Problem
Since numerous users and groups would need varying levels of access within Azure Databricks, it is worthwhile to explore and understand the various options for implementing both row-level security and other access control options within Azure Databricks. How can Databricks Administrators begin implementing these various controls and security measures within Azure Databricks?
Solution
Azure Databricks Workspace provides an interactive workspace that enables collaboration between data engineers, data scientists, machine learning engineers, data analysts and more. Since these various groups require varying levels of security, permissions and privileges, Databricks has a number of Access Controls and Row Level Security options that we will explore in this article. Note that Access Controls are typically available with the Databricks Premium Plan.
Create New User Groups
Azure Databricks contains a robust Admin Console that is quite useful to administrators that are seeing a centralized location to manage the various Access Controls and security within the Databricks console.
Within the admin console, there are a number of options from adding users, to creating groups, to managing the various access controls.
Let’s explore Row Level Security within Azure Databricks by creating a few groups in the Admin Console to test Row Level Security.
For the purpose of this demo, let’s create the two new groups listed below.

The Vendor1 group will contain member ‘Ron L’Esteve’ as group member with User permissions.

The Vendor2 group will contain member ‘Ron Tester’ as group member with User permissions.

Load Sample Data
Now that we have created the groups needed to test Row Level Security in Databricks, we will need some sample data to test.
The following code will be executed in a Python Databricks Notebook and will extract the NYC Taxi Yellow Trip Data for 2019 into a data frame.
Data = "/databricks-datasets/nyctaxi/tripdata/yellow/yellow_tripdata_2019-*"
SchemaDF = spark.read.format("csv") .option("header", "true") .option("inferSchema", "true") .load("/databricks-datasets/nyctaxi/tripdata/yellow/yellow_tripdata_2019-02.csv.gz")
nyctaxiDF = spark.read.format("csv") .option("header", "true") .schema(SchemaDF.schema) .load(Data)
Notice that we are running this notebook using my ‘Ron L’Esteve’ account which is a member of the Vendor1 Group.

After loading the nyc taxi dataset to a data frame, the following code will add a few new columns to the data frame to include 1) a new column for the year and 2) a new column for the Vendor Name which is based on a case statement referencing the Vendor ID.
from pyspark.sql.functions import *
nyctaxiDF = nyctaxiDF.withColumn('Year', year(col("tpep_pickup_datetime")))
nyctaxiDF = nyctaxiDF.withColumn("VendorName",
expr("case when VendorID = '1' then 'Vendor1' " +
"when VendorID = '2' then 'Vendor2' " +
"when VendorID = '4' then 'Vendor4' "
"else 'Unknown' end"))

Once the data frame is ready to be written to ADLS2 in parquet format, we can quickly display the dataframe to ensure that the new VendorName and Year columns are displayed as expected.
display(nyctaxiDF)

Next, the dataframe can be written to ADLS2 in delta format and partitioned by year with the following code.
(
nyctaxiDF
.write
.partitionBy("Year")
.format("delta")
.mode("overwrite")
.save("abfss://data@adl001.dfs.core.windows.net/raw/delta/nyctaxi_delta")
)

Create Delta Tables
From the delta format parquet files that were created in the previous steps, we can next create external/hive tables using the nyctaxi delta location with the following code.
spark.sql("CREATE TABLE nyctaxi USING DELTA LOCATION 'abfss://data@adl001.dfs.core.windows.net/raw/delta/nyctaxi_delta/'")

The following SQL query will confirm the distinct Vendor Names that are available in the nyctaxi external/hive table.
%sql SELECT DISTINCT(VendorName) FROM nyctaxi ORDER BY VendorName ASC

Run Queries Using Row Level Security
Databricks includes two user functions that allow users to express column- and row-level permissions dynamically in the body of a dynamic view function definition.
- current_user(): returns the current user name.
- is_member(): determines if the current user is a member of a specific Databricks group
The following SQL Query embeds the IS_MEMBER function in the query to verify whether the current user is in the specified group.
From the results, we can see that my user account is a member of the Vendor1 group since it displays ‘true’ in the column results.
%sql
SELECT
*, IS_MEMBER('Vendor1')
FROM nyctaxi

Similarly, we can also run a variation of the above query by changing the group member to Vendor2.
As expected from the results, the ‘false’ column values indicate that my user account is not a member of the Vendor2 group.
%sql
SELECT
*, IS_MEMBER('Vendor2')
FROM nyctaxi

This next query adds VendorName to the IS_MEMBER function and the results indicate either a true or false. As we can see, the Vendor1 group, which I am a member of, displays ‘true’ and Vendor2, which I am not a member of, displays ‘false’.
%sql SELECT *, IS_MEMBER(VendorName) FROM nyctaxi

