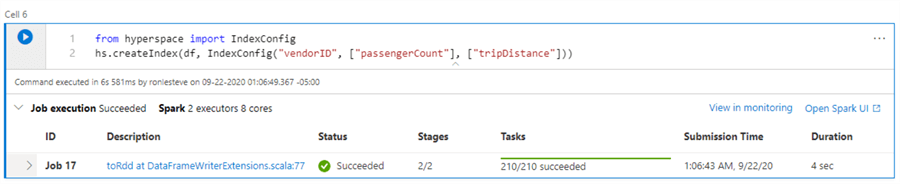
The next step is to create a Hyperspace Index with the following code. Note that VendorID is my Indexed column. Additionally, I have included two columns that have also be used in my aggregate query.
from hyperspace import IndexConfig hs.createIndex(df, IndexConfig("vendorID", ["passengerCount"], ["tripDistance"]))
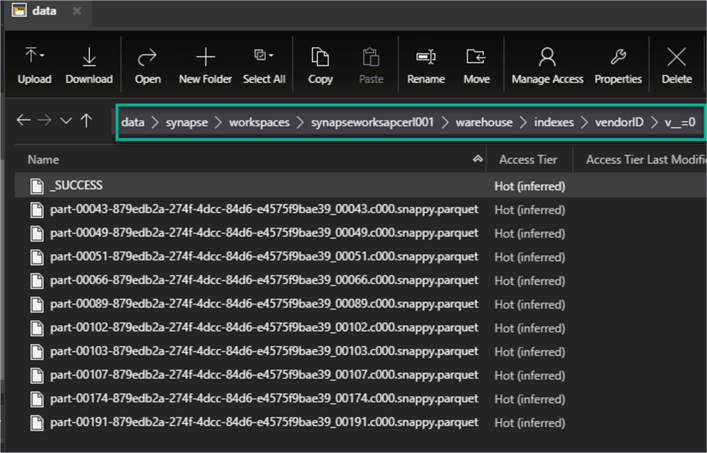
The Hyperspace Indexing sub-system will automatically create a collection of snappy compressed files in an index folder in ADLS2. While this adds additional storage overhead costs, the benefits of a performant and optimized query may outweigh the costs. Hopefully with a future release, this process can be more in-memory driven.
Re-Run the Query with Hyperspace Index
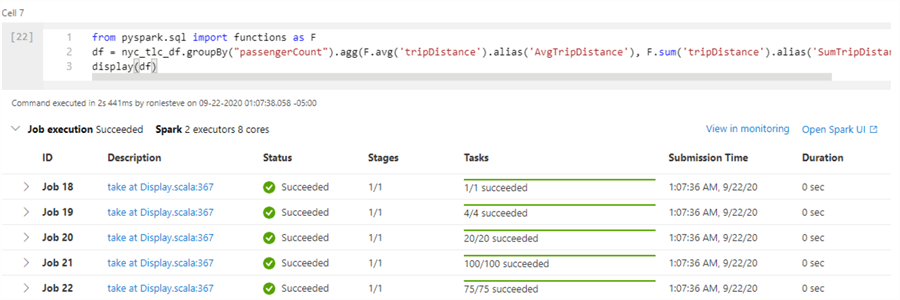
Now that we have created a Hyperspace Index, let's re-run our original query to explore the execution time and query details.
from pyspark.sql import functions as F df = nyc_tlc_df.groupBy("passengerCount").agg(F.avg('tripDistance').alias('AvgTripDistance'), F.sum('tripDistance').alias('SumTripDistance')) display(df)
This time, the query only took ~2 seconds versus the original ~12 seconds. While the performance gains are harder to notice with a relatively small 1.2M record set, the benefits will be more notable when optimizing extremely big data sets.
Once again, let's open the Spark UI to view the query details.
