Problem
We are currently using Power BI for our enterprise reporting. We import the contents of our data warehouse into the model. We have great query performance in the reports, but refreshing the model takes some time, resulting in reports with high-latency data. We considered switching to DirectQuery to have real-time data in our reports, but performance has drastically decreased. Is there an alternative solution that takes the best of the two?
Solution
Microsoft Fabric – the centralized end-to-end analytics platform introduced in 2023 and has gone in general availability since Ignite 2023 – includes the Power BI workload. In fact, if your company has been working with Power BI Premium, you already have Microsoft Fabric! Every P-SKU is also capable of running the Fabric workloads. In terms of the Power BI workload, nothing has changed. You can continue to work with Power BI just like you did before.
However, a very interesting capability has been added to Power BI when using data stored in OneLake: Direct Lake mode. With Direct Lake mode, Microsoft aims to close the gap between import mode and DirectQuery mode. In this tip, we’ll explain how Direct Lake mode works and how you can use it.
Direct Lake Mode in Power BI
As explained in the tip about OneLake, all data in the OneLake data lake is stored in the delta format. Data in a delta table is stored in a Parquet file, which is a column-based compressed format. This may sound familiar because the Vertipaq engine – the Analysis Services database that powers Power BI behind the scenes – is also a column-based format with very high compression (and in-memory). In short, when using Direct Lake mode, you swap the storage mode of the data from Vertipaq to delta tables. To improve performance, Fabric compresses the data in the Parquet files using vorder. With vorder, data is compressed even further than the default compression in Parquet. While vorder is proprietary from Microsoft, it doesn’t violate the Parquet standard. For example, Azure Databricks can still read Parquet files written with vorder. Conversely, Direct Lake still works with Parquet files with no vorder, but performance might not be as optimal.
The following diagram was taken from a Microsoft slide deck, which you can download for free at the Fabric-readiness GitHub repo.

As you can see in the diagram (“See-through Mode” is an alternative name for Direct Lake), Direct Lake combines the best of the other two import modes:
- Low Latency of DirectQuery. Once your data is in your database (or whatever source you use for your reports), you can view it in the Power BI reports. You still need to hit the refresh button, but the model “refreshes” instantly.
- Query Performance of Import Mode. When modeled correctly, you should see blazing-fast performance on your reports.
Creating a Power BI Report on a Direct Lake Model
Let’s try out Direct Lake. Suppose we have a delta table in a Fabric Lakehouse.
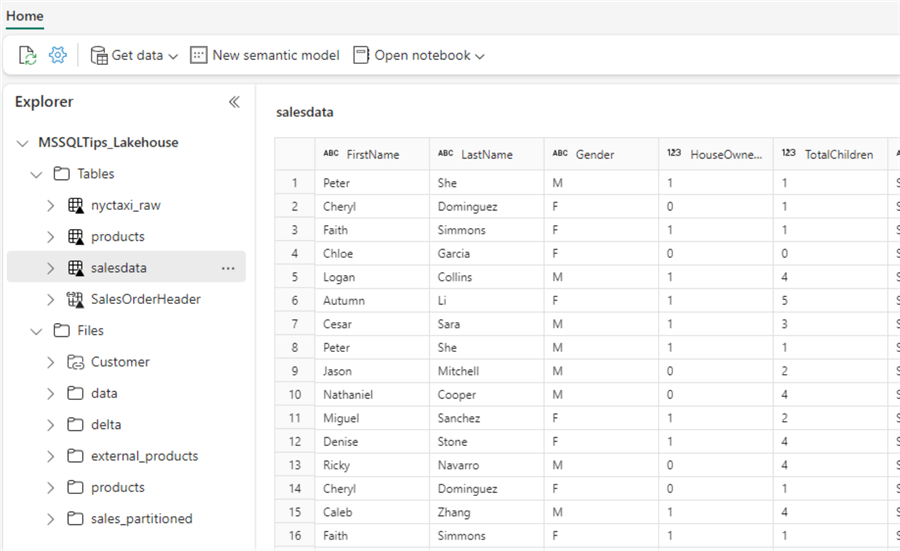
At the top, click on New semantic model to create a new model. Let’s add only one delta table to the model:
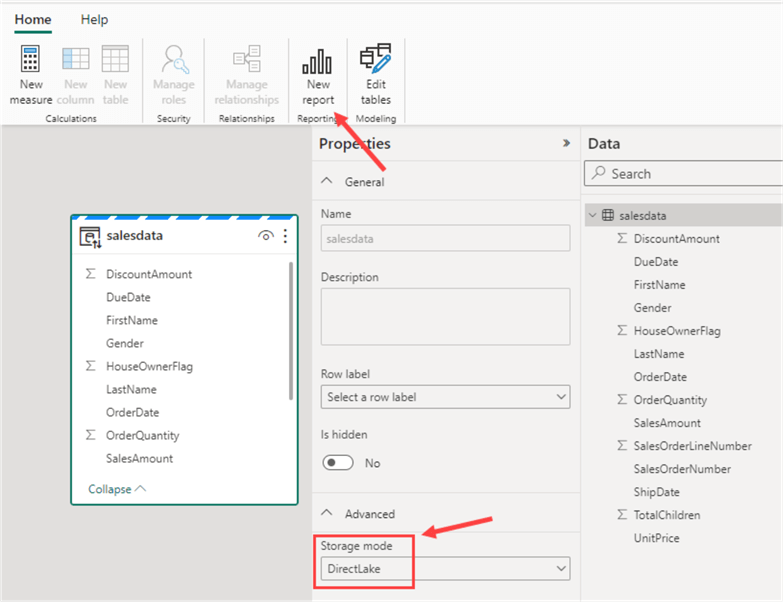
In the semantic model, we can see in the advanced properties of the table that its storage mode is Direct Lake, as shown in the red box in the image below.
In the ribbon, you can choose to create a new report. Let’s add a simple table with one column and a measure:

In a notebook, we can update the data of the delta table with a SQL statement:

The %%sql is a “magic command” that allows us to switch the programming language from the default PySpark to SparkSQL for that specific cell only. In the Power BI report, we can refresh the report:

We can see the report immediately reflects the changes in the underlying data:

If you don’t want an automatic refresh – for example, intermediate data not appearing while running data pipelines – you can disable this in the model settings.

When your ETL finishes, you can schedule or trigger a refresh of the model as we’ve always done for standard Power BI models. You can manually trigger a refresh in the browser as well:

It should finish in a couple of seconds:

Disadvantages of Direct Lake
Unfortunately, there are some downsides to using Direct Lake as well:
- Since the semantic model's source is OneLake, the capacity needs to be running to access the data (or to “refresh” it). This is only an issue if you use pay-as-you-go F-capacities, which can be paused and resumed. If you want to save money by turning off capacities once your data pipelines have finished running, you cannot run Direct Lake. If you use import mode, you can import all the data in a model (that is saved in a regular Power BI workspace). Once the refresh is complete, you can turn off all Fabric capacities, and your users can report on the import model. If you have reserved instance or Power BI Premium P-SKUs, you don’t need to worry about this. Microsoft MVP Nicky van Vroenhoven has a blog post on how Direct Lake and other storage modes work with paused capacities.
- When you query data using Direct Lake, the data is paged into memory to speed up performance. When you hit refresh on the report, this cached data will be dropped. (This is another reason to disable the automatic refresh of your Direct Lake model.) Microsoft MVP Marc Lelijveld has a great write-up on how this process works, i.e., framing.
- Suppose you have a very large delta table. When you start querying the table, data will be loaded to cache (see the previous bullet point). Not everything will be loaded at once; only the columns needed to satisfy the query. However, the data may become too big to hold in memory (depending on your capacity size). When this happens, there’s a fallback scenario where the model switches to DirectQuery to run the query, which can have considerable performance implications. You can learn more about fallback and the size limits in the documentation.
- There are several known issues and limitations, such as calculated columns that are not supported. You can find a complete list here. Some limitations may be removed in future updates.
Next Steps
- To learn more about Microsoft Fabric, check out this overview for all Fabric tips.
- At the time of writing, there’s still a free trial for Fabric, which is helpful to discover its capabilities. If a trial is not an option, you can use an F2 capacity, which is relatively cheap, especially if you pause it when you don’t need it.
- In another blog post by Marc, he talks about the data temperature of columns when using Fabric Direct Lake.

Koen Verbeeck is a seasoned business intelligence consultant with over a decade of experience with the Microsoft Data Platform. He holds several certifications, including Azure Data Engineer. He’s a prolific writer, with over 375 articles on technologies such as Microsoft Fabric, SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at various events such as PASS, SQLBits, dataMinds Connect and many others. He frequently delivers educational webinars on MSSQLTips.com. For his efforts, Koen has been awarded the Microsoft MVP data platform award for many years.
- MSSQLTips Awards:
- Leadership Award (200+ Tips) – 2021
- Author of the Year – 2014/2020/2022
- Author Contender – 2024/2025