Next, when we add the same IS_MEMBER (VendorName) function to the where clause of the following SQL Query, we are able to view our Row Level Security filtered results. Since my account is a member of the Vendor1 group, as expected, we can only see the filtered results for Vendor1. Additional views incorporating both row-level and column-level security can be implemented using this process which using the IS_MEMBER function.
%sql SELECT * FROM nyctaxi WHERE IS_MEMBER(VendorName)

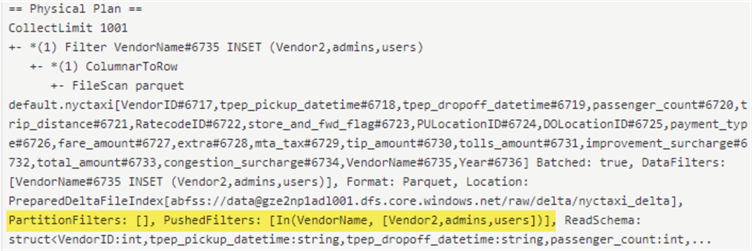
Also, from the Physical Query Plan, we can see that the partition filters utilize only the filtered groups that my account is a member of, which helps with optimizing the queries and limiting the file scans to only those which I am a member of.

Similarly, when I log into my ‘Ron Tester’ account, which is a member of the Vendor2 group and run the same SQL query, we can see that the results are filtered to the Vendor2 records only, which confirms that Row Level Security is working as expected.

%sql SELECT * FROM nyctaxi WHERE IS_MEMBER(VendorName)
Also, this Physical SQL Query execution plan also shows that the partition filers are only filtering based on the groups that this member is a part of, which further optimizes the performance of the data retrieval from the query.
Implement Cluster, Pool & Jobs Access Control
So far, we have explored Row Level Security options within Databricks. Within the Admin Console there are a variety of other Access Control options. This section explores how to implement cluster, pool, and job access control.
Once enabled, cluster access control will allow users to control who can create and manage clusters.

Prior to enabling Cluster, Pool and Job Access control, the option to allow and disable cluster creation for users is disabled.

After enabling cluster, pool and job access control, the option to disable cluster creation for users is an option.


Once create cluster permissions for the user are turned off, they will not be able to create new clusters.

The Analyst account no longer has permissions to create clusters.

For more information on cluster access control, read Enable cluster access control for your workspace
Implement Workspace Access Control
Another available access control option within Databricks is at the workspace level, which controls who can view, edit, and run notebooks in workspaces.
Workspace Access Control

Prior to enabling workspace access control, the Analyst can see all of the other users accounts and respective notebooks.

After enabling the Workspace Access Control, the Analyst can only see their workspace and the other user workspaces are no longer visible. For more detail, read more about Enabling workspace object access control.


Implement Other Access & Visibility Controls
There are a few other access and visibility controls within Databricks which add additional levels of access control.
Table Access Control
Table Access Control allows users to control who can create, select, and modify databases, tables, views and functions. Additionally, cluster will have additional security options for users to only be able to run Python and SQL commands on the tables and view which they have access to. For more information on table access control, read Enable table access control for your workspace.

Personal Access Tokens
Tokens allow users to use personal access tokens to access the Databricks REST API. For more information, read more about Managing Personal Access Tokens.

Visibility Controls
Access control by itself does not prevent users from seeing jobs, clusters, and filenames of workspaces which is where there are the following available access controls related to visibility.
- Work Space Visibility Control: For more information, read more about how to Prevent users from seeing workspace objects they do not have access to .
- Cluster Visibility Control: For more information, read more about how to Prevent users from seeing clusters they do not have access to.
- Job Visibility Control: For more information, read more about how to Prevent users from seeing jobs they do not have access to.

Next Steps
- Read more about Data Object Privileges.
- Read more about how to implement Case When Using Spark SQL.
- Read more about Cluster Access Control.
- Read more about Databricks Table Access Restrictions for BI Tools.
- Read more about Managing Groups in Azure Databricks.

Ron C. L’Esteve is a Data and AI Leader and professional Author residing in Chicago, IL, USA. He is well-known for his impactful books and article publications on Azure Data & AI Architecture, Engineering, and Leadership. Ron holds a Master of Business Administration (M.B.A.) and Master of Science in Corporate Finance (M.S.F.) from Loyola University Chicago. Ron possesses deep technical skills and experience in designing, implementing, leading, and delivering modern Azure Data & AI projects for numerous clients around the world. He is a Motorola Certified Six Sigma Green Belt, a Microsoft Global Challenger, and also holds numerous additional Microsoft, Snowflake, and Databricks professional certifications in Big Data Engineering, Artificial Intelligence, Apache Spark and Data Platform Architecture.
- MSSQLTips Awards: Champion (100+ tips) – 2023 | Author of the Year – 2020-2021 | Rookie of the Year – 2019



The RLS you outlined with IS_MEMBER() in the where clause seems strange to me. How can this be dynamic for different consumers of the data? Also, couldn’t the user just remove the WHERE clause?