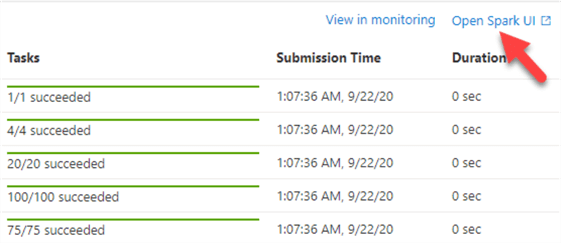
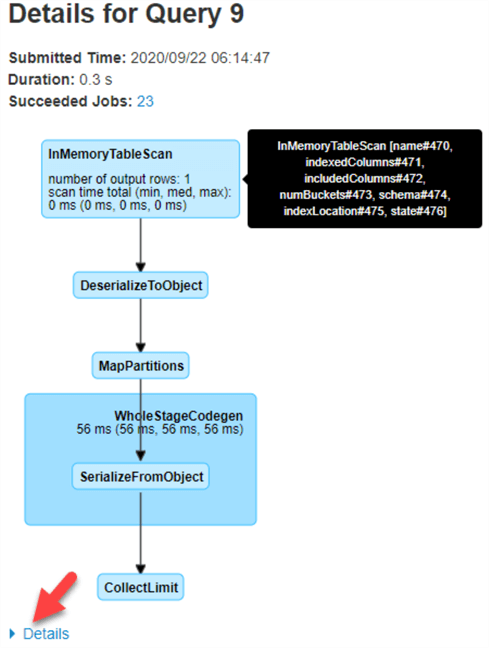
As expected, the query details show us that both the included columns and the indexed columns were used by this query.
Note also that there is an additional 'Details' section in the Spark UI to view more detail about the Query.
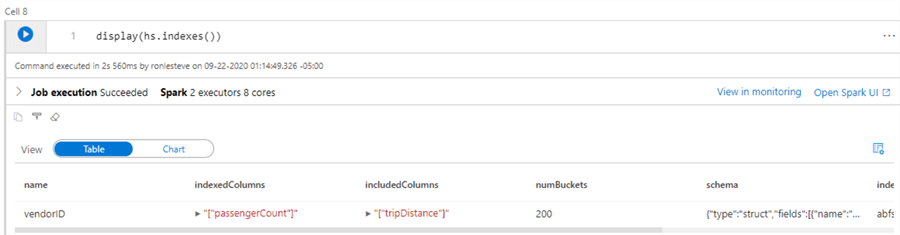
Other Hyperspace Management APIs
There are a few other Hyperspace Management APIs that can be used directly from the Synapse workspace. The following code will display the indexes.
display(hs.indexes())
Additionally, the following codes lists other APIs to refresh, delete(soft-delete), restore and vaccum(hard-delete) the Hyperspace Indexes.
// Refreshes the given index if the source data changes.
hs.refreshIndex("index")
// Soft-deletes the given index and does not physically remove it from filesystem.
hs.deleteIndex("index")
// Restores the soft-deleted index.
hs.restoreIndex("index")
// Hard-delete the given index and physically remove it from filesystem.
hs.vacuumIndex("index")
Summary
In this article, we explored how to get started with creating Spark Indexes and Azure Synapse workspace by using the Hyperspace Index Management Sub-system. For more details on Hyperspace, including benefits, future roadmap, limitations, and big data performance benchmark tests, check out, Open-sourcing Hyperspace v0.1: An Indexing Subsystem for Apache Spark.
Next Steps
- Read more about a Clustered vs Non-Clustered Index to know costs, benefits, and when to use one over the other.
- For a Quick Start guide containing more code samples on Hyperspace, check out the Hyperspace Quick Start Guide.
- Check out Microsoft's GitHub Repos for Hyperspace along with the capability to log Hyperspace Issues and Feature Requests.
- For more detail on permissions in Azure Synapse Analytics Workspaces, read: Grant permissions to workspace managed identity (preview).
- For more detail on setting up access control in Azure Synapse Analytics Workspaces, read: Secure your Synapse workspace (preview)






About the author
 Ron L'Esteve is a trusted information technology thought leader and professional Author residing in Illinois. He brings over 20 years of IT experience and is well-known for his impactful books and article publications on Data & AI Architecture, Engineering, and Cloud Leadership. Ron completed his Master’s in Business Administration and Finance from Loyola University in Chicago. Ron brings deep tec
Ron L'Esteve is a trusted information technology thought leader and professional Author residing in Illinois. He brings over 20 years of IT experience and is well-known for his impactful books and article publications on Data & AI Architecture, Engineering, and Cloud Leadership. Ron completed his Master’s in Business Administration and Finance from Loyola University in Chicago. Ron brings deep tecThis author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
